早些时间写过一篇《Python与SQL对比实现:处理相邻记录的时间差》
https://ask.hellobi.com/blog/Matthew112/15643
面向的是工作中常见的一个业务场景:对基于时间顺序的业务数据集进行时间序列分析。
现在我们有了集合思维的加持,面对相似的问题,又会如何处理呢?
案例一
1.场景与需求:
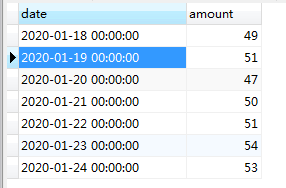
如下图,是某公司一段时间内的销售额,用列表展示与昨日的比较结果。
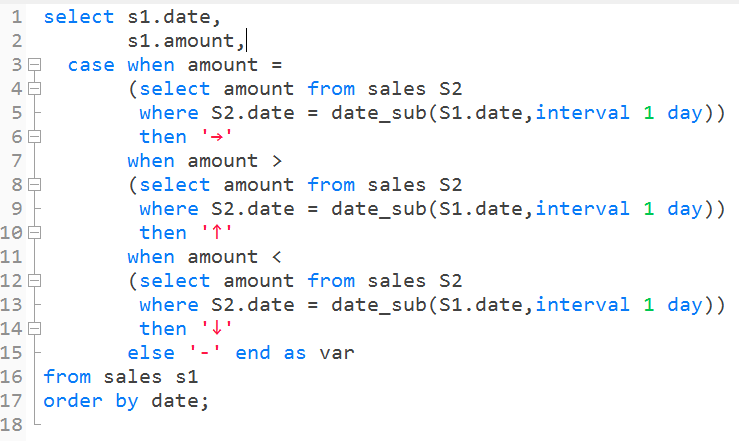
2.SQL实现与解读:
case子句中使用关联子查询,判断行间比较的四种情况(头记录没有参照)
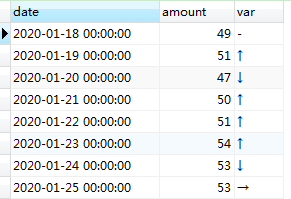
结果如下:
3.集合思维解析:
面向过程的来处理该问题的思路如下:
1.按年份递增的顺序排序。
2. 循环地将每一行与前一行的“sale”列进行比较。
面向集合来处理这个问题的思路是这样的:
在表 Sales 的基础上,再加对应存储昨天的数据的集合S2
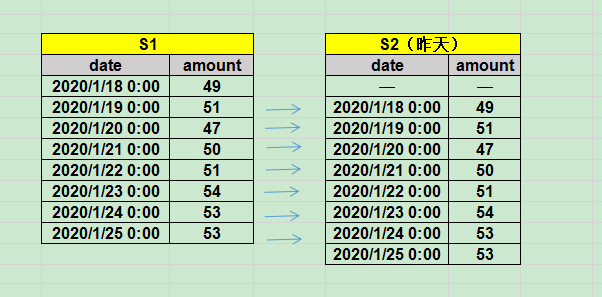
核心的处理是使用"S2.date = date_sub(S1.date,interval 1 day)"进行偏移,并辅以"order by date"进行排序。
案例二
1.场景与需求:
针对案例一的销售数据集,如果时间轴有断裂(如受当前疫情的影响,某些日期没有营业),我们该如何处理。
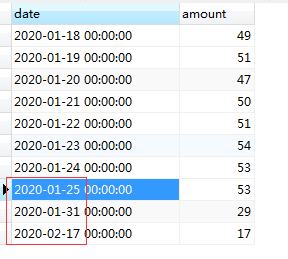
2.SQL实现与解读:
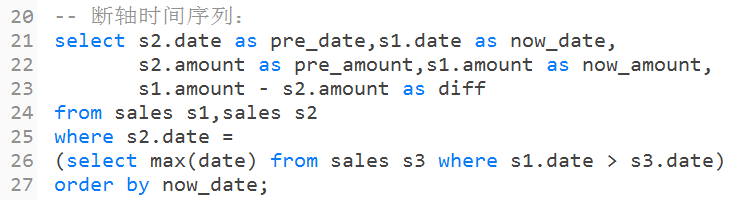
这里使用自连接的方式,不产生头记录。
结果如下:
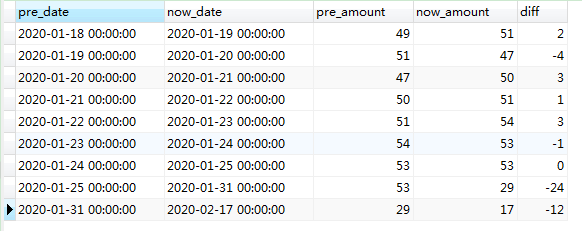
3.集合思维解析:
这里核心处理是:与当然日期相比,最近的日期,"select max(date) from sales s3 where s1.date > s3.date",集合思想与案例一相似。
个人原创,转载请联系!个人原创,转载请联系!个人原创,转载请联系!


