文字标题看起来好拗口...的说...
先来一个主题案例吧,方便大家理解:
我有一家超市,运营两年了,系统存储了所有用户的购买记录,我想要分析一下每个用户进店的时间间隔是怎样的(比如A客户第一次进店与第二次进店间隔5天,第二次进店与第三次进店间隔7天......),咋办呢?(听到这里明白了吗...)
我们用Python的pandas和SQL同时做一下这个需求,互相比较:
具体数据如下:
id是客户ID,time是进店购买的时间
先来一个SQL代码,在MySQL上运行的:

处理结果:
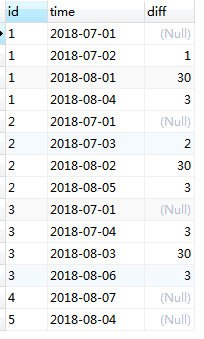
乍眼一看,SQL好强大啊,一行搞定需求,但是语言理解上略过逊色,不好读不好懂。
那么如果用Python的pandas来处理呢:
1.先导入一下包和数据源:

2.按照id和时间排序:

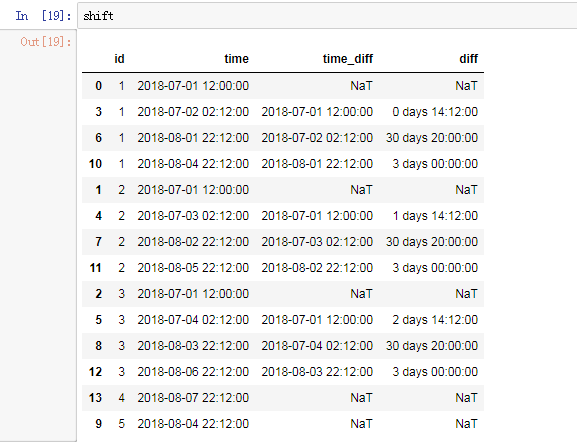
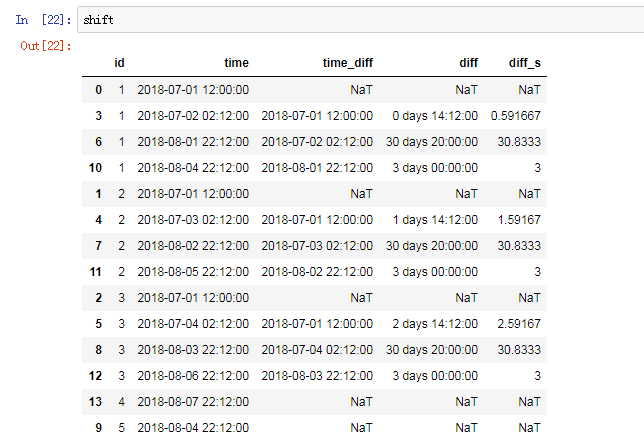
3.groupby与shift组合使用,依据id列将time列进行偏移:

偏移的结果:
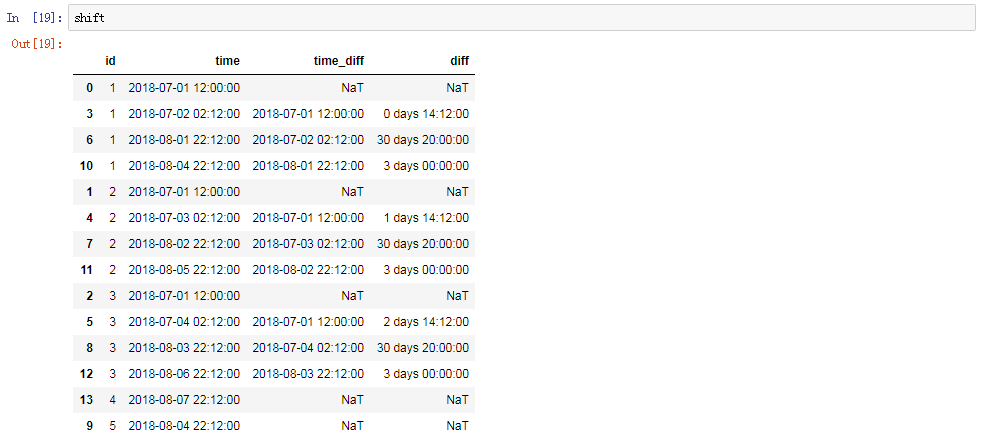
4.基于偏移后的dataframe进行两个时间列做差:

做差结果如下:
5.这里会发现结果还是不尽人意,diff列的数值不方便后期计算,那么我们自定义一个函数来搞一下:

最终结果如下:
同样是行列之间,pandas的DataFrame操作更加直观,SQL则更加简练,各有春秋!
技术没有高低之分,只是使用技术人的水平不同而已,献丑献丑!
个人原创,转载请联系!个人原创,转载请联系!个人原创,转载请联系!


