1.数据质量分析的必要性
数据质量分析师数据预处理的前提,是数据挖掘分析结论有效性和准确性的基础,其主要任务是检查原始数据中是否存在脏数据。脏数据一般是指不符合要求,以及不能直接进行相应分析的数据,在常见的数据挖掘工作中,脏数据包括:
- 缺失值
- 异常值
- 不一致的值
- 重复数据及含有特殊符号(如# ¥ *等)的数据
2.缺失值 异常值及一致性产生的原因
.缺失值产生的原因
- 有些信息暂时无法获取,或者获取信息的代价太大
- 有些信息是被遗漏的,可能是因为输入时认为不重要,忘记填写或对数据理解错误等一些人为因素而遗漏,也可能是由于数据采集设备的故障,存储介质的故障,传输媒体的故障等机械原因而丢失
- 属性值不存在。在某些情况下,缺失值并不意味的数据有错误,对一些对象来说属性值是不存在的,如一个未婚者的配偶姓名,一个儿童的固定收入状况等
.缺失值的影响
- 数据挖掘模型所表现出来的不确定性更加显著,模型中蕴含的确定性成分更难把握
- 数据挖掘建模讲丢失大量的有用信息
- 包含空值的数据会使挖掘建模过程陷入混乱,导致不可靠的输出。
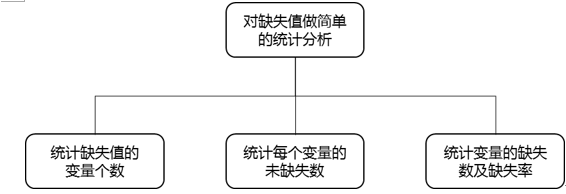
.缺失值的分析
.异常值分析
- 异常值分析是检验数据是否有录入错误以及含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除的把异常值包括进数据的计算分析过程中,对结果会带来不利影响。忽视异常值的出现,分析其产生的原因,常常成为发现问题 进而改进决策的契机
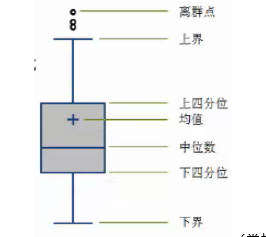
- 异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也成为离群点,异常值的分析也称为离群点的分析
- 异常值分析方法主要有:简单统计量分析,3Q原则 香型图分析
.异常值分析-简单统计分析
- 可以先做一个描述性统计分析,进而查看哪些数据是不合理的。需要的统计量主要是最大值和最小值,判断这个变量中的数据是不是超出了合理的范围,如身高的最大值为5米,则该变量的数据存在异常
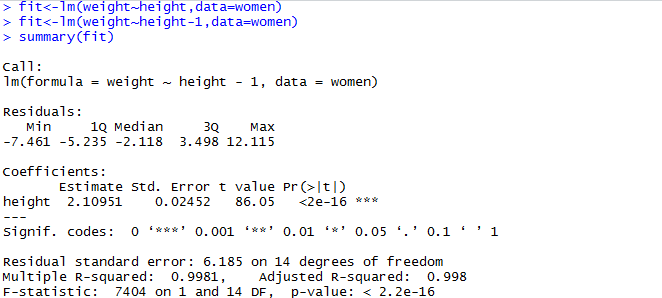
.异常值分析--3Q原则(这里的标志没法输,各位熟悉正确的写法就可)
- 如果数据服从正太分布,在3Q原则下,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。在正太分布的假设下,距离平均值3Q之外的值出现的概率为
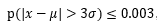 ,属于极个别的小概率事件
,属于极个别的小概率事件 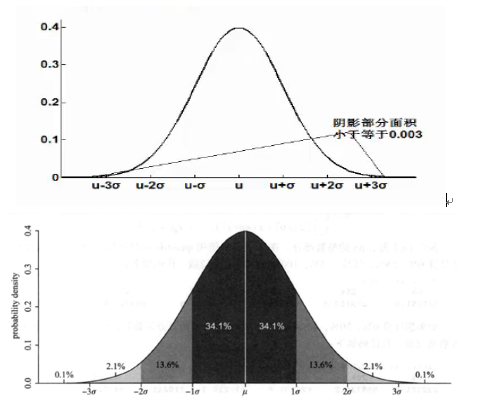
当指标x属于(U-Q,u+Q)时,对应的概率(和X轴间的面积)是 2*24.13%=68.26%
当指标x属于(u-2Q,u+2Q)时,对应的概率(和x轴间的面积)是68.26+2*13.6%=95.46%
当指标x属于(u-3Q,u+3Q)时,对应的 概率(和X轴的面积)是95.46%+2*2.14%=99.74%
而处于(-无穷,u-3Q)和(u+3Q,+无穷)时,样本的概率为0.26%,这是一个小概率事件,我们称其为3倍标准差下的异常点,并分别把U-3Q和u+3Q称为3倍标准差下的下限(LCL)和上限(UCL)
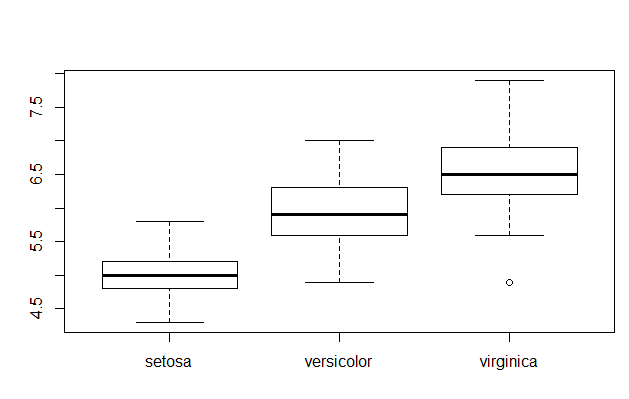
.异常值分析--箱线图分析
- 箱线图依据实际数据绘制,不需要事间假定数据服从特定的分布形式,没有对数据做任何限制性要求,它只是真实直观的表现数据分布的本来面貌。另一方面,箱线图判断异常值的标准以四分位数和四分位距为基础,四分位数具有一定的鲁棒性:多达25%的数据可以变的任意远而不会很大的扰动四分位数,所以异常值不能对这个标准施加影响,箱线图识别异常值的结果比较客观。由此可见,箱线图在识别异常值方面有一定的优越性。