学习支持向量机确实是有点吃力,因为网上的资料篇幅都比较长在说支持向量机前我先给各位介绍4个关键的概念,尽量用通俗易懂的语言给大家介绍;
分离超平面:因为我们在处理分类问题的时候往往需要有个给我们参考的决策边界,就好像国界一样,你出生在哪里就是哪里的人,在中国这边出生的人自当都是中国人,在朝鲜出生的人自然都是朝鲜人,这种决策边界将两类事物分离,而线性的决策边界就是分离超平面;
最大边缘超平面:分离超平面可以有很多个,为什么是好多个呢,应为两点之间可以有多个平面被分,那到底那个平面才是是最优的呢?SVM的作法是找一个最中间的,换句话来说,就是这个平面要尽量和两边保持最大的距离,留有足够的距离,减少泛化误差,保证稳健性,就拿公路来说吧,它有两个方向的车道,区分两个方向车道永远是中间那条线。
软边缘:在线性无可分的情况下我们就要考虑使用一下软边缘,因为分类难免会出现错误的分类,毕竟没有那么完美的算法嘛,就像是中国国境里面肯定会有一些外国人嘛,外国国境肯定也是会有一部分中国人嘛,除非是数据问题,现实生活中很难使用一个平面去完全的分离两个类别。软边缘是允许个别样本跑到其他的类别的决策决策边界内上去,要使用参数来权衡两端,一方面要保持最大边缘的分离,另一个要使这种破例不能太离谱;这种参数就是对错误分类的惩罚程度C.
核函数:为了解决完全无误分离的问题,SVM还提出了一个思路,就是将原始数据进行映射到高维空间中去,这样在低维空间无法划分的点映射到高维空间后变得可以容易划分,就好比一条线无法划分的数据,那么一个平面就比较容易。就好比像下面的这样的数据,要想通过线性的人为划分的话就有点难;所以就得需要引入核函数,但核函数是一把双刃剑,因为如果维度过高的话就有可能造成过度拟合,也就是说拟合效果只适合样本,应用到现实就不行了,核函数本质上和相似度类似;

所以,要想完全解决分类问题,那么选择合适的核函数和软边缘参数C至关重要;
常用的核函数有如下种类(当然还有自己自定义的,不局限以下种类):
Linear:使用它的话就成为线性向量机,效果基本等价于Logistic回归。
polynomial:多项式核函数,适用于图像处理问题。
Radial basis:高斯核函数,最流行易用的选择。参数包括了sigma,其值若设置过小,会有过度拟合出现。 sigmoid:反曲核函数,多用于神经网络的激活函数。
下面我们进入实例吧,首先是我们先用R语言构造一些测试数据,是线性模型无法划分的数据;
R代码如下
x1 <- seq(0,pi,length.out)#构造一个0到PI(圆周率)区间的100个序列;
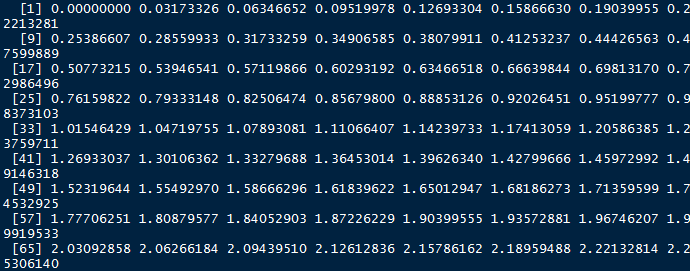
y1 <- sin(x) + 0.1*rnorm(100)#构造一个sin(x)的三角函数值,并加上100个标准化随机数和的序列:
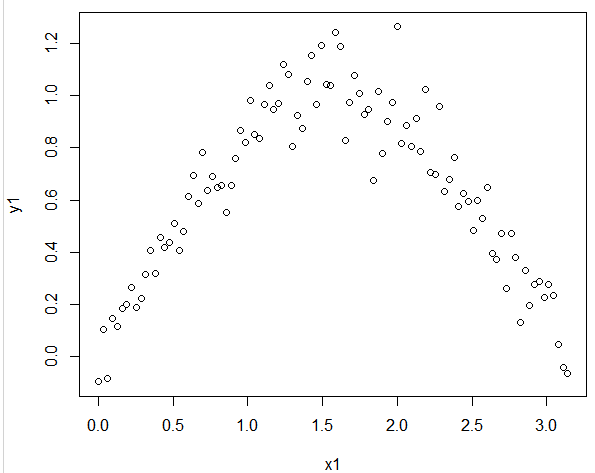
在用PLOT函数看看他们两个组成的分布如何
plot(x1,y1)
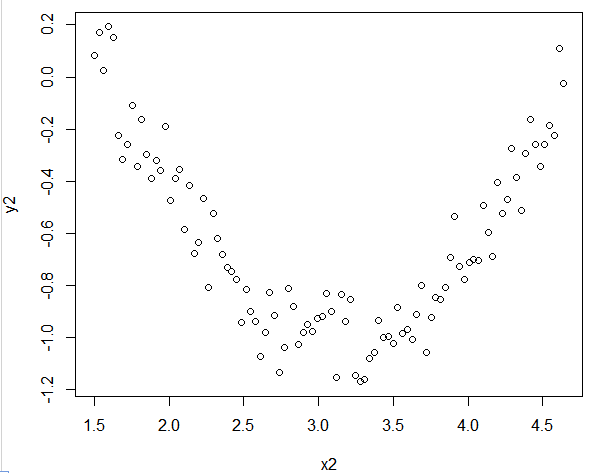
重复上面的动作,这里就不加以说明了;
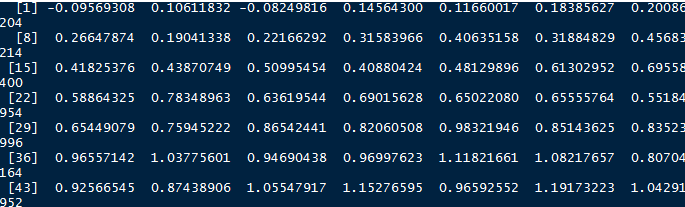
x2 <- 1.5+ seq(0,pi,length.out=100)
y2 <- cos(x2) + 0.1*rnorm(100)
plot(x2,y2)
在将它们合并成一个三列的数据框,前一百个为Y=1的类,后一百
R代码如何下
data <- data.frame(c(x1,x2),c(y1,y2),c(rep(1, 100), rep(-1, 100)))
names(data) <- c('x1','x2','y')
data$y <- factor(data$y)
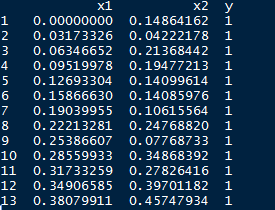
data
接下来我们将使用R包kernlab中的KSVM函数,
R代码如下
library( kernlab)
model1 <- ksvm(y~.,data=data,kernel='vanilladot',C=0.1)
plot(model1,data=data)
model1
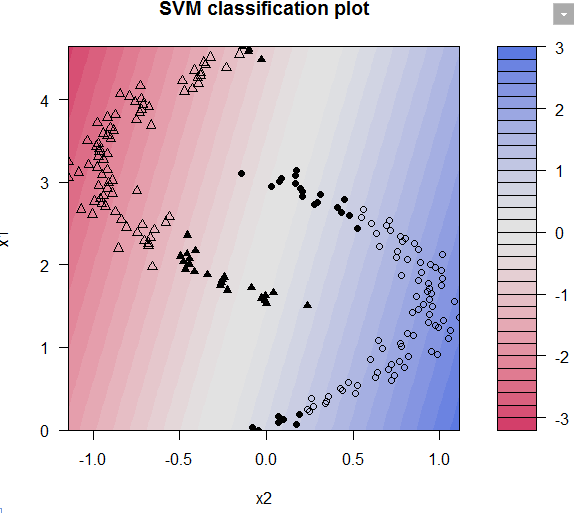
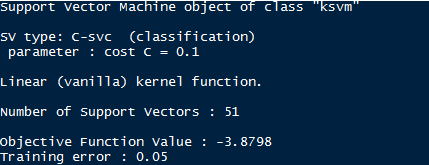
从上图和模型结果来看误差率为5%,还未完全分类;这时候我们加大惩罚函数,使得决策边缘缩窄,
R代码如下
model2 <- ksvm(y~.,data=data,kernel='vanilladot',C=100)
plot(model2,data=data)
model2
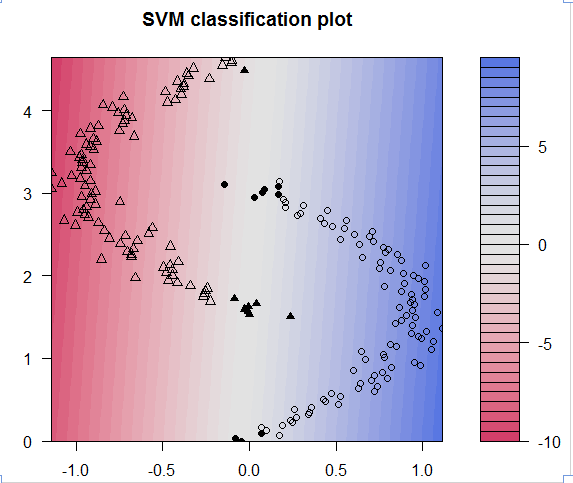
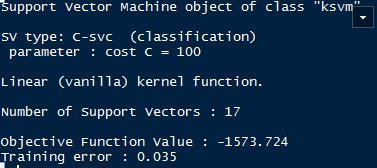
这时候误差率减少到了3.5%,效果不算很明显了,这时候我们使用核函数,高斯核函数
R代码如下
model3 <- ksvm(y~.,data=data,kernel='rbfdot')
plot(model3,data=data)
model3
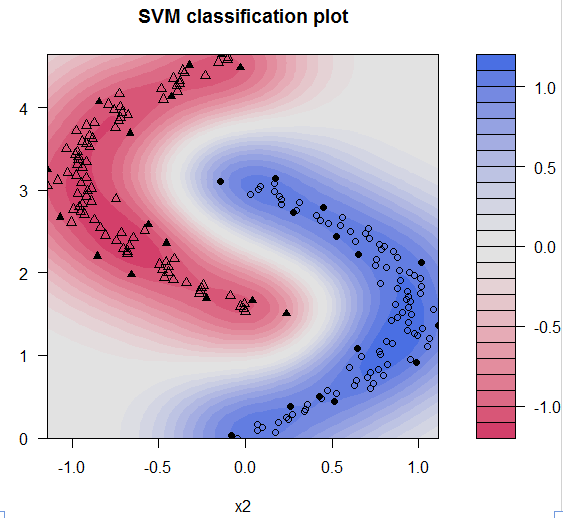
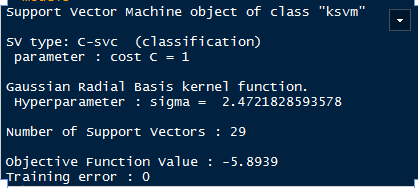
很神奇,误差率降到了为0,数据被完全分类;
本来想写个例子但是还是参考网上的一个例子,并且给了自己的说明,如果有不对的地方大家可以指正,一起交流
参考资料:
http://www.pythontip.com/acm/post/674


