



本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。
10 个评论
好棒 多多分享
好文
公众号也同步了
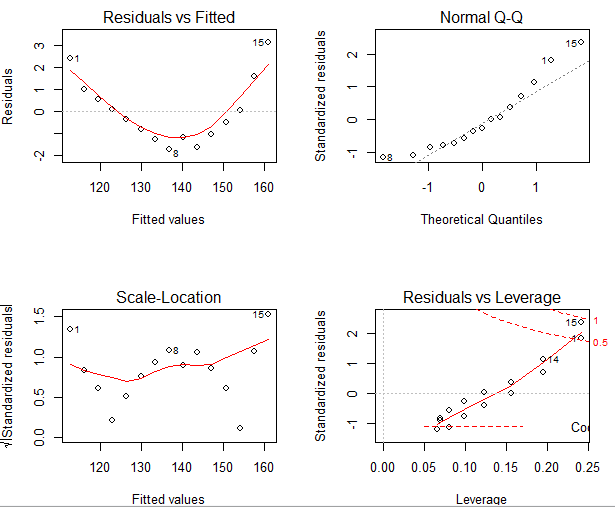
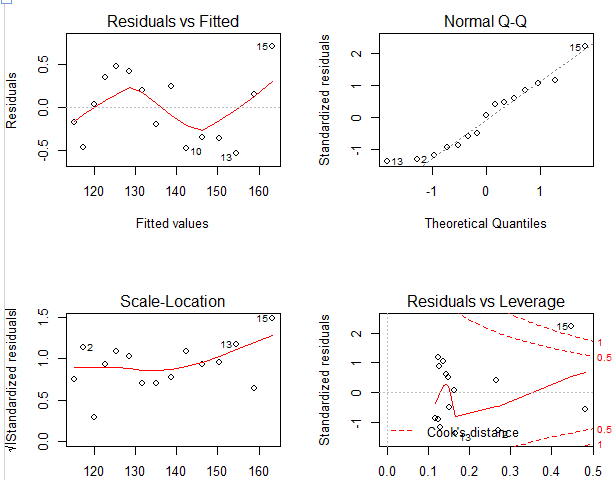
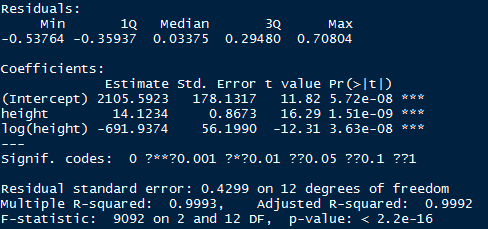
左上:代表的残差值和拟合值的拟合图,如果模型的因变量和自变量是线性相关的话,残差值和拟合值是没有任何关系的,他们的分布应该是也是在0左右随机分布,但是从结果上看,是一个曲线关系,这就有可能需要我们家一项非线性项进去了。
因变量与自变量的相关关系(线性或非线性),模型出来后的残差值和拟合值的关系,以上两种关系直接是没有必然联系的!残差值和拟合值呈曲线关系,不能说明原方程一定要加入非线性项!个人观点,仅供交流。
因变量与自变量的相关关系(线性或非线性),模型出来后的残差值和拟合值的关系,以上两种关系直接是没有必然联系的!残差值和拟合值呈曲线关系,不能说明原方程一定要加入非线性项!个人观点,仅供交流。
因变量和自变量和关系线性或者非线性会影响到他们残差的分布,从而间接的影响了残差值和拟合的分布,这些是可证的,仅供参考
probit和logit model 也可以这样检验,结果怎么解释呢?