通过几天的对数据挖掘的阅读,认真的学习了一下分类的一些常用的算法,例如决策树的ID3算法和朴素贝叶斯算法,
这两个算法都是用来对数据进行分类的,今天我给大家介绍一下朴素贝叶斯分类算法,尽量用通俗易懂的语言说给大家;
我们为什么要对数据进行分类呢?因为分类是一种重要的的数据形式,它是刻画重要数据类的模型,这种分类分析可以帮助我们更好地全面认识理解数据
一般分类方法都需要分两步走,第一个步是根据现有的数据进行分类器的 创建,也就是我们所说的分类模型,这个阶段在机器学习里面是叫学习过程,第二步就是我们确定这个模型的准确率如何,假定一个分类器的准确率很差你也肯定不会用,如果很好你才会采用;
在介绍朴素贝叶斯算法前我先简单的介绍一下要知道的概念;概率什么是概率,简单的来说就是一个不确定的事件发生可能性的大小,如,如果明天下雨的概率是1的话,这就说明了明天肯定会下雨,如果概率为0的话,也就说明了明天肯定不会下雨,如果说概率是0.5的话,也就是说明了明天下雨和不下与的概率的可能性是一样大;我在说说一下条件概率,顾名思义,就是在一定条件下的事件发生概率,在概率书写中是P(A|B),意思就是在B发生情况下A发生的可能性的大小,
朴素贝叶斯算法就是根据概率进行判断分类,它概括的来说就是它这个归属在哪一类的概率大就是哪一类;例如你看到今天是个万里无云的天气,你肯定要认为今天是晴天,因为晴天的概率大嘛,当然也不排除会下雨,但是在没有别的信息情况下,我们会认为今天是晴天,因为天空出现了万里无云的情况在我们的脑子印象里大部分是是大晴天嘛,这个思想也是朴素贝叶斯的思想基础;
为什么要叫朴素贝叶斯算法呢,因为这个算法是以贝叶斯定理为基础的算法,故称为贝叶斯分类,具体就不说太多概念了,我直接用两个例子带大家认识一下一下这个算法,简单明了,不过在举栗子前必须的提前说明一下这个公式,p(H|X)=P(X|H)P(H)/P(X);P((H|X)是它的后验概率,后验概率等于X在H的情况下的概率乘于H发生的概率在除于发生X的概率;
此数据来自百度,如有雷同不是巧合;
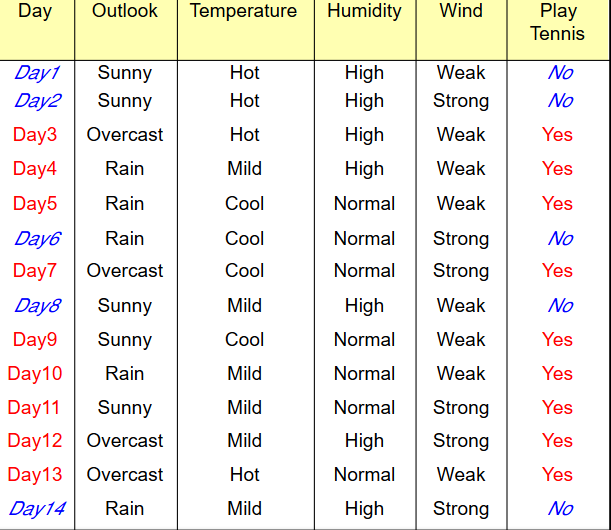
这时候我们这些数据也叫训练数据,我们要用这些数据建起一个朴素贝叶斯分类预测模型,数据样本使用的属性为OUTLOOK,TEMPERATURE,HUMIDITY和WIND去描述,类标号属性为PLAY_TENNIS就是两个类,一个是YES,一个NO,就是我们要对对象进行分为那个类别就叫类标号,自动忽略,这不是重点,在这里我设定一下H1对应类PLAY_TENNIS='YES',而H2对应是类PALY_TENNIS='NO',
这时候有一个需要我们去分类的样本为
X=(OUTLOOK='RAIN',TEMPERATURE='HOT',HUMIDITY='NORMAL',WIDN='STRONG'),这时候我们需要我们需要计算P(X|H)P(H),这时候总共有14条记录,其中,PLAY_TENNIS='YES'为9条,PLAY_TENNIS='NO'为5条,
所以P(PLAY_TENNIS='YES')=9/14=0.643,P(PLAY_TENNIS='NO')=5/14=0.357,也就是说在不知道其他信息情况下PLAY_TENNIS='yes'的概率为0.643,另外一个出现的概率为0.357;
这时候我们在计算一下类别属性情况下各个维度的概率,从数据中我们可以知道当PLAY_TENNIS=‘YES’情况下总共有9条记录,OUTLOOK='RAIN'总共发生了3次,在PLAY_TENNIS='NO'的清下总共有5条记录:OUTLOOK='RAIN'发生了2次
P(OUTLOOK='RAIN'|PLAY_TENNIS='YES')=3/9=0.333;
P(OUTLOOK='RAIN'|PLAY_TENNIS='NO')=2/5=0.4
以此类推
P(TEMPERATURE='HOT'|PLAY_TENNIS='YES')=2/9=0.222
P(TEMPERATURE='HOT'|PLAY_TENNIS='NO')=2/5=0.4
P(HUMIDITY='NORMAL'|PLAY_TENNIS='YES')=6/9=0.666
P(HUMIDITY='NORMAL'|PLAY_TENNIS='NO')=0.2
P(WIND='STRONG'|PLAY_TENNIS='YES')=3/9=0.333
P(WIND='STRONG'|PLAY_TENNIS='NO')=3/5=0.6
使用以上的概率我们可以的得到
P(X|PLAY_TENNIS='YES')=P(OUTLOOK='RAIN'|PLAY_TENNIS='YES')*P(TEMPERATURE='HOT'|PLAY_TENNIS='YES')*P(HUMIDITY='NORMAL'|PLAY_TENNIS='YES')*P(WIND='STRONG'|PLAY_TENNIS='YES')=0.333*0.222*0.666*0.333=0.0164;
P(X|PLAY_TENNIS='NO')=P(OUTLOOK='RAIN'|PLAY_TENNIS='NO')*P(TEMPERATURE='HOT'|PLAY_TENNIS='NO')*P(HUMIDITY='NORMAL'|PLAY_TENNIS='NO')*P(WIND='STRONG'|PLAY_TENNIS='NO')==0.4*0.4*0.2*0.6=0.0192;
P(PLAY_TENNIS='YES|X)=P(X|PLAY_TENNIS='YES')P(PLAY_TENNIS='YES')=0.0164*0.643=0.010;
P(PLAY_TENNIS='NO'|X)=P(X|PLAY_TENNIS='NO')P(PLAY_TENNIS='NO')=0.0192*0.357=0.0069;
从上面的结果上来看的话我们可以相信这条记录的PLAY_TENNIS的类属性应该是YES;
上面就是朴素贝叶斯建模的过程,不过为了让大家更明白这个过程,我在写一个例子的过程,简单大概明了的认识这个过程;这次的数据源来自一本书--机器学习概念与技术;过程我就不太详细描述了,
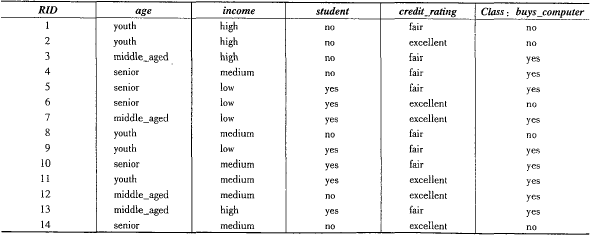
我们选择AGE,INCOME,STUDENT和CREDIT_RATING,这时候我们设H1类标号属性是BUYS_COMPUTER=YES,H2的类标号属性为BUYS_COMPUTER=NO;
这时候我们需要对这条记录进行归类:X=(AGE=YONTH,INCOME=MEDIUM,STUDENT==YES,CREDIT_RATING=FAIR)
记录一样是十四条,计算每个类的先验概率;
P(BUSY_COMPUTER=YES)=9/14=0.643;
P(BUSY_COMPUTER=NO)=5/14=0.357;
然后计算各个维度的条件概率
P(AGE=YOUTH|BUYS_COMPUTER=YES)=3/9
P(AGE=YOUTH|BUYS_COMPUTER=NO)=3/5
P(INCOME=MEDIUM|BUYS_COMPUTER='YES')=4/9=0.444
P(INCOME=DEDIUM|BUYS_COMPUTER='NO')=2/5
P(STUDENT=YES|BUYS_COMPUTER=YES)=6/9=0.667
P(STUDENT=YES|BUYS_COMPUTER=NO)=1/5=0.2
P(CREDIT_RATING=FAIR|BUYS_COMPUTER=YES)=6/9=0.667;
P(CREDIT_PATING=FAIR|BUYS_COMPUTER=NO)=2/5=0.400
从上面可以得知
P(X|BUYS_COMPUTER=YES)=0.222*0.444*0.667*0.667=0.044
P(X|BUYS_COMPUTER=NO)=0.6*0.4*0.2*0.4=0.019
因此
P(BUYS_COMPUTER=YES|X)=P(X|BUYS_COMPUTER=YES)*P(BUYS_COMPUTER=YES)=0.044*0.643=0.028;
P(BUYS_COMPUTER=NO|X)=P(X|BUYS_COMPUTER=NO)*P(BUYS_COMPUTER=NO)=0.019*0.357=0.007;
所以我们认为这条记录类别属性BUYS_COMPUTER=YES

