记得写毕业论文那会儿,经常会为缺语料发愁。由于大多数 NLP 问题都是有监督问题,因此往往我们缺的不是算法,而是标注好的语料。这种问题在中文语料上更是明显。今天就和大家分享一些中文 NLP 领域,构建语料的一些经验和技巧,虽然未必看了此文就能彻底解决语料的问题,但是或多或少会有些启发。
首先先来分享一些自己平时经常寻找语料的一些渠道,这些渠道无非是一些在线公开的语料。
常见的语料获取渠道:
- 数据科学竞赛平台,天池,科赛,CCF
- 互联网企业自己举办的比赛,如百度,搜狐,知乎,腾讯 这些企业都是土豪,通常会花费巨额的资金标注语料
- Github 很多模型里面会自带部分语料
有监督学习一个缺点就是,很难实现领域迁移,因此上述语料往往与我们需要解决的 NLP 问题不太一致,因此我们还得想办法去变一些语料出来。
通过API或开源模型标注语料
比如我们需要训练一个命名实体识别模型,就可以借助在 bosonnlp 或者 hanlp、foolnltk 上去标注语料
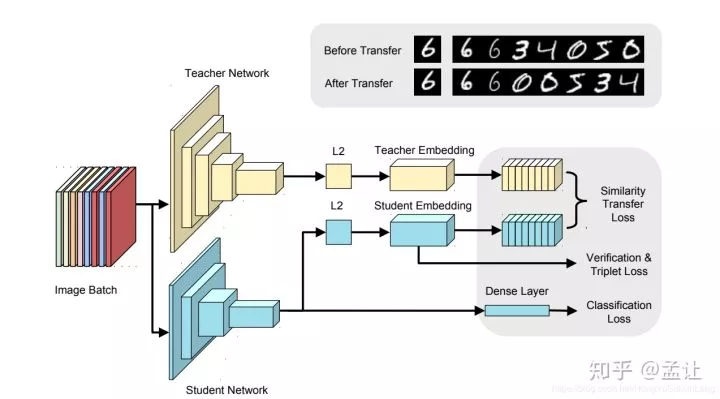
GFD
我们可以将别人训练的模型看做是teacher, 然后用API标注的语料自己训练的模型看做是Student, 虽然结果不能达到和原来模型一致的效果,但是也不至于差太多,这种方式在初期能够帮助我们快速的推进项目,看到项目的效果后,后期再想办法优化迭代
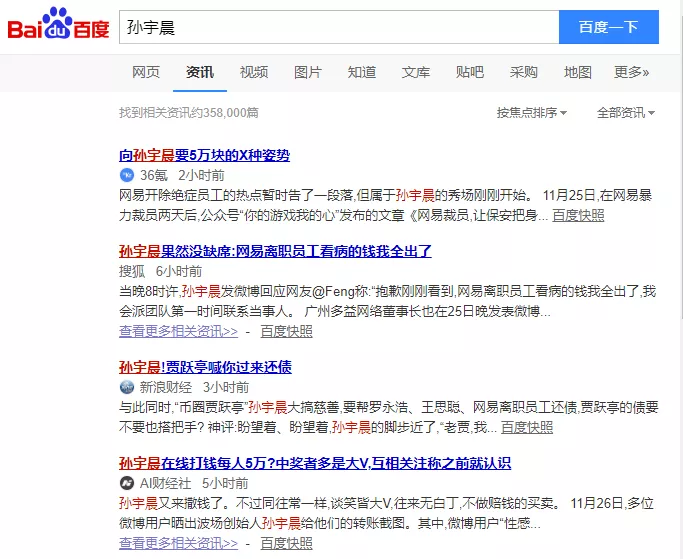
通过搜索引擎收集标注数据
假设我们需要做一个NER模型,其中一类实体是人名,可能我们想到的是从网上下载一批新闻,然后标出其中的人名,但是,这样做有一个问题,一篇几千字的新闻往往只有几个人名,而我们只需要出现了人名的那部分句子,并不需要其他部分。如果直接在整篇文本上标注效率十分低。其实,我们可以转换一下思路,找一份中文人名词库,然后放到百度中搜索,百度摘要返回的大部分结果基本是我们想要的语料。通过爬虫把摘要爬下来,自己再过滤下就好啦。
改造已有语料
有的时候,一些语料和我们的需要解决的任务相似,但又完全不一样,这时候我们可以尝试利用其他任务的语料来构建出想要的语料。就拿百度2019信息抽取比赛来说吧,该比赛的任务是从
"text": "《逐风行》是百度文学旗下纵横中文网签约作家清水秋风创作的一部东方玄幻小说,小说已于2014-04-28正式发布"
这样的句子中抽出实体和关系三元组
"spo_list": [{"predicate": "连载网站", "object_type": "网站", "subject_type": "网络小说", "object": "纵横中文网", "subject": "逐风行"}, {"predicate": "作者", "object_type": "人物", "subject_type": "图书作品", "object": "清水秋风", "subject": "逐风行"}]
百度总共提供了大概17万的标注数据,而且数据标注质量颇高。训练数据被标注为以下格式:
{"text": "《逐风行》是百度文学旗下纵横中文网签约作家清水秋风创作的一部东方玄幻小说,小说已于2014-04-28正式发布", "spo_list": [{"predicate": "连载网站", "object_type": "网站", "subject_type": "网络小说", "object": "纵横中文网", "subject": "逐风行"}, {"predicate": "作者", "object_type": "人物", "subject_type": "图书作品", "object": "清水秋风", "subject": "逐风行"}]
由该数据我们可以构造什么数据呢?
命名实体识别语料
由于语料中的每个实体都标注了实体类别,所以可以通过实体类别,构造出命名实体识别任务的语料,这17万数据集,提供了国家、城市、影视作品、人物、地点、企业、图书等10几个类别的实体;
开放关系抽取语料
虽然该数据集是面向封闭域关系抽取的数据集,其实改造一下,也能用于句子级别的开放域关系抽取任务中,比如我们可以构建一个基于序列标注的关系和实体联合抽取模型,简单的说就是给定(s,p,o)三元组和text,从中抽取一个代表关系的动宾短语或名词性短语来。比如从《逐风行》是百度文学旗下纵横中文网签约作家清水秋风创作的一部东方玄幻小说,小说已于2014-04-28正式发这句话抽取(清水秋风,创作,《逐风行》)这样的关系三元组。
很多公开的语料都可以采用类似的做法,这里就抛砖引玉一下,不一一介绍了。
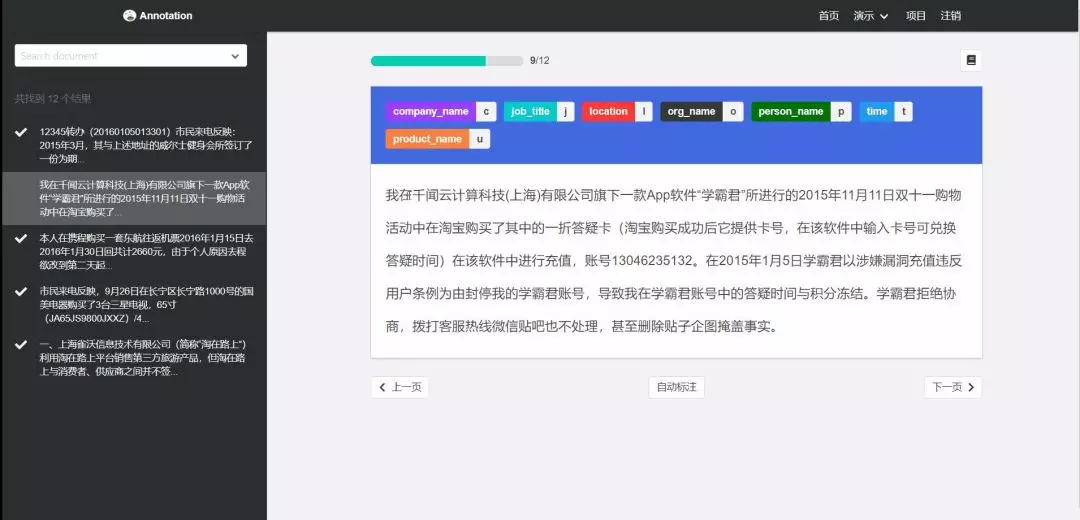
自动标注工具
工欲善其事,必先利其器 ,标注工具能够大大提高标注效率,标注工具通过提供方便的快捷键和交互方式,让我们在相同时间,标注更多的数据。同时,还可以在标注工具中嵌入一些AI辅助标注的能力,实现机器自动标注,而我们只需要修改和删除小部分的错误标注样本,进一步提高效率。
主动学习标注
在机器学习任务中,由于数据标注代价高昂,我们也面临着如何以最少量的样本,来获得最有效学习模型的问题。如果能够从任务出发,通过对任务的理解来制定标准,挑选最重要的样本,使其最有助于模型的学习过程,将大大减少标注的成本。 关于主动学习,南京航空航天大学的研究者提出并开源了一个用于主动学习的Python工具包ALiPy 。
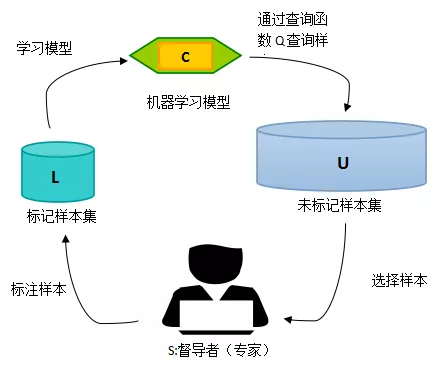
弱监督的数据标注
远程监督和弱监督学习也是NLP领域重要的研究方向,知识图谱远程监督,snorkel, 基于规则标注
拿出项目的效果,向公司申请资源想好项目的落地场景和价值,画好饼,让老板买单吧
扫码下图关注我们不会让你失望!

