前文传送门:
从零开始学自然语言处理(25)—— 通用的Encoder-Decoder模型框架
在上一次面试失利后,我回来仔细研究了一下Attention机制,研究完我不禁感悟,这机制真的厉害啊!因为我之前面试被问到的Encoder - Decoder框架中有个瓶颈是编码的结果以固定长度的中间向量表示,这导致较长的序列编码后很多信息被稀释了,导致解码时效果不佳。当时只记得有个Attention,但是不了解他的原理,所以上次面试没过:从零开始学自然语言处理(25)—— 通用的Encoder-Decoder模型框架
NLP中的Attention机制是在论文《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》被提出的,有兴趣的朋友可以去阅读论文:https://arxiv.org/pdf/1409.0473.pdf
上次面试问到的Encoder - Decoder框架如下图所示:
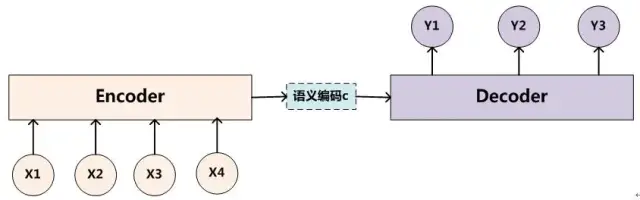
而加入Attention机制之后,Encoder - Decoder框架可以改为如下所示:
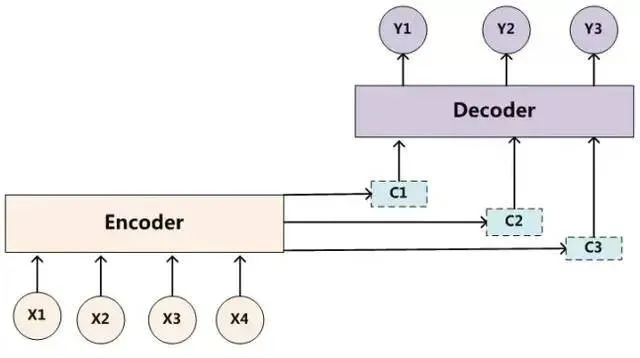
大家应该注意到上下两张图的主要区别在于中间向量C从固定不变的一个变成了不同的多个,在解码每个序列字符串时使用不同的Ci。
例如我们在翻译 “Through the woods, we reached the bank of the river.” 时,我们会翻译成 “穿过树林,我们到达了河岸。”,当我们在翻译 “bank” 这个词时,应该将注意力集中在 “bank ”上,同时也应该考虑上下文,例如“river”,这样我们才会将“bank”翻译为“河岸”,而不是“银行”,这符合我们人类的认知,又例如,我们翻译“woods”时,会重点关注“woods”和“through”等。所以我们每次在翻译(解码)一个词时,重点关注的内容是不同的,那如何表示在Decoder阶段解码某个输出(翻译某个词)时对原始输入关注的重点不同呢?
这个问题在上述的论文中得到了解决,论文提出了以下结构的模型:
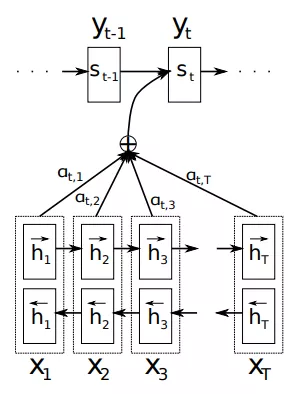
这里使用了双层的RNN结构,关于RNN和双层RNN可以参考之前的文章:
从零开始学自然语言处理(十九)—— 不可不知的循环神经网络(RNN)
从零开始学自然语言处理(22)—— 效果震撼的Bi-LSTM
首先,在Encoder阶段,输入的是 X 序列,X=(X1,X2,X3,...,XT),经过一个双向RNN结构编码,得到隐藏层每个单元的向量hi ,然后使用如下的公式计算得到解码不同单词时用到的Ci:
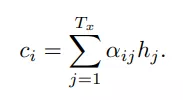
大家应该发现了,这里的C不再是传统Encoder-Decoder框架中那个固定的C了,而是根据解码不同 y 有着不同的Ci !理解这一点就理解了Attention的精髓了!
你可能会问,这里的αij是如何计算的?这里的 αij 类似权重的意思,如上图所示,在解码yt时,会综合考虑αt1,αt2,...,αtT作为对不同输入 Xi 的关注程度不同,αij计算公式如下:
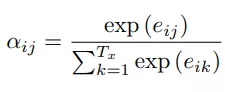
所以αij其实是 eij经过softmax之后的结果,那问题变为eij是如何计算的了!eij的计算公式如下:

这里的a是一个对齐模型(Alignment model),实际上是一个前馈神经网络,这里的“对齐”你可以理解为是一种相似度的计算,计算的是当前解码内容的上一个隐藏状态s(i-1)和当前hj的关系,相当于将每个编码输入和当前输出进行匹配,从而得到权重。这样就完成了对Encoder-Decoder框架加入Attention机制,解决了一开始的问题!
这个Attention面试问题也就迎刃而解了~

扫码下图关注我们不会让你失望!

