
作者:石塔西 爱好机器学习算法,以及军事和历史
知乎ID:https://www.zhihu.com/people/si-ta-xi
前言
《Deep Neural Networks for YouTube Recommendations》这篇论文是介绍深度学习在推荐系统领域应用的经典之作。可以想见,Youtube的推荐系统所要面临的问题:
而正如文中所说,Youtube与Google的其他业务线,正在经历一次技术变革,即将深度学习技术作为一种通用解决方案,来解决所有机器学习问题。因此,看Youtube是如何在运用深度学习的过程中,解决以上这些难题,对于搭建我们自己的推荐系统,具有极大的借鉴意义。
我一年前已经读过这篇文章。随着自己在推荐系统领域经验的积累,最近带着自己的感悟、问题再读此文,又有了新的收获,特分享如下:
整体框架
与几乎所有推荐系统一样,Youtube的推荐系统也分为“召回”与“排序”两个子系统。
 Youtube推荐系统整体架构
Youtube推荐系统整体架构
Youtube在这两个子系统中,都使用了深度神经网络,结构上并没有太大的不同,主要是体现在所使用的特征上。
召回网络
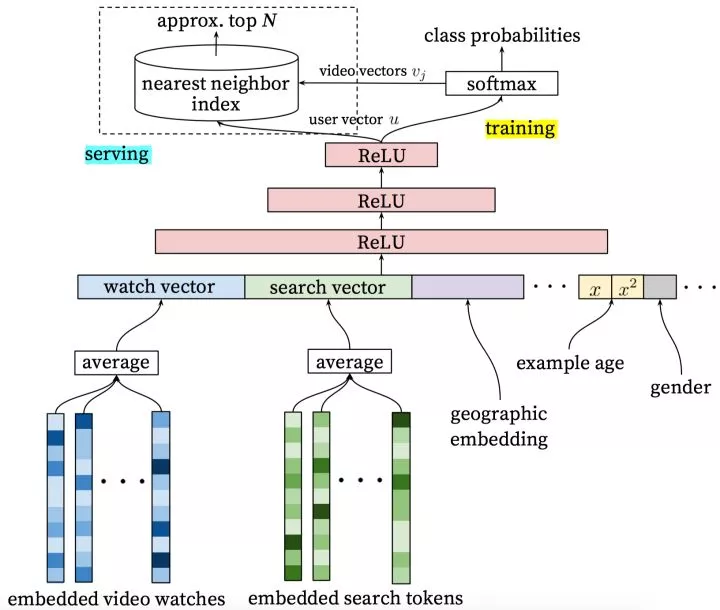 召回网络
召回网络
Youtube将“召回”过程建模成一个拥有海量类别的多分类问题,类别总数就是视频库中的视频总数,数量在百万级别。
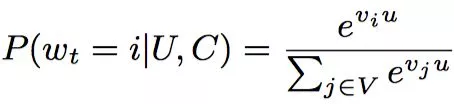 召回使用的softmax公式
召回使用的softmax公式
上式是一个标准的softmax公式,表示用户U在上下文C的情况下,观看第i个视频的概率
V是视频库中所有视频的集合,数量在百万级别
代表第i个视频的向量,是需要优化的变量,通过训练才得到
u是由“用户特征”与“上下文特征”拼接得到的特征向量,后续会讲到,用户历史上看过的视频的向量也是u的组成部分
接下来,需要解决的问题:
如何构建视频向量
这个问题比较简单,就是构建一个[|V|, k]的embedding矩阵, 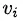 就是这个矩阵的第i行。整个embedding矩阵属于优化变量,通过训练得到。
就是这个矩阵的第i行。整个embedding矩阵属于优化变量,通过训练得到。
看似简单的问题,一旦牵扯上海量数据,也变得不那么简单。如果视频库中的视频太多,单机内存装不下怎么办?
本文中介绍,Youtube的做法是剔除一些“点击频率太低”的视频,减少候选集合
阿里的Deep Interest Network一文中介绍,阿里的XDL深度学习平台,有专门的Distributed Embedding Layer,超大的embedding矩阵可以分散到集群,而DNN的训练可以单机完成。
没有XDL怎么办?最简单的办法使用Hashing Trick,将“所有视频ID”这个集合hash压缩到一个内存可接受的水平
如何构建用户向量
一个用户向量由三部分组成:
用户之前看过的视频。每个视频向量都是通过embedding得到,属于优化变量,训练后获得。
用户之前搜索过的关键词。每个词向量也通过embedding获得,属于优化变量,训练后获得。
用户的基本信息,比如性别、年龄、登录地点、使用设备等。这些信息,在“新用户”冷启动时,是唯一可以利用的信息。
视频向量的共享
在召回过程中,“视频向量”发挥了两方面的作用:
而以上两部分的“视频向量”都来自于同一个embedding矩阵。优化变量的共享,类似于“多任务学习”,既增加了对video embedding的训练机会,也相当于增加了更多的限制,有助于降低过拟合。
用户历史的Pooling
一个用户,历史上看过多个视频,也会输入过多个搜索关键词,要将这多个“视频向量”、“搜索词向量” 合并成一个向量,需要一个池化(pooling)操作。
Youtube的做法比较简单,只是将所有“历史观看视频的向量”简单平均,将所有“历史搜索的关键词向量”简单平均,估计在线效果够用了。
是否可以考虑将历史向量,按照时间衰减,进行加权平均?最近观看的向量,在pooling时权重大一些,较远的历史向量,权重小一些?自然可以这样做,不过,至于效果如何,还需要线上测试后,才知道。可能这种费事的加权平均,还多了一个“衰减因子”这个超参,效果未必就比简单平均,有多少优越性。
不过,阿里的Deep Interest Network却在Pooling这个简单环节上大做文章,提出了pooling的新思路,据说获得了非常好的效果。Deep Interest Network的基本思路是:
当给同一个用户展示不同“候选物料”时,将唤醒用户对不同历史的记忆。比如,用户上周买过一套泳衣和一本书。而当给用户展示泳镜时,显然用户关于他买过的“泳衣”的记忆更易被唤醒,也将在决定是否买泳镜时,发挥更大的作用。
所以,Pooling也要模拟这一过程,同一用户在面对不同候选物料时,他的用户向量也不同,实现“千物千面”。
实现上,要将用户向量表示成“历史行为”向量的加权平均,而每个权重由“候选物料”与某特定“历史行为”共同决定,也就是所谓的Attention机制.
视频年龄
除了以上这些历史向量、人员基本信息的特征以外,Youtube还将视频的年龄作为特征加入训练。视频年龄=(样本提取窗口的最大观测时间)-该视频的上传时间。
其实,加入这一特征的原因和处理手法,和处理推荐系统中常见的position-bias是一模一样
上传越早的视频(即年龄越大),自然有更多时间“发酵”,也就更有机会成为受欢迎视频。我们在收集训练样本时,就已经加入这个bias了。
因此,我们需要在训练时,将这一信息考虑在内。否则,其他特征不得不解释由“上传时间早”而带来的额外的受欢迎性,一个特征承担了本不该其承担的解释任务,容易导致 “过拟合”。
但是,在线上召回时,将所有候选视频的年龄都设置成0,对新老视频“一视同仁”,有利于召回那些“虽然上传时间短,但是视频内容与用户更加匹配”的新视频。对于完成“推新”的要求,这是一个非常好的办法。
离线如何训练
构建好了视频向量(通过embedding定义,作为变量参与优化)、用户特征向量(由用户的观看历史、搜索历史、基本信息拼接而成),接下来,就是如何优化这个巨大的softmax loss了。
问题的难点在于,这个softmax中的类别个数=候选视频总个数,达到百万级别。这样一来,计算每个样本的分母,都涉及做百万次的点积、exp、相加,计算量极其巨大,训练效率将极其低下。
解决这一问题的思路,是借鉴NLP,特别是机器翻译、训练词向量中,常见的Sampled Softmax方法。这个方法由两部分组成
做candidate sampling,即为每个正样本(完成观看),配合几千个负样本,这样一来,分母上的点积、exp只需要做几千次
通过以上方法计算出的概率、loss肯定都与原始公式计算出来的有误差,所以再经过importance weighting的方式进行修正
在线如何召回
以上Sampled Softmax算法仅仅是加快了训练速度,预测时,如果要获得准确的观看概率,仍需要计算那包含几百万项的分母,毕竟预测时,你不能再随机抽样负样本了(否则,预测同一个视频两次,因为随机所抽的负样本不同,观看概率也不相同,这样佛系的算法,就没法要了)。
好在我们召回时,并不需要计算每个视频的观看概率。因为,面对同一个用户u,所有候选视频计算softmax时的分母相同,所以召回时,只需要比较分子的大小。所以召回过程,就简化成一个“给定一个用户向量u,在所有视频向量中,寻找与u点积最大的前N个视频向量”的搜索问题。Youtube将训练得到的视频向量存入数据库,并建立索引,从而能够大大加快这一搜索过程。
疑问
看到这里,Youtube的召回网络就介绍完了。可是,我有一个问题:Youtube为什么要用这个巨大的softmax多分类来建模,而不是用p(w|user,video)的二分类(类似点击率预估)来建模?对这个问题,文中没有给出明确的答案。
Youtube使用的多分类softmax模型
优化这样一个具有海量类别的softmax非常困难,不得不牺牲准确度,而使用Sampled Softmax来近似
如何定义负样本?难道真像文章中所说,为每个完成观看的视频,都简单抽样几千个未观看的视频作为负样本?要知道,大量的未观看的视频,压根就没有曝光过,如此简单抽样,样本带有极大的bias。当然,可以只将曝光却未观看的视频作为负样本,但是曝光过的视频,绝大部分是来自上一个版本的推荐引擎,这样收集到的数据同样带有bias。
二分类的类似“点击率预估”模型:
思路简单,让我来做召回,我的第一个直觉就是采用二分类算法来观测是否完成观看
实现简单,Sampled Softmax简化后,也还需要计算几千次点积、exp、加和,而二分类连这个都省了。而且我们同样可以将完成观看的概率写成 ,在线召回时同样可以简化为“近邻搜索”问题而加快计算。
,在线召回时同样可以简化为“近邻搜索”问题而加快计算。
同样受“如何定义负样本”问题的困扰,但是所受影响与softmax多分类完全相同,“多分类建模”在这一点上没有优势。
目前,我能够想到的唯一解释是:softmax loss只和true label=1的类的预测概率有关。为了让softmax loss足够小,不仅“真正完成观看的视频”的概率要大(即分子要大),其他“未完成观看的视频”的概率要小(即分母要小)。这样一来,优化softmax loss类似于在pairwise LTR优化BPR loss,比简单的CTR/CVR预估更加符合推荐系统的实际需求。
排序网络
 排序网络
排序网络
“排序网络”架构与“召回网络”架构极其类似,只不过,使用的特征更加全面,而且由召回时的多分类问题变成“加权的点击率预估”问题。
(??为什么在召回时用多分类建模,而排序时用二分类建模??难道是性能上的原因?有大侠知道其中原因,还望不吝赐教)
重要特征
加权LR预测观看时长
为了防止将一些“标题党”推荐给用户,在排序阶段,Youtube预测的是一个视频的平均观看时长,而不是简单的“点击与否”,并按照预测出的“平均观看时长”对视频排序。
Youtube的做法是通过改变样本权重来预测观看时长,这也是预测“观看/阅读时长”常用的一个方法
正样本(点击样本)的权重是该视频被观看的时长
负样本(未点击样本)的权重就是1
个中原理推导如下:
Logistic Regression中,exp(wx+b)预测的是“胜率”,
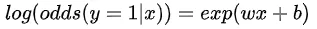 .
.
而对正类按观看时长加权后,胜率公式不再是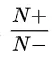 ,而变成
,而变成 , N+是这个视频总的被点击数,N是该视频的总曝光数,Ti是该视频第i次被观看时的观看时长。
, N+是这个视频总的被点击数,N是该视频的总曝光数,Ti是该视频第i次被观看时的观看时长。
进一步推导,  , P=N+/N,即点击率,通常是一个非常小的数. 所以
, P=N+/N,即点击率,通常是一个非常小的数. 所以 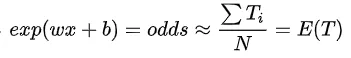 , 即平均观看时长.
, 即平均观看时长.
所以在对正样本重新加权后,排序网络预测出的是视频的平均观看时长,并根据它进行排序。
注意,这个思路也可以应用于其他场景中,在推荐商品时,对训练样本中的“点击正样本”加权,权重是该商品的历史成交金额(GMV),这有利于将用户喜欢并且高价值商品排序在前,有助于增加商家的利润。
疑问
训练时按观看时长加权重,线上按照观看时长排序,岂不是对短视频不公平?Youtube是如何处理这一bias的呢?或者是Youtube有意为之,观看长视频能够增加用户黏性,还能多插播多段广告。
总结
我觉得本文的技术亮点有如下几点:

公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

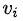 ?如何构建u?
?如何构建u?

