作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
机器学习综述
从零开始学人工智能(17)--数学 · 神经网络(一)· 前向传导
从零开始学人工智能(18)--数学 · 神经网络(二)· BP(反向传播)
从零开始学人工智能(19)--数学 · 神经网络(三)· 损失函数
类似的东西在Python · 神经网络(七)· CNN里面说过,但我觉得还是单独开一章来讲会更清晰一点;以及我接触 CNN 的时间非常有限,如果本文有讲得不对的地方、还望观众老爷们不吝指出 ( σ'ω')σ
CNN 的思想
从名字也可以看出、卷积神经网络(CNN)其实是神经网络(NN)的一种拓展,而事实上从结构上来说,朴素的 CNN 和朴素的 NN 没有任何区别(当然,引入了特殊结构的、复杂的 CNN 会和 NN 有着比较大的区别)。本章我们主要会说一下 CNN 的思想以及它到底在 NN 的基础上做了哪些改进,同时也会说一下 CNN 能够解决的任务类型
CNN 的主要思想可以概括为如下两点:
它们有很好直观。举个栗子,我们平时四处看风景时,都是“一块一块”来看的、信息也都是“一块一块”地接收的(所谓的【局部感受野】)。在这个过程中,我们的思想在看的过程中通常是不怎么变的、而在看完后可能会发出“啊这风景好美”的感慨、然后可能会根据这个感慨来调整我们的思想。在这个栗子中,那“一块一块”的风景就是局部连接,我们的思想就是权值。我们在看风景时用的都是自己的思想,这就是权值共享的生物学意义(注:这个栗子是我开脑洞开出来的、完全不能保证其学术严谨性、还请各位观众老爷们带着批判的眼光去看待它……如果有这方面专长的观众老爷发现我完全就在瞎扯淡、还望不吝指出 ( σ'ω')σ)
光用文字叙述可能还是有些懵懂,我来画张图(参考了一张被引用烂了的图;但由于原图有一定的误导性、所以还是打算自己画一个)(虽然很丑):
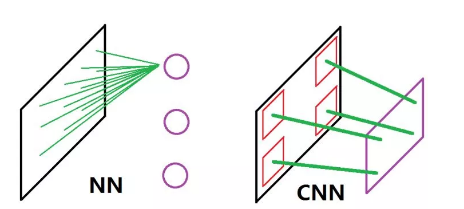
这张图比较了 NN 和 CNN 的思想差别。左图为 NN,可以看到它在处理输入时是全连接的、亦即它采用的是全局感受野,同时各个神经元又是相对独立的、这直接导致它难以将原数据样本翻译成一个“视野”。而正如上面所说,CNN 采用的是局部感受野 + 共享权值,这在右图中的表现为它的神经元可以看成是“一整块”的“视野”,这块视野的每一个组成部分都是共享的权值(右图中那些又粗又长的绿线)在原数据样本的某一个局部上“看到”的东西。
用上文中看风景的例子来说的话,CNN 的行为比较像一个正常人的表现、而 NN 的行为就更像是很多个能把整个风景都看在眼底的人同时看了同一个风景、然后分别感慨了一下并把这个感慨传递下去这种表现(???)
再次感谢评论区@齐显东 举的小栗子,这里我就做一个搬运工吧:
为什么可以这样?- 因为比如一只猫的头部,一个车的棱角"pattern"只在3*3的像素格就可以表现出来,不必用全连接所有像素点去"获取信息量"
CNN 好处呢? - 共享参数能够显著减少参数的数量
其中第二点在理解了下述前向传导算法后应该能比较清晰地认识到,我这里就偷个懒、不举具体的栗子了(不过如果有需求的话我还是会补上的 ( σ'ω')σ)
前向传导算法
与 NN 相对应的,CNN 也有前向传导算法、而且与 NN 的相似之处也很多(至少从实现的层面来说它们的结构几乎一模一样)。它们之间的不同之处则主要体现在如下两点:


可以用下图来直观认知一下该区别:
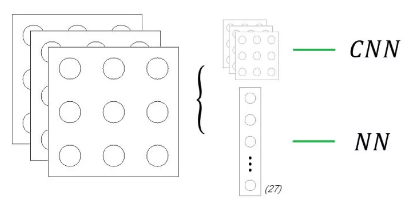
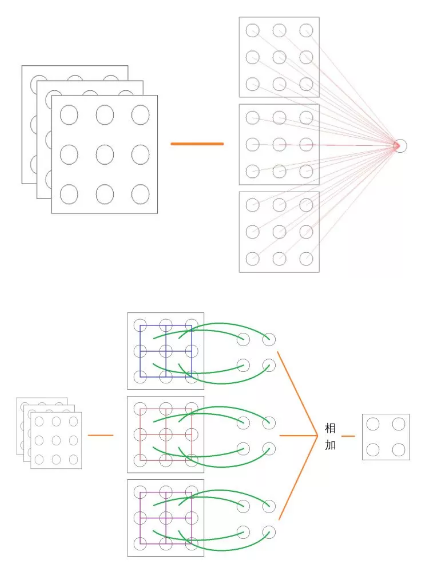
所以两者的前向传导算法就可以用以下两张图来进行直观说明了(NN 在上,CNN 在下):
(我已经尽我全力来画得好看一点了……)
下面进行进一步的说明:
对于一个3×3×3的输入,我们可以把它拆分成 3个3×3 的输入的堆叠(如果3×3×3的输入看成是一个“图像”的话,我们可以把拆分后的 3 个输入看成是该图像的 3 个“频道”;对于原始输入来讲,这 3 个频道通常就是 RGB 通道)
由于 NN 是全连接的,所以输入的所有信息都会直接输入给下一层的某个神经元
由于 CNN 是局部连接、共享权值的,一个合理的做法就是给拆分后的每个“频道”分配一个共享的“局部视野”(注意上面 CNN 那张图中三个“频道”中间都有 4 个相同颜色的正方形、且三个频道中正方形的颜色彼此不同,这就是局部共享视野的意义)(谁注意得到啊喂)。我们通常会把这三个局部视野视为一个整体并把它称作一个 Kernel 或一个 Filter
上面 CNN 那张图里面我们用的是2×2的局部视野,该局部视野从相应频道左上看到右上、然后看左下、最后看右下,这个过程中一共看了四次、每看一次就会生成一个输出。所以三个局部视野会分别在对应的频道上生成四个输出、亦即一个 Kernel(或说一个 Filter)会生成 3 个2×2的输出,将它们直接相加就得到了该 Kernel 的最终输出——一个2×2的频道
上面最后提到的“左上→右上→左下→右下”这个“看”的过程其实就是所谓的“卷积”,这也正是卷积神经网络名字的由来。卷积本身的数学定义要比上面这个简单的描述要繁复得多,但幸运的是、实现和应用 CNN 本身并不需要具备这方面的数学理论知识(当然如果想开发更好的 CNN 结构与算法的话、是需要进行相关研究的,不过这些都已超出我们讨论的范围了)
注意:上面 CNN 那张图中的情形为只有一个 Kernel 的情形,通常来说在实际应用中、我们会使用几十甚至几百个 Kernel 以期望网络能够学习出更好的特征——这是因为一个 Kernel 会生成一个频道,几十、几百个 Kernel 就意味着会生成几十、几百个频道,由此可以期待这大量不同的频道能够对数据进行足够强的描述(要知道原始数据可只有 3 个频道)
不难根据这些内容总结出 NN 和 CNN 目前为止的异同:
NN 和 CNN 的主要结构都是层,但是 NN 的层结构是一维的、CNN 的层结构是高维的
NN 处理的一般是“线性”的数据,CNN 则从直观上更适合处理“结构性的”数据
NN 层结构间会有权值矩阵作为连接的桥梁,CNN 则没有层结构之间的权值矩阵、取而代之的是层结构本身的局部视野。该局部视野会在前向传导算法中与层结构进行卷积运算来得到结果、并会直接将这个结果(或将被激活函数作用后的结果)传给下一层。因此我们常称 NN 中的层结构为“普通层”、称 CNN 中拥有局部视野的层结构为“卷积层”
可以看出、CNN 与 NN 区别之关键正在于“卷积”二字。虽然卷积的直观形式比较简单、但是它的实现却并不平凡。常用的解决方案有如下两种:
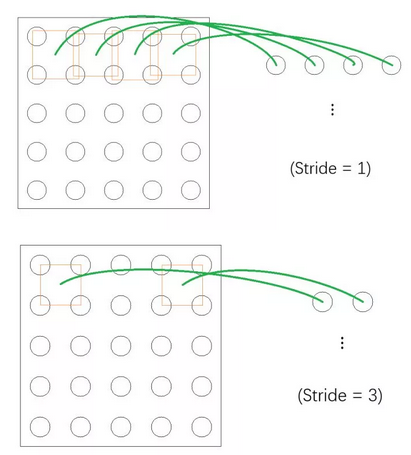
然后介绍一下 Stride 和 Padding 的概念。Stride 可以翻译成“步长”,它描述了局部视野在频道上的“浏览速度”。设想现在有一个5×5的频道而我们的局部视野是2×2的,那么不同 Stride 下的表现将如下面两张图所示(只以第一排为例):
(……)
可以看到上图中局部视野每次前进“一步”而下图中每次会前进“三步”
Padding 可以翻译成“填充”、其存在意义有许多种解释,一种最好理解的就是——它能保持输入和输出的频道形状一致。注意目前为止展示过的栗子中,输入频道在被卷积之后、输出的频道都会“缩小”一点。这样在经过相当有限的卷积操作后、输入就会变得过小而不适合再进行卷积,从而就会大大限制了整个网络结构的深度。Padding 正是这个问题的一种解决方案:它会在输入频道进行卷积之前、先在频道的周围“填充”上若干圈的“0”。设想现在有一个3×3的频道而我们的局部视野也是3×3的,如果按照之前所说的卷积来做的话、不难想象输出将会是1×1的频道;不过如果我们将 Padding 设置为 1、亦即在输入的频道周围填充一圈 0 的话,那么卷积的表现将如下图所示:
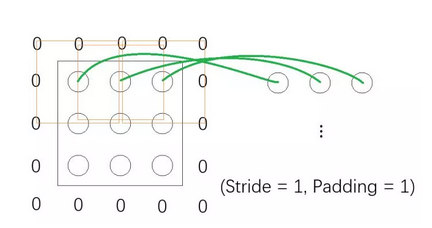
可以看到当我们在输入频道外面 Pad 上一圈 0 之后、输出就变成3×3的了,这为超深层 CNN 的搭建创造了可能性(比如有名的 ResNet)
在 cs231n 的这篇文章(http://cs231n.github.io/convolutional-networks/)里面有一张很好很好很好的动图(大概位于页面中央),请允许我偷个懒不自己动手画了…… ( σ'ω')σ
全连接层(Fully Connected Layer)
全连接层常简称为 FC,它是可能会出现在 CNN 中的、一个比较特殊的结构;从名字就可以大概猜想到、FC 应该和普通层息息相关,事实上也正是如此。直观地说、FC 是连接卷积层和普通层的普通层,它将从父层(卷积层)那里得到的高维数据铺平以作为输入、进行一些非线性变换(用激活函数作用)、然后将结果输进跟在它后面的各个普通层构成的系统中:
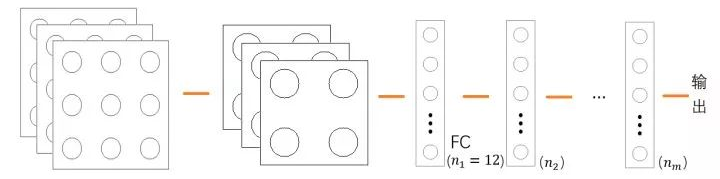
上图中的 FC 一共n1=3×2×2=12个神经元,自 FC 之后的系统其实就是 NN。换句话说、我们可以把 CNN 拆分成如下两块结构:
注意:值得一提的是,在许多常见的网络结构中、NN 块里都只含有 FC 这个普通层
那么为什么 CNN 会有 FC 这个结构呢?或者问得更具体一点、为什么要将总体分成卷积块和 NN 块两部分呢?这其实从直观上来说非常好解释:卷积块中的卷积的基本单元是局部视野,用它类比我们的眼睛的话、就是将外界信息翻译成神经信号的工具,它能将接收的输入中的各个特征提取出来;至于 NN(神经网络)块、则可以类比我们的神经网络(甚至说、类比我们的大脑),它能够利用卷积块得到的信号(特征)来做出相应的决策。概括地说、CNN 视卷积块为“眼”而视 NN 块为“脑”,眼脑结合则决策自成(???)。用机器学习的术语来说、则卷积块为“特征提取器”而 NN 块为“决策分类器”
而事实上,CNN 的强大之处其实正在于其卷积块强大的特征提取能力上、NN 块甚至可以说只是用于分类的一个附属品而已。我们完全可以利用 CNN 将特征提取出来后、用之前介绍过的决策树、支持向量机等等来进行分类这一步而无须使用 NN 块
池化(Pooling)
池化是 NN 中完全没有的、只属于 CNN 的特殊演算。虽然名字听上去可能有些高大上的感觉,但它的本质其实就是“对局部信息的总结”。常见的池化有如下两种:
池化过程其实与卷积过程类似、可以看成是局部视野对输入信息的转换,只不过卷积过程做的是卷积运算、池化过程做的是极大或平均(或其它)运算而已
不过池化与卷积有一点通常是差异较大的——池化的 Stride 通常会比卷积的 Stride 要大。比如对于一个3×3的输入频道和一个3×3的局部视野而言:
将 Stride 选大是符合池化的内涵的:池化是对局部信息的总结、所以自然希望池化能够将得到的信息进行某种“压缩处理”。如果将 Stride 选得比较小的话、总结出来的信息就很可能会产生“冗余”,这就违背了池化的本意。
不过为什么最常见的两种池化——极大池化和平均池化确实能够压缩信息呢?这主要是因为 CNN 一般处理的都是图像数据。由经验可知、图像在像素级间隔上的差异是很小的,这就为上述两种池化提供了一定的合理性
以上就比较泛地说了一下 CNN 的诸多概念,可以看到我没有讲(也不打算讲)(喂)最重要的反向传播算法。这是因为 Tensorflow 能够帮我们处理梯度,所以单就使用 Tensorflow 来实现 CNN 而言、完全不用管反向传播算法应该怎么推 ( σ'ω')σ
不过如果我有空的话,可能会在带星号的章节中讲讲反向传播算法……
希望观众老爷们能够喜欢~
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门

