作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
从零开始学人工智能(12)--Python · 决策树(零)· 简介
从零开始学人工智能(13)--Python · 决策树(一)· 准则
本章用到的 GitHub 地址:
https://github.com/carefree0910/MachineLearning/blob/master/Zhihu/CvDTree/one/CvDTree.py
本章用到的数学相关知识:
https://zhuanlan.zhihu.com/p/24501172
上一章我们把 node 的结构搭好了,这一章要做的就是塞东西进去。为此,我们不妨先看看我们需要实现什么:
大提上来说就是这两点,剩下的就是一些细节。我们分开来说说怎么去实现它们
这一章有点长,稍微总结一下:
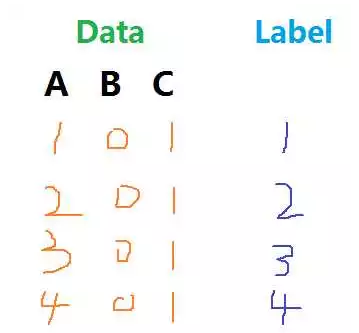
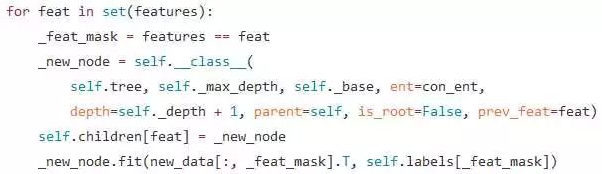
决策树的生长关键是靠递归。当 node 接收一个数据和标签时,它会选出数据的某个维度、记录下来,然后会根据该维度的各个特征将数据、标签进行划分,分别喂给新的 node、从而能够递归下去
在 node 被判定应该是 leaf 时,要判断它属于哪一类并更新它列祖列宗的 leafs 变量
node 的 prune 函数是用来把 node 变成 leaf 并更新结构的,它本身不是决策树的剪枝算法、但它会在决策树的剪枝算法中被调用
下一章我们就要说说怎么建立一个框架以利用这些 node 来搭建一颗真正的决策树了。可能有童鞋已经敏锐地发现:不就只剩一个剪枝算法没有实现了吗?
事实上正是如此。下一章的框架确实只额外地实现了剪枝算法,剩下的都是封装的活儿
希望观众老爷们能够喜欢~
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门