作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
从零开始学人工智能(12)--Python · 决策树(零)· 简介
从零开始学人工智能(13)--Python · 决策树(一)· 准则
本章用到的 GitHub 地址:
https://github.com/carefree0910/MachineLearning/blob/master/Zhihu/CvDTree/one/CvDTree.py
本章用到的数学相关知识:
https://zhuanlan.zhihu.com/p/24497963?refer=carefree0910-pyml
上一章讲了如何定义准则,这一章主要讲怎么定义“节点”。决策树听上去就可以理解成一棵树、而实际上也确实如此。学过数据结构的童鞋们大概对 node 这个概念不会陌生,不过为了让从零开始的童鞋们有个直观理解,我打算援引之前的一个 Wiki 上的图:
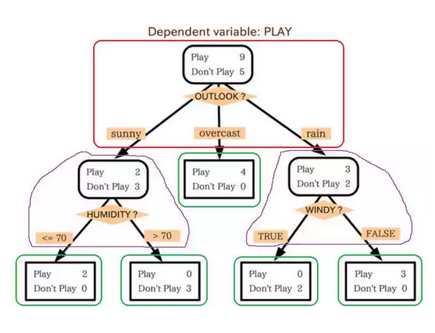
这里面有两点需要注意:
被我框起来的所有东西组成我们决策树结构中的一个 node
被我用绿色框框起来的东西叫做叶子节点(leaf),可以认为每个 leaf 代表着一类
可能会有观众老爷敏锐地发现、除了 leaf 以外的节点、还包括了一个问题。这个问题是怎么选出来的呢?正是由我们上一章讲到的准则选出来的。更具体地说,是通过信息增益来裁决
知道基本思路之后、就可以开始实现了。为简洁(懒),我打算用最简单的 ID3 算法作为栗子
首先是初始化,我们分两步看:
先把 node 自身基本的信息定义好
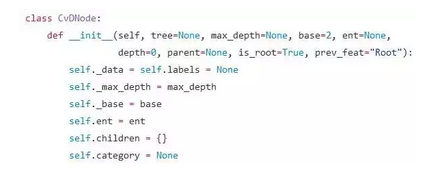
以上变量的用途和变量名的字面意思基本一致,需要特别指出两点:
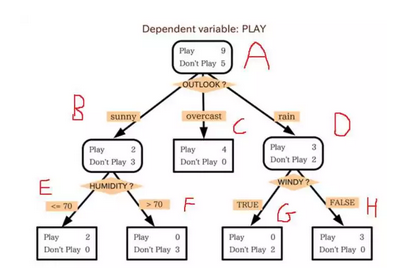
其中,B、C、D 是 A 的孩儿;E、F 是 B 的孩儿;G、H 是 D 的孩儿
再把 node 的一些宏观结构定义好

tree 指的是下一章我们要讲的树结构,可以暂时不管(不过相信聪明的观众老爷们能够从名字上看出前三行在干什么 ( σ'ω')σ )
feature_dim,这个可以说是最关键的变量之一,它记录着该 node 关注的是数据的哪一个维度
与此相对应的是 prev_feat,这个变量记录着它的爸爸的特征的取值。不过需要注意的是该变量的存在仅仅是为了可视化,所以删掉也没什么大的问题
depth,parent 和 is_root 分别记录了 node 的深度、爸爸和它是否是根节点
leafs,这也是最关键的变量之一,记录了该 node 的子孙中有哪些 leaf
还是用上图来说,A 的 leafs 就记录着 CEFGH,B 则记录着 EF,等等
pruned,这个变量记录着该 node 是否已被剪枝,它只会在剪枝算法里面用到,所以其具体用途会在后面章节讲
至此,我们 node 的结构就完全搭建好了,接下来我们会说说如何往这个结构中添加功能、以使它能够递归地生成、裁剪出一颗决策树
希望观众老爷们能够喜欢~
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门

