前段时间比较忙碌,最近终于抽出时间来完成大伟老师布置的作业,作业的数据和要求链接:https://ask.hellobi.com/blog/python_shequ/15453
一、观测数据及数据处理
1.打开文件
import pandas as pd
path=open(r'C:\Users\86135\Desktop\iPython\机器学习\作业房价数据.csv') #打开数据,因为有中文路径直接打不开,使用open转换下
data=pd.read_csv(path)
del data['Unnamed: 0'] #去掉多余的列
data.shape #506条数据,14维向量
2.查看数据
data.info() #查看各数据字段类型,显示全是字符型,未有缺失数据
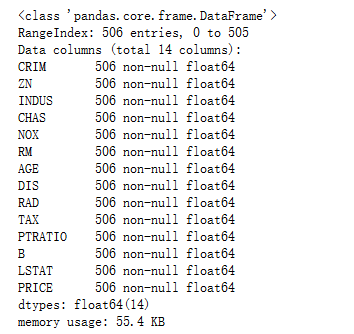
data.describe() #各个字段的详细描述
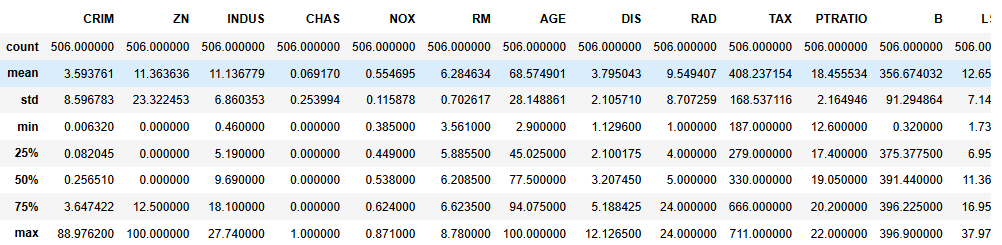
data.head() #前五行数据
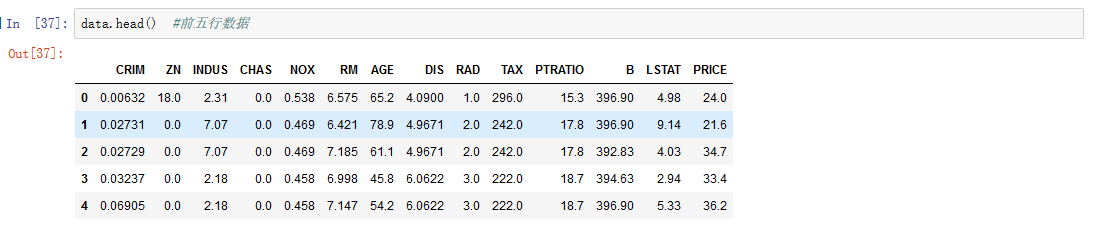
data.tail() #后五行数据
data.columns #所有的字段名
import matplotlib as mpl
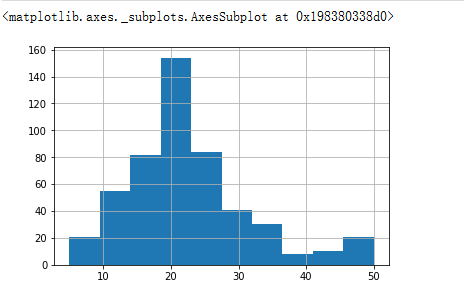
data['PRICE'].hist() #价格直方图,大致符合正态分布
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
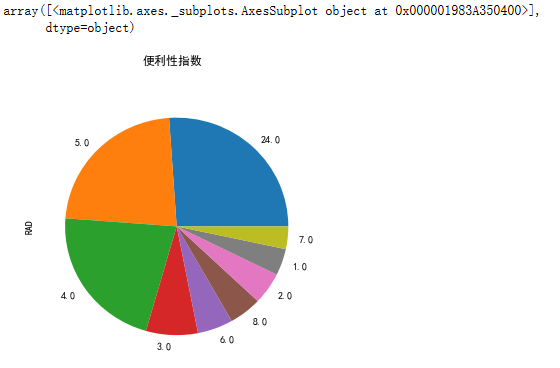
data['RAD'].value_counts().plot(kind="pie",figsize=[5,5],title="便利性指数") #便利指数饼图
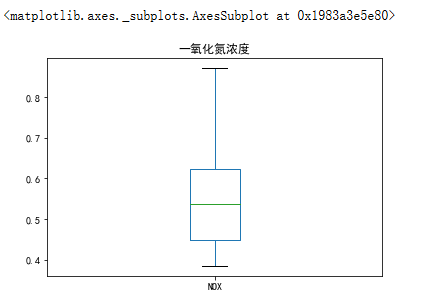
data['NOX'].plot(kind='box',title="一氧化氮浓度") #一氧化氮箱线图
3.数据处理
import numpy as np
df=pd.concat([data, pd.get_dummies(data['CHAS'])], axis = 1 ) #CHAS靠近河床类别 建立虚拟变量
del df[1.0] #删除冗余的变量
del df['CHAS'] #删除冗余的变量
df[0.0]=df[0.0].astype(np.float64)
df.columns=['CRIM', 'ZN','INDUS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','PRICE','0.0']
二、建立线性回归模型
1.建立模型
y= df['PRICE'].values #以价格作为预测的值
X = df[['CRIM','ZN','INDUS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','0.0']] #一共有13个维度的变量
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,y) #得到线性回归模型
print(regr.score(X,y)) #预测结果
2.最小二乘法
import statsmodels.api as sm #最小二乘法
X2 = sm.add_constant(X)#增加常数项
est = sm.OLS(y, X2)#普通最小二乘法模型
est2 = est.fit()
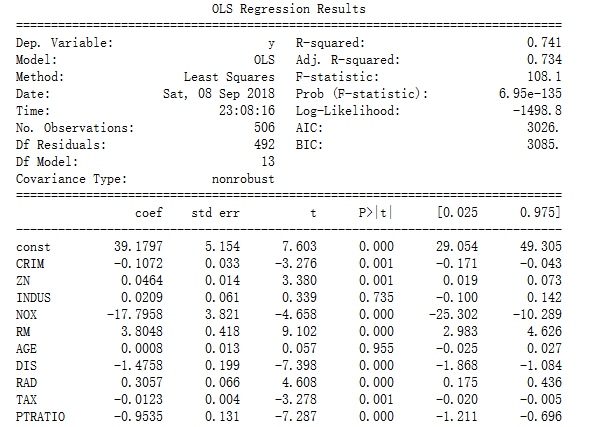
print(est2.summary()) #R-squared拟合度优度0.741,F检验P值小于0.05,对房价有显著性影响
三、特征选择和AIC优化模型
1.特征选择
开始使用卡方(chi2)检验的时候发现老是报错,预测价格数据需要转换成整数型,后来才发现chi2是针对预测目标属于离散(分类问题)而选择的函数,在此则使用F检验方法(f_regression)处理线性回归
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
y= df['PRICE']
X = df[['CRIM','ZN','INDUS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','0.0']]
fs = feature_selection.SelectPercentile(feature_selection.f_regression, percentile=20)#使用F检验取前20%的特征
X_fs = fs.fit_transform(X,y)
regr.fit(X_fs,y)
print(regr.score(X_fs,y))
结果选择前20%的数据预测达到0.68
2.AIC优化
predictorcols = ['CRIM','ZN','INDUS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','0.0']
import statsmodels.api as sm
import itertools #引用迭代工具
AICs = {}
for k in range(1,len(predictorcols)+1):
for variables in itertools.combinations(predictorcols, k):
predictors = X[list(variables)]
predictors2 = sm.add_constant(predictors)
est = sm.OLS(y, predictors2)
res = est.fit()
AICs[variables] = res.aic
from collections import Counter
c = Counter(AICs)
print(c.most_common()[:len(AICs)-4:-1])#最后面三项倒着排序

总结:回顾做的过程,作业的要求在课堂上都讲过,而在做特征选择的时候不是很明白各函数意义纠结半天,不管如何还是非常感谢大伟老师指导了很多知识,如果有任何问题欢迎互相交流,我做的过程的详细代码在GitHub上可以看到:https://github.com/Cherishsword/predict-price
ps:作业的数据和sklearn自带数据集:波士顿房价预测很相似,大家可以参考下。

