前言
消失了20天…出来更新一下表示专栏还没有太监。最近不太有时间来写,大概到8月份才有时间系统写这个系列了。之所以在复习期末考试的间隙插播这篇文章,是因为最近刚好有机会抓到了学校网站上学生的个人信息、证件照,趁热记录一下,其实根本没有涉及到黑客破解之类高大上的东西,都是很基础的爬虫知识,作为这个系列的第二篇难度上也是合理的。
标题是个噱头。Facemash类的网站褒贬不一,现在down下来三个年级的证件照,鉴于一卡通的证件照是军训时拍的,拍的简直…比真人丑很多…就不冒着侵犯别人肖像权隐私权去做什么评分网站了。数据自己留着也是留着,刚好想起来前段时间挺火的微软How-old网站,就试着把爬到的证件照传到How-old上判别一下性别、年龄,结果就是性别的准确度还挺高的…年龄纯属娱乐了。
所以我们这次分为三步:
抓取学生信息——通过学号信息抓取照片——将照片上传到http://how-old.net检测图片。
需要说明的是,除第三步不涉及个人信息外,学生信息和证件照不提供网址。如果是我电的同学,有心的人可以在睿思上试着搜一下,我就是从一个贴子里看到的这个方法的。
这次我们倒着写吧……
一、扩展阅读
facemash_百度百科
学生信息频遭泄露 Facemash网站风靡高校
“武大素颜”事件:一个只懂技术的扭曲死宅有多可怕
How Old do I Look?
二、结果展示
1、学生信息

2、证件照
3、http://How-old.net自动检测图像
三、原理简介
1、学生信息(来自睿思)
英语交互成绩页面不需登录,只需要修改参数中的就可以看到不同学生的成绩页面。

http://就不告诉你/Web/studyprogress/studentUnitReport.aspx?studentuserid=XXXXX
可以看到页面里有姓名学号信息,从页面源码中用正则将信息抽取出来就好。
2、 证件照(来自@冯文琦 )
我们学校原本只有一个教务处系统,后来学工处做了一个学生服务门户,整合了校内信息。要求学生完善填写个人信息(包括邮箱、手机号、银行卡号)。但是存在一个…很弱智的漏洞…就是证件照的网址…只需要修改学号就可以看到任意人的照片。什么都不需要做…修改学号然后保存就可以了…
http://就不告诉你/就不告诉你/XXXXXXXX.jpg
3、http://How-old.net自动检测图像
上传自己的照片就可以看到结果,当然我们自然不能挨着手动上传。所以我们需要考虑怎么让系统自动上传图片并获得返回结果。

通过网络抓包,可以看到如下的地址和发送/接收信息。

这堆乱码就是我们上传的图片了。
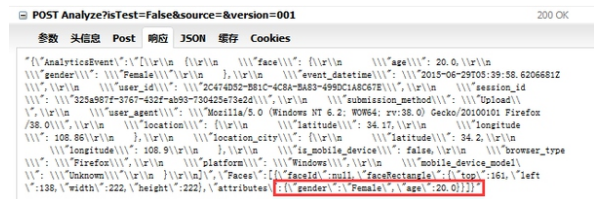
可以看到返回值中有性别和年龄信息,抽取出来即可。
四、代码实现
1、学生信息
留坑以后填。这里要详细说正则。
2、证件照
我们在Python 爬虫笔记(1):综述 已经说过如何保存图片了,当时我们用的是urlretrieve方法,这次我们用另一种方法:
import urllib2
sid = xxxxxxxx
jpgurl = '就不告诉你'+sid+'.jpg'
response = urllib2.urlopen(jpgurl)
img = response.read()
with open(sid+'.jpg','wb') as f:
f.write(img)
这样就能把图片保存到本地了。
3、http://How-old.net自动检测图像
留坑:网络抓包、headers、get、post、requests库
前面我们已经看到了,在http://how-old.net里,我们向服务器发送了图片(一堆乱码),然后服务器返回给我们一些信息,其中有我们需要的性别和年龄信息。
实现上传图片并没有想象中的复杂。
import requests
s = requests.session()
url = 'http://how-old.net/Home/Analyze?isTest=False&source=&version=001'
header = {
'Accept-Encoding':'gzip, deflate',
'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0",
'Host': "how-old.net",
'Referer': "http://how-old.net/",
'X-Requested-With': "XMLHttpRequest"
}
data = {'file':open(sid+'.jpg', 'rb')}
#此处打开指定的jpg文件
r = s.post(url, files=data, headers=header)
h = r.content
print h
这里只需要修改open(sid+'.jpg', 'rb')中的文件名(包括路径,不填写路径时默认和代码保存的为同一路径,关于路径、绝对路径、相对路径,留坑)就可以了。
这里的h是整个返回页面的源码,前面的正则部分留坑了,所以这里也不详写了。有基础的人应该很容易都能抽取出来。
五、总结
1、可以看出这些操作没什么难度,不涉及破解,但是可以抓取出近4W条学生信息和证件照,系统中还存着我们的手机号、邮箱、银行卡号,会不会有更大的隐患?各个高校的教务系统似乎都不是太先进,许多年前就开始不停地提问题、出问题,为什么迟迟得不到解决?信息安全谁来保障,信息泄露的责任谁来承担?
2、爬虫本身不难,本质上不过是模仿人类对浏览器的操作,让系统伪装成浏览器来代替人快速地爬去海量数据。所以关键还是在于对抓取到的数据如何操作、利用。
3、还是留了很多坑,写的很草。有时间来完善!
