写在最前:这只是一个新手的学习笔记,错误之处还望指出。欢迎友善交流,大神轻喷。
一、前言:
从今天开始动手写关于Python爬虫的一个系列,作为这段时间的总结和沉淀。这个系列会有以下特点:
- 零基础。国内打着“21天”“零基础”“从入门到精通”旗号的书太多,以至于“零基础”这个词现在在我眼里基本上等于“不靠谱”。我这次的系列,大概以让@曲小花 能看懂为目的吧,她应该算得上零基础
- 入门。我对自己的定位也只能算是入门,当然在某些大牛眼里可能入门也算不上。我尽量把我会的东西都记录下来
- 简单、重实践。在最近的学习过程中,我看了许多的博客,其中有一些是爬虫的系列教程,写的很棒;我也看了两套Python视频中关于爬虫的部分,讲的也很好。但是有一个问题,他们讲的太详细了,说实话,我到现在也没能完全学会使用正则表达式,BeautifulSoup也是只摸索会了最基本的几个方法,然而对我来说已经够用了。问题在于,除了最常用的几个用法,其他用法是很难记住的,而遇到不会的情况,只需要搜索一下,然后记住相应的写法就可以了。此外,很多博客的理论和实战是分开的,一般都是urllib、cookie、正则 balabala讲完了然后写几个实战的过程,感觉最容易产生学习兴趣的是那些“所见即所得”的东西,所以尽量拆出一些很小的部分来用作每部分的实践。
大概的思路还是有的,但是不知道具体要写多少篇。写到哪里算哪里吧。
二、什么是爬虫
程序是用来完成重复性工作的。落实到爬虫上,我们有时候需要在网上搜集一些资料,比如你发现了一篇小说,但是不提供直接下载,需要一页一页手动保存;又比如你对贴吧里某个帖子很感兴趣,想把每一楼的内容保存下来;再或者你想把煎蛋或者糗事百科上面的图片保存下来,一张一张地右键未免效率太低;往大了说,像百度、谷歌需要抓取全网的数据然后建立一个索引供我们搜索,其实也是用的爬虫。
那么什么是爬虫?
把互联网看作一张网,爬虫就是我们放到这张网上的一个程序,它会自动在网上爬,并且把爬过的网页保存下来,我们可以指定让它去哪里爬,也可以对爬取得到的网页进行加工处理获得我们想要的信息。
三、为什么是Python
Python被广泛用来写爬虫,大概是因为Python有比较成熟的爬虫框架Scrapy,然而我现在还没有学会用Scrapy。
但是Python仍然是用来学编程的上好选择。
首先Python是一门解释型的语言。不需要复杂的编译运行过程,更像是我们想要的“所见即所得”。
#此处需要对解释型和编译型语言作区分
其次Python的语法非常简单,接近于伪码。在我的这个系列里面,Python语法占到的篇幅不会太多,因为实在是太简单了。
四、Python的安装(包括pip的安装和使用)
1、版本的选择
Python现在的主要版本是2.7和3.4。Python3对Python2的兼容性很差,修改了很多方面的东西。毫无疑问Python3优于Python2的,尤其是在字符的编码问题上,Python3作出了很大的改动,变得更加方便。但是由于我入坑的时候看的第一篇教程是Python2…也决定了我之后的日子里要很多次地纠结字符编码问题。不过我还是可以给学习Python2强行找到一个理由,那就是现在比较成熟的爬虫框架Scrapy目前只支持Python2。
2、安装Python
Welcome to Python.org 首先你应该确保你的网络环境能打开Python的官方网站。这不仅仅关乎Python的安装,更重要的是其他扩展库的安装。
进入Downloads页面,我们可以根据自己的选择找到自己想要的版本。现在我们以Python2.7.10 for Windows为例。
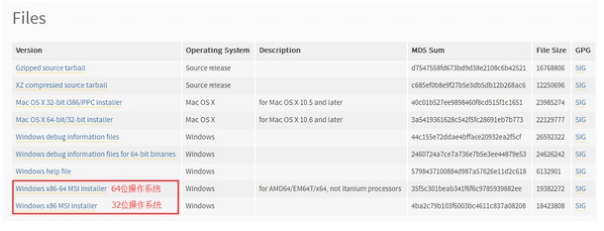
下载完以后正常安装就可以了,路径不一定要在C盘,但是最好不要把安装目录设的太复杂。
安装过程中出错因为没有提供管理员权限,解决办法参见Win8安装程序出现2502、2503错误解决方法
其实.msi文件右键时都没有“以管理员身份运行”的选项,一劳永逸的解决办法参见找回MSI安装包Win7/Win8管理员身份功能
安装完成以后还没有结束,一般的教程到这里会告诉你怎么样去添加系统变量,怎么样在cmd里面使用python命令,可是我觉得这对于新手来讲有点不求甚解;又有人会教你如何如何安装Pycharm之类的IDE——每次看到添加环境变量或者安装IDE我就会想起我学习Java永远停留在了eclipse的安装。所以既然是入门教程,不妨采用一种更简单直观的方法吧,至于前面提到的东西,入门以后自然而然也就知其然并知其所以然了。
入门阶段我们只需要使用Python自带的编辑器就可以了。
找到E:\Python27\Lib\idlelib\idle.bat 这个文件,把它发送到桌面快捷方式,之后你就可以在桌面直接打开IDLE编辑器了。
到这一步我们的安装就可以宣告结束了。如果你想要学习Python3的话你可以使用相同的办法安装Python3并将它的IDLE发送到桌面快捷方式(PY2和PY3是可以同时安装的),注意给它改一个名字以作区分。

我们也可以同时打开两个版本的Python程序,对它们做一个简单的对比。
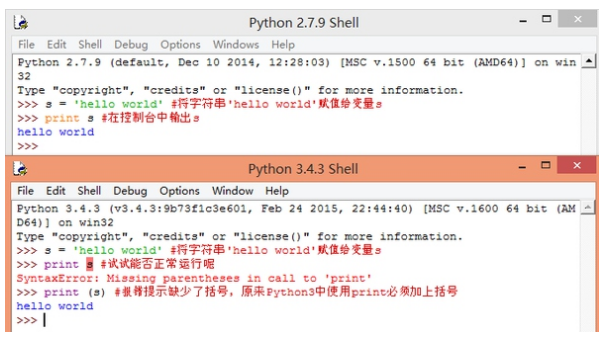
我们以后还会经常对PY2和PY3的改动进行区分。
3、pip的使用
Python众多成熟方便的第三方库也是Python的优点之一。pip就是用来安装这些库最方便的方法。
从python官网下载的安装包中一般都已经包含了pip,查看E:\Python27\Scripts路径中是否有pip.exe这个文件。如果没有的话,运行get-pip.py来安装pip
我们在查看别人的代码时一般都会看到程序运行所依赖的库,以egrcc/zhihu-python · GitHub为例。
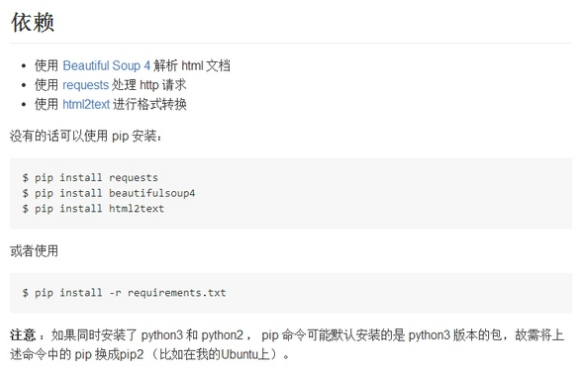
在Windows下我们这样使用pip
win+R 运行 cmd
打开E:\Python27\Scripts
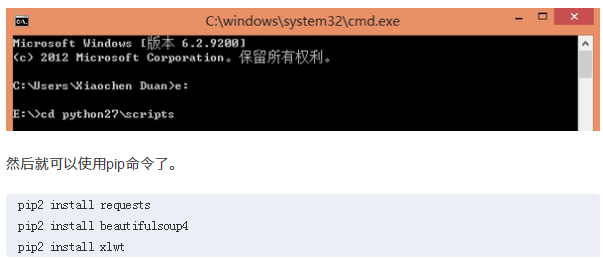
然后就可以使用pip命令了。
pip2 install requests
pip2 install beautifulsoup4
pip2 install xlwt
你可以选择现在安装这些库,也可以选择以后遇到的时候安装。需要说明:
1、你可以尝试将python和scripts目录加入环境变量,这样你就可以直接使用pip命令而不必每次都打开安装路径
2、同时安装了py2和py3时应该使用pip2命令
五、第一次尝试抓取网页、保存图片
完成上面一步Python就已经安装成功了,现在我们来做两个小的尝试。在这里我会对每一步写上注释大家不用太过纠结其中用到的方法。后面我们都会详细讲解的。
1、尝试获取一个页面的源码
试试我们最常用的网页吧——百度,我们都知道,在浏览器中右键-查看源文件,可以查看到这个页面的html代码,在Python中我们需要两行代码来做这件事。
首先我们新建一个python文档。在IDLE中点击File-New File,然后就可以开始愉快地写代码了~
import urllib2 #导入urllib2库
response = urllib2.urlopen('http://www.baidu.com') #打开网址
html = response.read() #读出网址源码
print html #在控制台中输出
点击F5运行,运行前需要先保存代码。运行以后得到的结果…嗯…看上去很乱,但是你去查看百度首页的源码就会发现其实和我们获取的页面代码是一样的(当然此处没有登陆,所以跟你定制的首页不一样)。
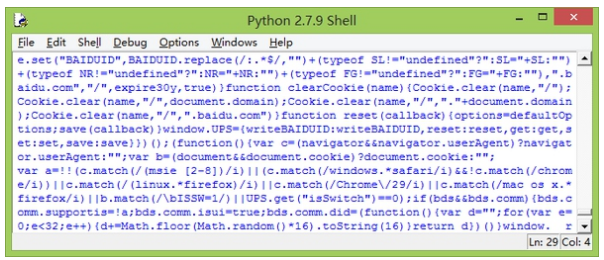
我们可以将输出的代码保存到一个html文件中,看看是不是熟悉的百度页面。怎么保存?当然不是手动地复制粘贴。
# -*- coding: utf-8 -*-
#指定编码方式
import urllib2 #导入urllib2库
response = urllib2.urlopen('http://www.baidu.com') #打开网址
html = response.read() #读出网址源码
#print html #在控制台中输出
with open('baidu.html','w') as f:
f.write(html) #将html写入文件中
运行以后我们会发现在我们保存代码的目录中得到了一个baidu.html文件。
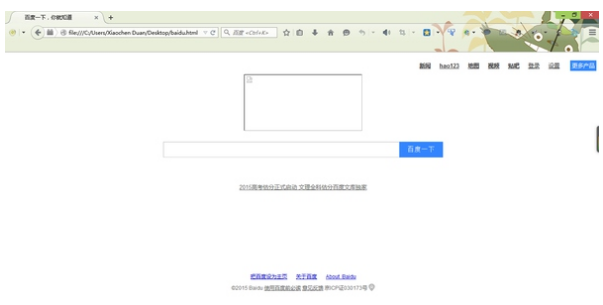
和我们平常看到的百度首页是一样的,只不过缺少了图片。缺少图片的原因是因为图片的路径不对。当然我们现在已经达到获取页面源码的目标了,如果一定要追求完美的话…让我们把缺失的图片找回来吧。
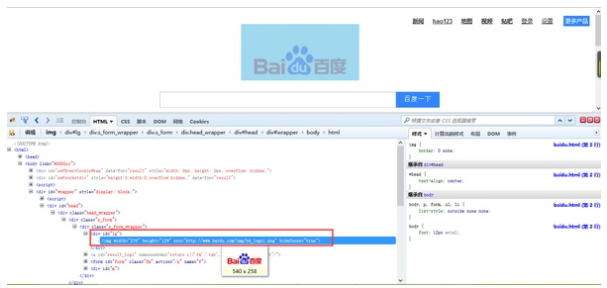
在Firefox中点击F12使用Firebug(后面还会详细讲解),如图选择查看页面元素功能

当你选定缺失的图片的时候,你会惊奇地发现它自动定位到了图片在源码中的位置

我们容易看到,在这里图片地址写作了 //www.baidu.com/img/bd_logo1.png 缺少了http(在这里不详细解释了),我们只需要在下载到的源码中加上http:就可以了。
2、从页面中保存图片
在这里我们使用{placekitten} 作为示例。我在小甲鱼的Python视频中知道的这个网站。
这个网站的特点就是你输入任意一个形如 http://placekitten.com/g/200/300 格式的网址就可以获得一张指定了宽高的喵图(后面两个数字即为指定的宽高)。
我们现在尝试将这张图片保存下来。和刚才几乎没什么差别。
# -*- coding: utf-8 -*-
#指定编码方式
import urllib2 #导入urllib2库
response = urllib2.urlopen('http://placekitten.com/g/200/300') #打开网址
html = response.read()
#print html #在控制台中输出
with open('d:\cat.jpg','wb') as f:
f.write(html) #将html写入文件中
需要注意的是,我们和刚才有两点不同的地方。
1、在open('d:\cat.jpg','wb')时,我们指定了文件的路径。于是我们知道,如果没有指定路径的话,文件会保存在代码所在的文件夹,之后我们还会涉及到文件的相对路径和绝对路径
2、之前是'w',后面是'wb',现在我们先不作解释,在后面会详细讲解Python中对文件的操作。
有人要说了,只不过下载一张图片而已,手动也不过右键另存为,这里要用7行代码,也太多了吧。当然有更简单的做法,试一试:
# -*- coding: utf-8 -*-
import urllib #导入urllib库,注意和刚才的库不一样
urllib.urlretrieve('http://placekitten.com/g/200/300','d:\cat.jpg')
填坑完毕。第一篇到这里结束。
交给@曲小花看完以后再来修改她看不懂的部分就好~
原来想每天更一篇,现在发现还是太年轻。自己很多概念用法其实不是太清楚,自己凑合着瞎用也就算了,不能写出来误导别人,所以还是要精雕细琢,能三天出一篇就不错了。
本来也是写出来自娱自乐,作为一段学习的沉淀和总结,没想到也有人关注,有人来看,还是很开心的。努力不烂尾。

