
提要:
这篇文章里我们会写:
1、如何对一个聊天机器人进行抓包分析接口;
2、如何将现成的聊天机器 API 部署到自己的公众号上;
3、如何实现接收语音消息并调用聊天机器人 API 自动回复文字;
4、如何让机器人根据上下文回复消息。
终于来更新了…代码和功能其实已经弄好好几天了,拖延症发作每次打开写专栏的页面就什么都懒得写,不过程序跑在 SAE 上每天都在扣云豆,每天也就@曲小花 还跟机器人聊几句,估计也不太有时间接着弄了,所以还是抓紧时间先整理完这篇文章吧。
上篇文章(从零开始 Python 微信公众号开发)的结尾,我们实现了如下的功能:
1、回复 快递xxxxxx 自动识别快递公司
2、发送图片 识别性别和年龄
3、其他文字信息 原样返回
其实结束在上次的文章就挺好的,因为已经实现了最重要的 token 验证,也尝试了如何处理文字和图片类型的消息,更多的功能和接口可以自己尝试开发,程序员需要的是自己的思考和尝试,而不是别人把所有东西都喂到嘴边。不过我的那群智障朋友能跟一个鹦鹉学舌的公众号玩儿出花来我也是醉了…所以我决定还是再扩展一下公众号的功能吧。
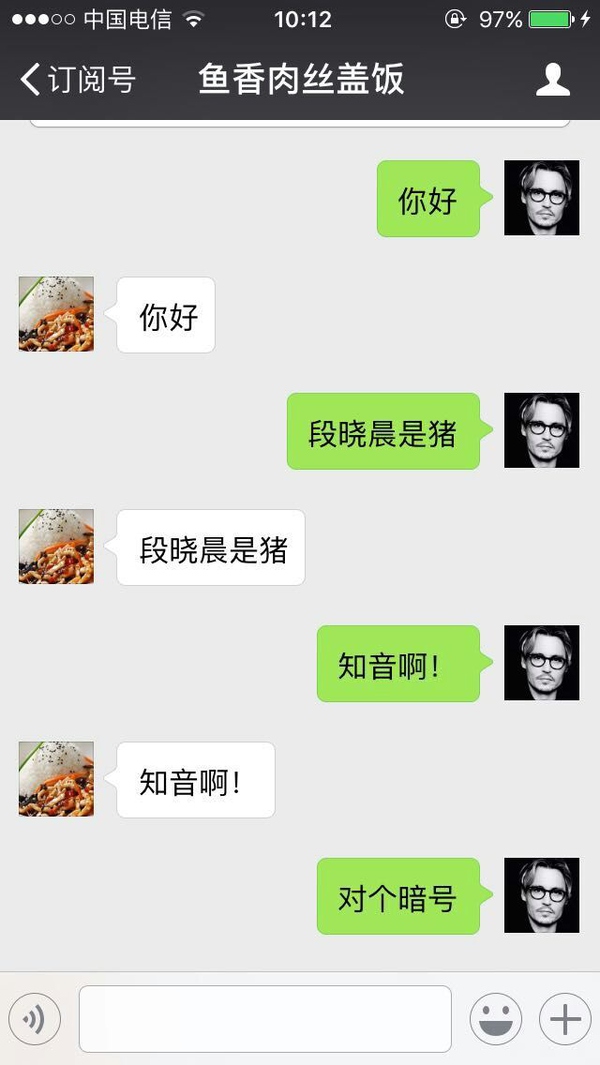
低级的调教…)
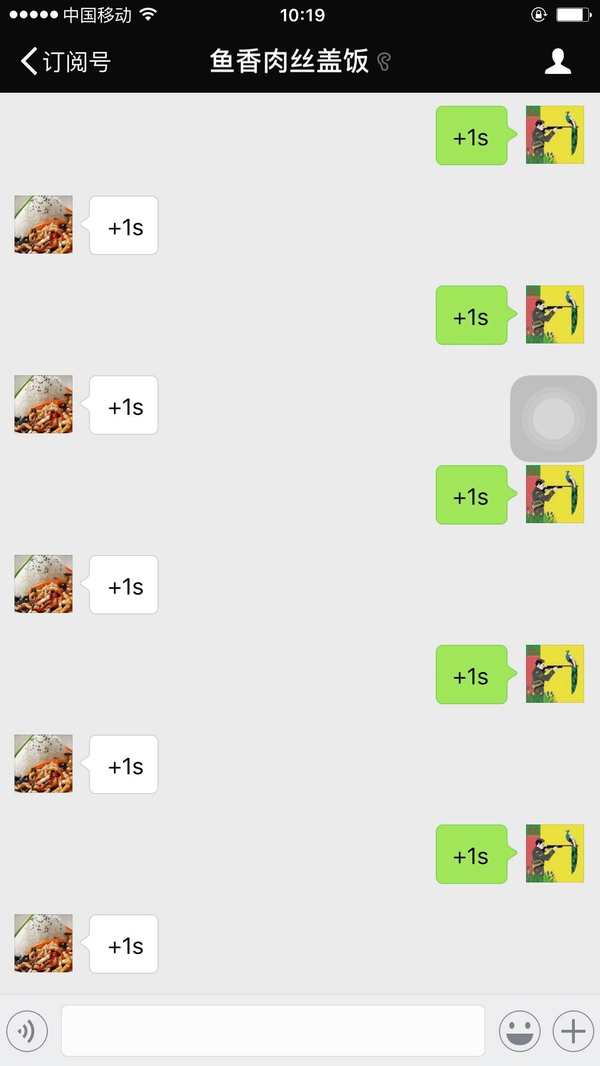
(这位膜法师说,他诚心诚意地续了5下,但是有10s的功效)
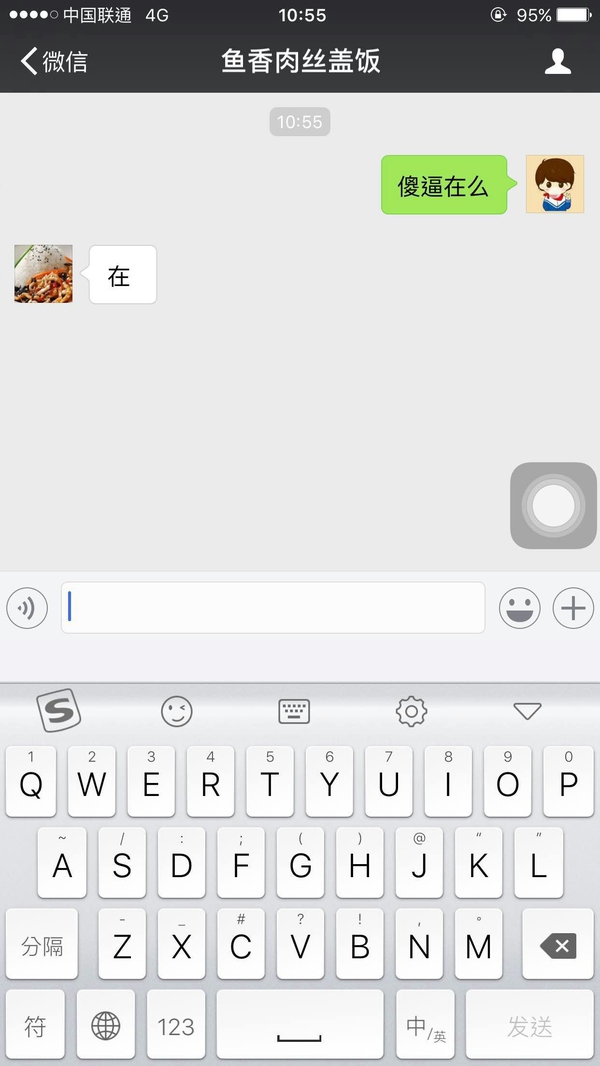
(然后升级版就出现了…自己跟自己聊天完了再删掉中间两行是一种怎样的体验)
鹦鹉学舌的自动回复显然是不能满足实际需要的,最多也就用来测试消息能不能正常返回。但是自己设置关键字回复需要的规则又太多,所以我们选择对已有的聊天机器人进行抓包。
之前有主流的小黄鸡机器人,但是没找到官方的网页版。(小黄鸡提供付费 API )
尝试使用 http://www.niurenqushi.com/app/simsimi/ (虽然事实证明这个网站用的是图灵机器人的 API 而非小黄鸡 API ,后面我们会再谈 API 怎么用)
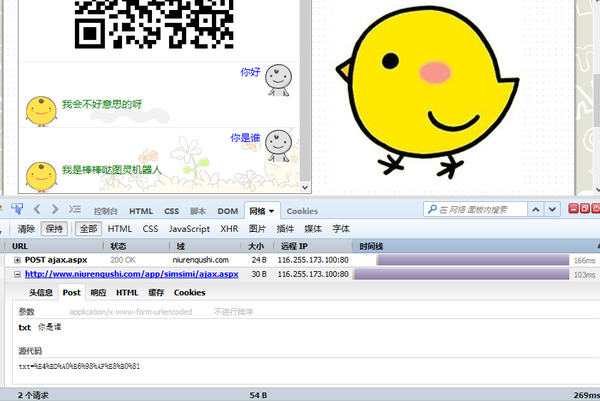
很简单的一个请求。
http://www.niurenqushi.com/app/simsimi/ajax.aspx?txt=
网址后面加上内容就可以了。
# -*- coding: utf-8 -*-
import requests
def talk(content):
s = requests.session()
r = s.post('http://www.niurenqushi.com/app/simsimi/ajax.aspx?txt='+content)
recontent = r.text
return recontent
#如果请求失败自己试试加上headers
抓到了自动回复的内容以后,我们将用户输入的文本内容当作 content 传入,获取回复再返回即可。
从小黄鸡的回复我们可以看出来,丫并不是小黄鸡,而是图灵机器人伪装的。与其给人刷请求量还不如自己去申请一个图灵机器人的 API ,可以自己定制很多东西。
http://www.tuling123.com/ 注册以后会分配自己的 key ,免费版每天 5000 次请求。
官方提供了几种接入方式,其中一种是微信公众平台接入,这种方法直接接入图灵机器人提供的链接而不是自己的服务器,所以对于公众号来讲定制功能的限定就很多,但是如果有小伙伴没有自己的服务器的话,可以用这个尝尝鲜。
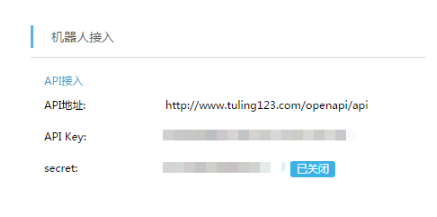
我们已经搭好了 Python 环境的服务器,所以选择 API 接入。
http://www.tuling123.com/html/doc/api.html (推荐自己详细阅读文档)
下面是对 API 调用的 Python 代码:
存储为talk_api.py
(这里的重点是根据返回值中不同的 code 对相应返回的格式进行处理,否则会运行不成功或者返回信息不全)
# -*- coding: utf-8 -*-
import requests
import json
global s
s = requests.session()
def talk(content):
url = 'http://www.tuling123.com/openapi/api'
da = {"key": "your API key", "info": content}
data = json.dumps(da)
r = s.post(url, data=data)
j = eval(r.text)
code = j['code']
if code == 100000:
recontent = j['text']
elif code == 200000:
recontent = j['text']+j['url']
elif code == 302000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
elif code == 308000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
else:
recontent = '这货还没学会怎么回复这句话'
return recontent
修改其中的 API key,然后修改之前的 weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
if msgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
kuaidi = cxkd.detect_com(post)
return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
try:
msg = talk_api.talk(content, userid)
return self.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), '这货还不够聪明,换句话聊天吧')
这样我们就实现了调用图灵机器人 API 微信公众号后台自动回复的功能。你可以在http://www.tuling123.com/web/robot_settings!index.action?cur=l_02 修改机器人设定,机器人后台会根据设定自动修改相应回复。
示例:
实现了文本信息的聊天以后我就在想,我们已经可以处理文本、图片了,能不能处理语音呢?
刚好看到微信官方提供了接口:
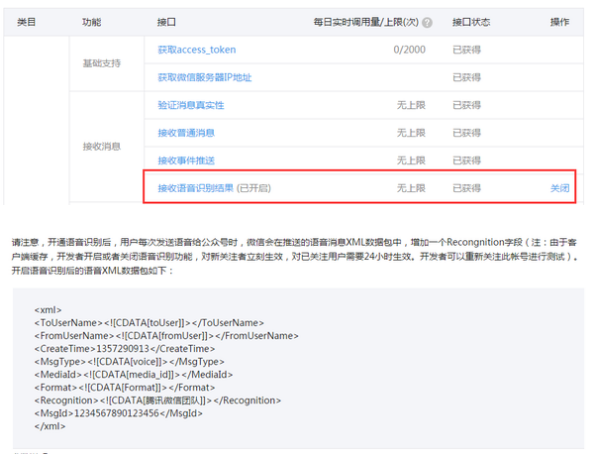
这就意味着我们不需要做太多的修改就可以将接收到的语音消息作为文本信息处理了。
修改weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
#picurl = xml.find('PicUrl').text
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
if msgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
elif msgType == 'voice':
content = xml.find('Recognition').text
try:
msg = takl_api.talk(content, userid)
return self.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), content + '这货还不够聪明,换句话聊天吧')
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
#result = cxkd.cxkd('PQ00708467161')
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+post)
h = r.read()
k = eval(h)
kuaidi = k["auto"][0]['comCode']
'''
j = requests.get('http://www.kuaidi100.com/query?type=huitongkuaidi&postid=280472503105')
l = j.text
#l = j.read()
#m = eval(l)
#outcome = ''
#for c in m['data']:
'''
#outcome = outcome + c['time']+' '+c['context']+'\n'
return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
try:
msg = talk_api.talk(content)
return self.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), '这货还不够聪明,换句话聊天吧')
这里重点就是加上了 elif msgType == 'voice': 这部分。
示例:
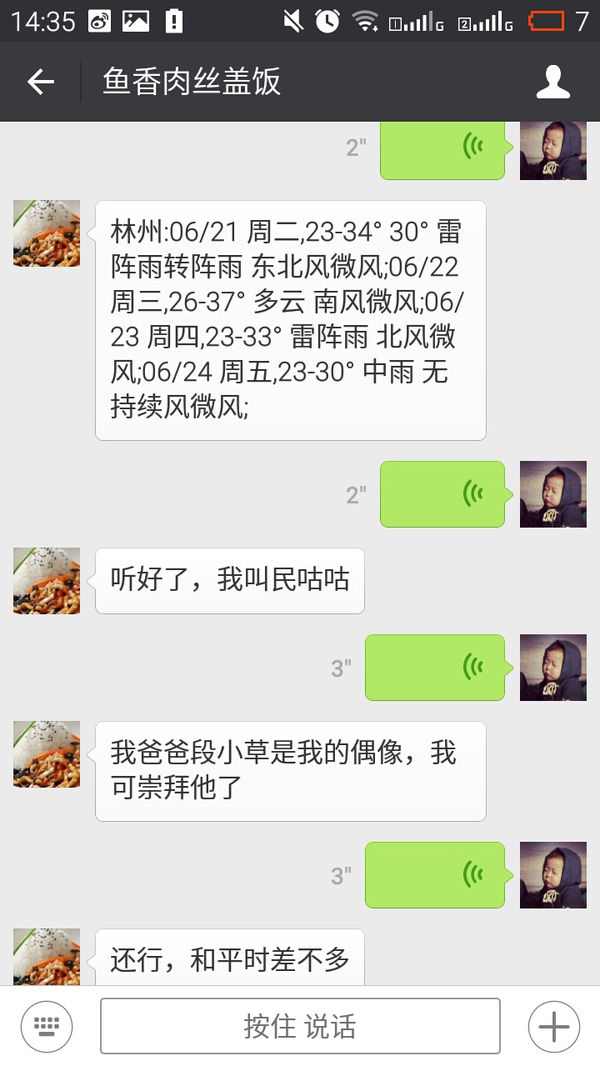
这一步做完以后就已经实现了大部分我想要的功能了,但还是有一点问题,因为机器人并不理解上下文的语义,所以会出现这样的情况:
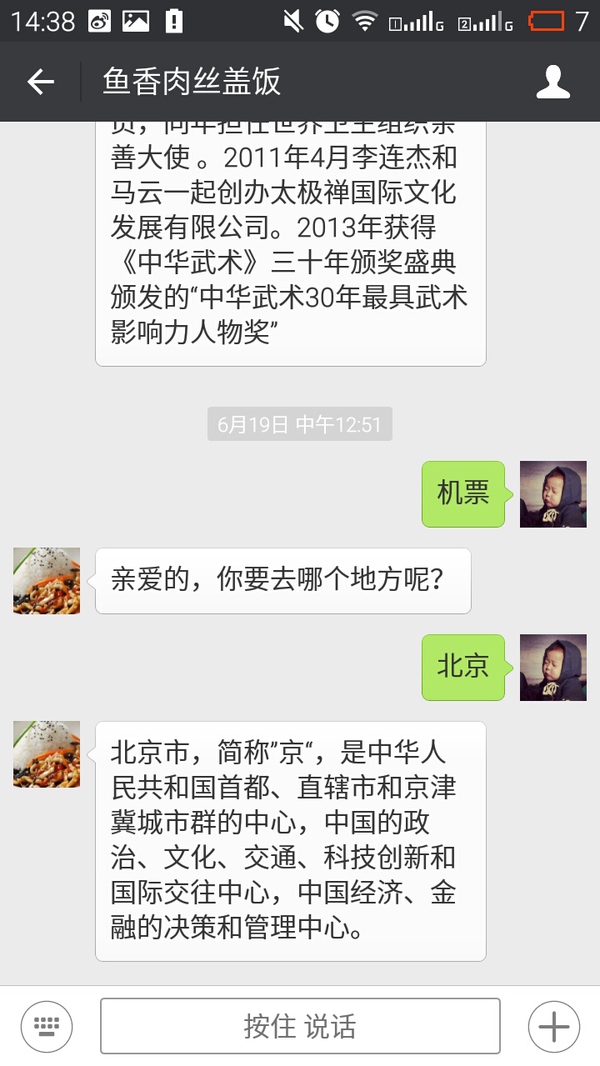
由于机器人并没有理解上下文语义,前一句话问你要去哪儿,你告诉他北京以后他却不知道你是因为什么回复的北京。所以要告诉机器人是谁在跟他聊天。
查看微信和图灵机器人的开发文档可以看到:
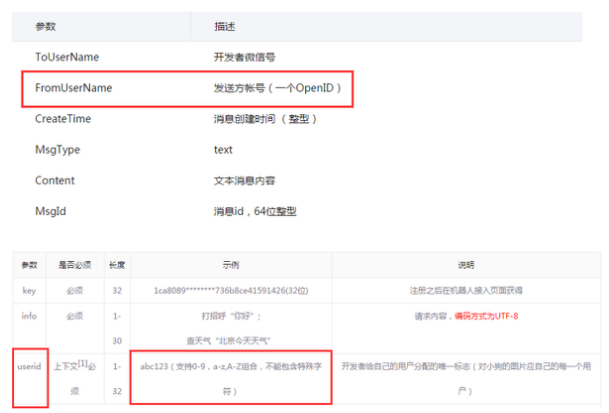
从微信接收到消息是,我们就能够获取到用户的 OpenID 了,只需要将这个 ID 作为 userid 传给图灵机器人 API ,就可以保持上下文对话的语境了。(但是userid只支持0-9和数字,而微信 ID 中带有下划线,所以需要做一些简单处理)
修改talk_api.py (最终):
# -*- coding: utf-8 -*-
import requests
import json
global s
s = requests.session()
def talk(content, userid):
url = 'http://www.tuling123.com/openapi/api'
da = {"key": "your key here", "info": content, "userid": userid}
data = json.dumps(da)
r = s.post(url, data=data)
j = eval(r.text)
code = j['code']
if code == 100000:
recontent = j['text']
elif code == 200000:
recontent = j['text']+j['url']
elif code == 302000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
elif code == 308000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
else:
recontent = '这货还没学会怎么回复这句话'
return recontent
可以看到,我们需要两个参数,content 和 userid 。
修改 weixinInterface.py(最终):
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
userid = fromUser[0:15]
#picurl = xml.find('PicUrl').text
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
if msgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
elif msgType == 'voice':
content = xml.find('Recognition').text
try:
msg = talk_api.talk(content, userid)
return self.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), content + '这货还不够聪明,换句话聊天吧')
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
#result = cxkd.cxkd('')
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+post)
h = r.read()
k = eval(h)
kuaidi = k["auto"][0]['comCode']
'''
j = requests.get('http://www.kuaidi100.com/query?type=huitongkuaidi&postid=280472503105')
l = j.text
#l = j.read()
#m = eval(l)
#outcome = ''
#for c in m['data']:
'''
#outcome = outcome + c['time']+' '+c['context']+'\n'
return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
try:
msg = talk_api.talk(content, userid)
return self.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), '这货还不够聪明,换句话聊天吧')
提交代码即可。
测试:
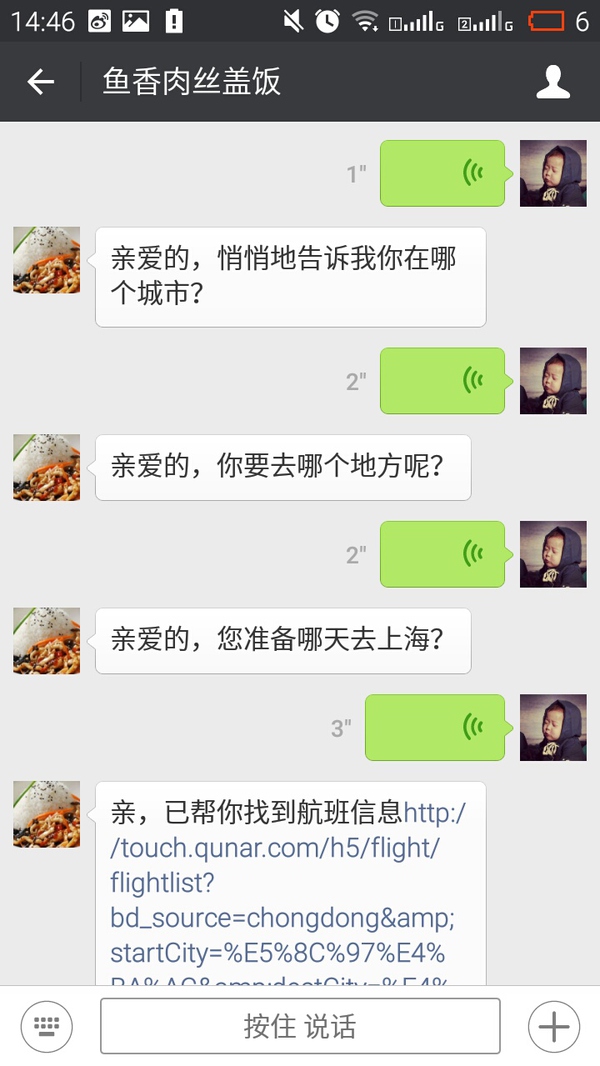
Over.
这篇写的很仓促,有时间会回头整理一下思路,完善一下语言,加几个框图帮助大家理解。
代码还没整理好,整理好会 commit 到 Github 的。
https://github.com/loveQt/wxpytest
想要调戏机器人的可以自己搜微信公众号“鱼香肉丝盖饭”或者“rose-fun”。
就这样吧,也算完了任务。我去给手机充电了~

