前些日子在知乎上看到了一篇文章 Python公众号开发部分代码开源 - 学习编程 - 知乎专栏 。文章里倒是给出了一些可以用的源码,可惜没具体说怎么部署到自己的服务器和公众号,也没有对源码进行应有的解释,自己摸索了几天以后算是成功搭好了一个简单的 python 微信公众号后台,对刚开始的源码进行了一些改善,正好专栏也很久没更新了,写一篇记录一下过程吧。
主要工具:SAE+微信公众号+Git+Python本地环境(最好已经安装好了Git并配置好了Python IDE,比如Pycharm)
1. 工欲善其事
首先要简单介绍一下一些准备工作。
1.1 微信公众号
第一步是要注册一个个人微信公众号(个人账号不支持认证),按照https://mp.weixin.qq.com/ 给出的过程依次填写需要的信息就可以完成申请,如果已有账号的话可以直接登录。
登录以后可以看到左边栏中的自动回复功能:

在一般的使用中,我们可以通过设置关键字实现一些基本的自动回复功能,但是这样的关键字回复远远不能满足我们的实际需求,比如我们要实现一个查快递的功能,必然是要通过调用快递接口对不同用户的不同输入给出不同的输出结果,在这样的情况下关键字回复就显得很鸡肋了。于是我们选择了开发者模式。

在基本配置中,我们只需要修改URL、Token和EncodingAESKey三项配置即可,由于我们现在还没有配好自己的服务器,微信公众号这边的设置到这里暂停,等我们有了服务器获取了地址以后回来填写就可以了。
1.2 SAE
这次我们使用新浪云作为我们的服务器,注册登录https://www.sinacloud.com ,新用户会有一定的优惠云豆,老用户充个十块也足够我们完成很多学习任务了。
选择云应用,进入控制台后创建新应用。
输入二级域名和应用名称(必填项),在下面的运行环境中选择 Python2.7 - 空应用。
成功创建应用后,会获得相应的一些配置数据和密钥,当然这些内容这次用不到,主要用到的就是登陆账号和安全密码。
SAE平台的代码版本控制分为Git和SVN,两者可以自由选择,这次我们选择使用Git进行代码的上传操作。
1.3 Git
对于Windows系统,电脑上如果安装了 Github Desktop 的话,应该就自带了 Git Bash 和 Git Shell 这样的工具,如果之前没有安装过 Git 相关的软件,可以自行搜索 Git 以后安装 Git for Windows。
Git 刚接触时可能很复杂,用起来功能很强大但繁琐,初学者可能绕来绕去就绕晕了,但是在这次的搭建过程中我们其实只需要用到四五条极为简单的命令即可,所以完全无需担心 Git ,也不要让 Git 成为你拒绝迈出第一步的障碍。(关于 SAE 的代码管理,详见https://www.sinacloud.com/doc/sae/tutorial/code-deploy.html#git)
下面就让我们进入到真正的开发阶段吧!
2. 捅破窗户纸
犹记得我大一的时候公众号刚刚兴起,当时我还兴致冲冲地注册了账号,设置了一大堆的关键字自动回复,坚持了数天的图文消息推送,但是当我真正开始研究开发者模式,真正想去调用一些接口时却发现,好像自己该学的也都学了,该用的也都用过,就是串不到一起去,做不出想要的东西来(当时用的好像还是 PHP ),后面一直搁置了公众号这样的东西,一下子就拖到了现在。这两天试了一下 Python 服务器的配置,发现完全就是一层窗户纸,其实一捅就破,完全没有当初的纠结和复杂了。
2.1 服务器配置和 Token 认证
由于我们之前在 SAE 平台创建的是空应用,所以我们需要做一些基础的配置工作。这次我们选择使用 web.py (Python 2.7)来进行服务器搭建,如果本地没有 web.py 库的话可以通过 pip 命令进行安装(pip install web.py)。
之后我们需要创建一个项目,并编辑如下的基本代码。
config.yaml
name: wxpytest
version: 1
libraries:
- name: webpy
version: "0.36"
- name: lxml
version: "2.3.4"
...
index.wsgi
# coding: UTF-8
import os
import sae
import web
from weixinInterface import WeixinInterface
urls = (
'/weixin','WeixinInterface'
)
app_root = os.path.dirname(__file__)
templates_root = os.path.join(app_root, 'templates')
render = web.template.render(templates_root)
app = web.application(urls, globals()).wsgifunc()
application = sae.create_wsgi_app(app)
这两部分是 web.py 的基础配置文件,之后我们需要开始编写实现微信公众平台功能的代码。
新建weixinInterface.py
# -*- coding: utf-8 -*-
import hashlib
import web
import lxml
import time
import os
class WeixinInterface:
def __init__(self):
self.app_root = os.path.dirname(__file__)
self.templates_root = os.path.join(self.app_root, 'templates')
self.render = web.template.render(self.templates_root)
def GET(self):
#获取输入参数
data = web.input()
signature=data.signature
timestamp=data.timestamp
nonce=data.nonce
echostr = data.echostr
#自己的token
token="token" #这里改写你在微信公众平台里输入的token
#字典序排序
list=[token,timestamp,nonce]
list.sort()
sha1=hashlib.sha1()
map(sha1.update,list)
hashcode=sha1.hexdigest()
#sha1加密算法
#如果是来自微信的请求,则回复echostr
if hashcode == signature:
return echostr
编写好这三部分的代码后,我们就实现了最简单的微信平台认证配置,这三部分代码中需要修改的只有 token 字段,需要和你在微信平台中输入的 token 保持一致。(之后有机会再详细写具体的认证过程吧,这次只罗列一下实现过程,需要注意的是认证 token 我们只需要用 GET 方法而之后的发消息需要用 POST 方法。)
这时我们需要把代码上传到 SAE 平台,然后在微信平台进行认证请求。
在文件根目录右键打开 Git Bash,依次输入如下命令,过程中可能会需要输入 SAE 的用户名和安全密码,按照提示操作即可。
git init
git remote add sae https://git.sinacloud.com/yourapp
git add .
git commit -m 'your commit message'
git push sae master:1
之后回到公众平台的开发者页面,填写 URL 为 http://xxxx.sinaapp.com/weixin 填写 Token 与代码中的 token 一致,EncodingAESKey 随机生成,然后点击提交认证,如果上面步骤没有操作错误,这一步就可以认证成功了。
2.2 最简单的消息回复机制
在微信公众号的认证完成以后,就可以针对用户的消息搞一些事情了。(消息类型开发文档详见https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421140453&token=&lang=zh_CN)
用户与公众号之间的消息交互类型分为文本、图片、语音、视频、小视频、地理位置、链接等,本文中主要会用到文本和图片两种消息类型。
用户消息以 XML 形式传至我们搭建好的服务器中,我们需要解析 XML 信息,获取出需要的信息,进行处理后对用户回复结果。
我们先来简单看一下文本消息和图片消息的 XML 结构。
文本:
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[this is a test]]></Content>
<MsgId>1234567890123456</MsgId>
</xml>
图片:
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<PicUrl><![CDATA[this is a url]]></PicUrl>
<MediaId><![CDATA[media_id]]></MediaId>
<MsgId>1234567890123456</MsgId>
</xml>
可以看到,两者共有的字段为ToUserName、FromUserName、CreateTime、MsgType和MsgId,对于文本消息,我们可以通过Content字段直接提取出消息文本内容,但是对于图片消息,我们需要通过PicUrl或MediaId获取图片信息后进行处理。
下面是Python公众号开发部分代码开源 - 学习编程 - 知乎专栏中给出的一个写法:
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
if(content == u"天气"):
pass
我并不推荐这种写法,因为在那篇文章中,作者只针对文本消息进行处理,没有实现对消息类型做相应判断,此时如果服务器接收到图片消息,content=xml.find("Content").text 就会执行失败,返回错误信息,导致公众号无法正常工作,所以,更好的写法是先进行消息类型判断后执行相应的操作。
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
if msgType == 'text':
content=xml.find("Content").text
if(content == u"天气"):
pass
elif msgType == 'image':
pass
else:
pass
获取到用户发送的消息后,我们需要考虑如何给用户发消息,其实并不难,我们只需要给定一个消息模板,并在相应的功能最后设置返回值即可
return self.render.reply_text(fromUser,toUser,int(time.time()), 'you string here')
在目录下新建 templates/reply_text.xml
$def with (toUser,fromUser,createTime,content)
<xml>
<ToUserName><![CDATA[$toUser]]></ToUserName>
<FromUserName><![CDATA[$fromUser]]></FromUserName>
<CreateTime>$createTime</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[$content]]></Content>
</xml>
然后编辑weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
if msgType == 'text':
content=xml.find("Content").text
return self.render.reply_text(fromUser,toUser,int(time.time()), content)
elif msgType == 'image':
pass
else:
pass
以上操作的功能为:判断用户消息类型,如果消息类型为文本,则获取其内容content,并原样返回 content 作为消息。
完成以上修改后,重复 git 操作将修改 push 到远程仓库即可。
git add .
git commit -m 'your commit message'
git push sae master:1
测试效果图:
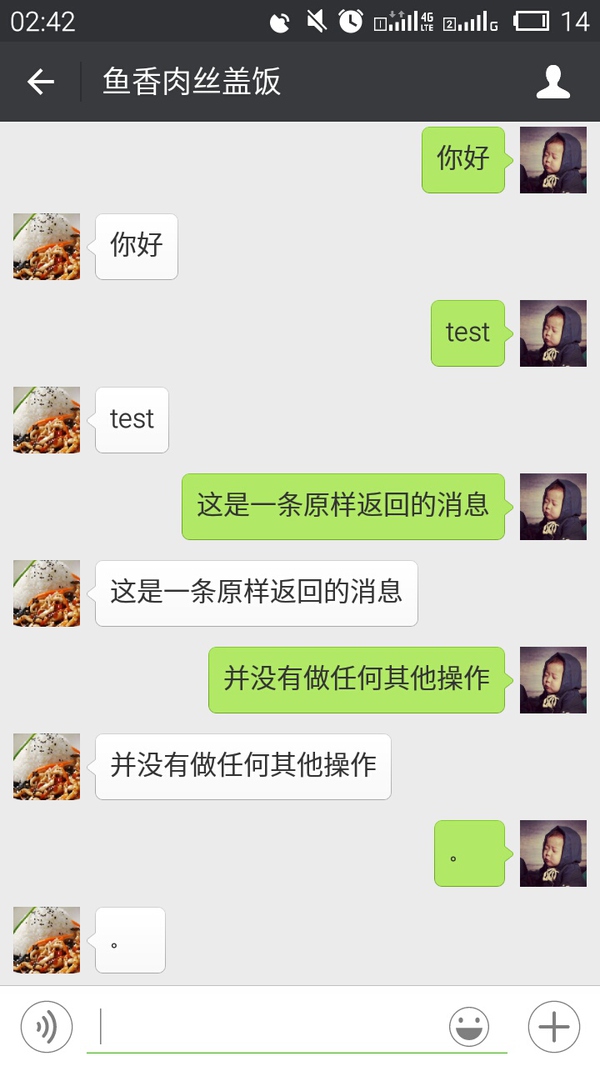
2.3 文本消息操作小例——查快递
上一小节我们已经完成了对文本消息最基础的操作,但是原样返回内容,并没有做任何更多的操作,这一次我们来试试快递接口。
我使用的依然是前文中提到的文章中的 kuaidi100 查快递接口,不过我在本地测试了许多次通过但是 SAE 的服务器依然无法返回正常结果,在网上搜了很久发现时 快递100 封掉了来自 SAE IP 段的请求,也就是说那个接口不能用了,那段代码也废掉了。所以我们只能退而求其次,做一个通过快递单号判断快递公司的功能。
依然是修改weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
if msgType == 'text':
content=xml.find("Content").text
if content[0:2] == u"快递":
post = str(content[2:])
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+post)
h = r.read()
k = eval(h)
kuaidi = k["auto"][0]['comCode']
return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
elif msgType == 'image':
pass
else:
pass
上面的功能很简单,就是判断用户消息如果前两个字为快递,则取出后面的字符串作为快递单号,通过接口查询后返回结果发送给用户。重复 git 命令更新远程代码后测试效果图如下:
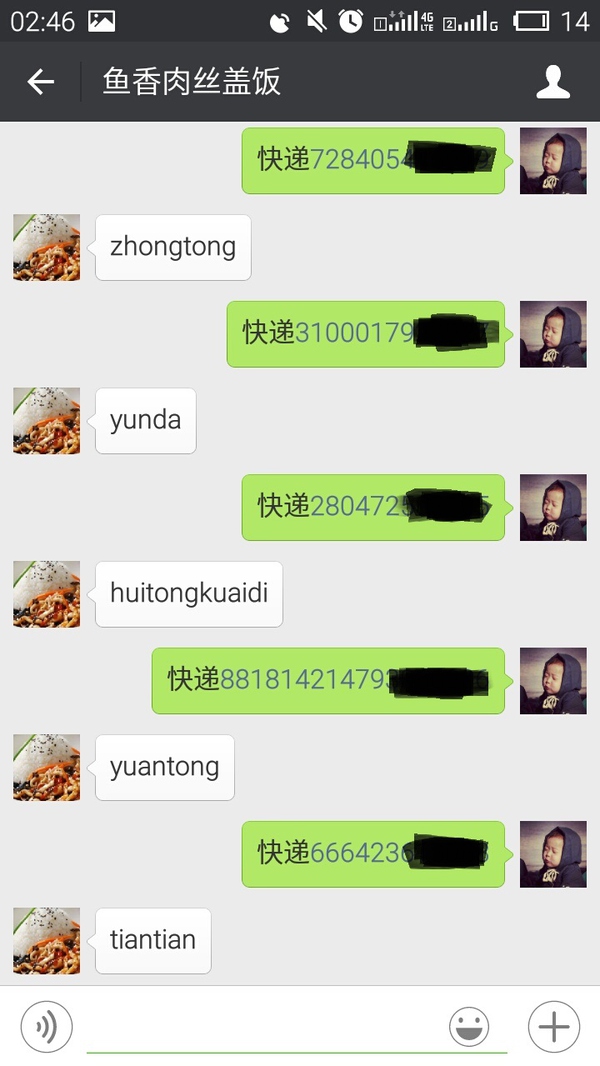
到此我们就完成了第一部分,服务器搭建和一些简单的文本消息操作。
其实对于有一定编程能力的小伙伴来讲,捅破了这层窗户纸以后,其实就能根据自己以前的兴趣和经验做出许多自己喜欢的东西来了。Enjoy coding!
3. 曲径通幽处
上面完成对文本消息的一些基础操作后,我们可以尝试做一些更有趣的事情了。之前说到 Python公众号开发部分代码开源 - 学习编程 - 知乎专栏 中的源码在最开始就漏掉了 msgType 的判断,除此之外原作者还使用了极度过程化的写法和极度臃肿的代码结构,这一部分我们会尝试添加第三方的依赖包,尝试通过抽出函数方法来结构化代码,最后尝试对图片消息进行处理。
3.1 添加第三方依赖包
在上面的接口调用中,我们用到了 urllib2 库,但是熟悉 Python 爬虫的都知道,我们最常用到的其实是第三方的 requests 库,那么怎么把第三方库添加到 SAE 空间中呢?参阅了开发文档以后得到答案:https://www.sinacloud.com/doc/sae/python/tools.html#tian-jia-di-san-fang-yi-lai-bao
具体做法不一定拘泥于官方给出的步骤,可以自己在本地仓库新建文件夹 vendor ,然后使用pip -t 选项指定第三方库安装地址,最后添加路径到 index.wsgi文件中。
以安装 requests 为例。

之后编辑 index.wsgi,在顶部添加代码即可。
# coding: UTF-8
import os
import sae
import web
sae.add_vendor_dir('vendor')
from weixinInterface import WeixinInterface
有了这些第三方依赖库,我们就能更加轻松地实现需要的功能了。
3.2 函数的结构化方法
文本消息很多,我们如果不断地添加判断,作出一些操作并返回结果,代码势必变得极其臃肿,既不利于阅读,更不利于调试代码。于是我们尝试将之前已有的通过快递单号查询公司的代码改写为函数。
新建 cxkd.py
import urllib2
def detect_com(postid):
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+postid)
h = r.read()
k = eval(h)
kuaiditpye = k["auto"][0]['comCode']
#print kuaiditpye
return kuaiditpye
修改 weixinInterface.py,导入 cxkd.py 并修改源代码。
import cxkd
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
if msgType == 'text':
content=xml.find("Content").text
if content[0:2] == u"快递":
post = str(content[2:])
kuaidi = cxkd.detect_com(post)
return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
elif msgType == 'image':
pass
else:
pass
经过测试这种写法是可行的。显然代码量较大的情况下,这样的写法可以使代码更加简洁易懂,便于修改调试。
3.3 旧瓶装新酒——再谈人脸识别
在我很久一篇的专栏中(Python 爬虫笔记(2):插播——我也来做Facemash! - 小段同学的杂记 - 知乎专栏)曾经提到过微软的 How-old.net 人脸识别的接口,当然那个接口是我自己通过抓包拿到的,那篇文章赞数寥寥,平时好像也没见谁拿那个接口实现过什么功能,这次想起来要处理图片消息,我第一个便又想起来那个接口。
旧瓶装新酒,能饮一杯无。
接口的详情可以到上文的链接中查看,这里直接给出代码好了。
新建 imgtest.py
# -*- coding: utf-8 -*-
import requests
import re
def imgtest(picurl):
s = requests.session()
url = 'http://how-old.net/Home/Analyze?isTest=False&source=&version=001'
header = {
'Accept-Encoding':'gzip, deflate',
'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0",
'Host': "how-old.net",
'Referer': "http://how-old.net/",
'X-Requested-With': "XMLHttpRequest"
}
data = {'file':s.get(picurl).content}
#data = {'file': open(sid+'.jpg', 'rb')}
#此处打开指定的jpg文件
r = s.post(url, files=data, headers=header)
h = r.content
i = h.replace('\\','')
#j = eval(i)
gender = re.search(r'"gender": "(.*?)"rn', i)
age = re.search(r'"age": (.*?),rn', i)
if gender.group(1) == 'Male':
gender1 = '男'
else:
gender1 = '女'
#print gender1
#print age.group(1)
datas = [gender1, age.group(1)]
return datas
修改 weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
if msgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
kuaidi = cxkd.detect_com(post)
return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
return self.render.reply_text(fromUser,toUser,int(time.time()), content)
然后 git 提交到远程仓库。测试如下:
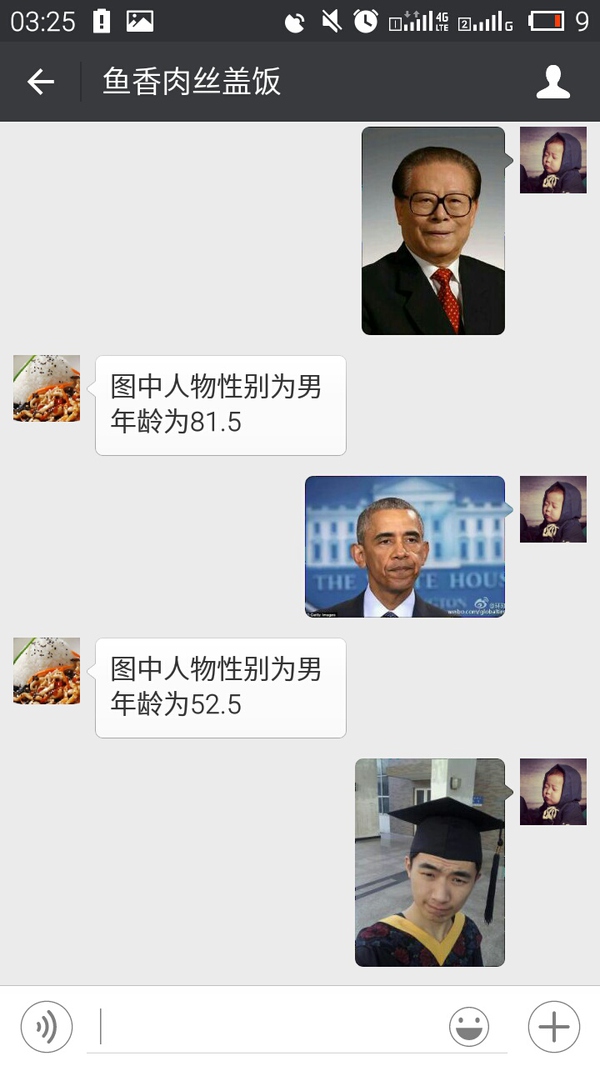
4. 鱼香肉丝盖饭
You share rose get fun.
以前也有舍友问我说,你说你为什么要在网上帮别人完一些任务,你这是在害他们啊。
我说并没有啊,我写 如何用Python写一个抓取新浪财经网指定企业年报的脚本? - 知乎用户的回答 时的结果都是空的,写 如何用爬虫下载武汉市环保局空气污染数据? - 知乎用户的回答 的时候只给了几个月的结果。其实教学相长,我自己是一个学习的过程,如果能顺便帮到别人,自然是好事啊。
分享是一种很可贵的东西吧。以前的知乎很好,我也不去评价现在的知乎了。但是我还是愿意分享一些东西出来,虽然可能原创的成分不高,可能都是拼拼凑凑,也可能水平很低,但是都是我学习的一些经历吧,如果能让别人少走一些弯路,或者激起别人的兴趣,都是很功德的事情。
想了想还是把这次的所有代码贴到 Github 了,平时也不怎么用 Github ,不过怕知乎的编辑器复制粘贴给大家带来麻烦。
GitHub - loveQt/wxpytest
也可以看出来这次的所有文档结构:(Chrome插件 Octotree)
最后留一下这次开发中用到的公众号(鱼香肉丝盖饭 rose-fun),算是我的个人公众号,做着玩儿的,关不关注无所谓,因为平时也不怎么写东西推东西。源代码已经贴出来了,照着文章几分钟能搭出来一个一模一样的。
现在的功能就三块,更多的东西还没加:
1、回复 快递xxxxxx 自动识别快递公司
2、发送图片 识别性别和年龄
3、其他文字信息 原样返回
http://weixin.qq.com/r/MDqnv3PEsy7MrTfc928i (二维码自动识别)
知乎加了二维码自动识别…
To-dos:
配置 SAE 本地开发环境。因为 push 一次在线调试一次太麻烦了。
完善开发公众号其他功能。
(当然按照我这爱跳票的性子不知道到什么时候了…)
文章参考了许多网上的文章,和一些别人的源码,多数原始出处不可考证,只贴出我所参考的链接。
http://my.oschina.net/yangyanxing/blog/159215
Python公众号开发部分代码开源 - 学习编程 - 知乎专栏
Python 爬虫笔记(2):插播——我也来做Facemash! - 小段同学的杂记 - 知乎专栏
