
1.前言
最近一直在更新数据挖掘一些事一些情系列,包括有:
就在浩彬老撕写得不亦乐乎之际,有两位“热心粉丝”出现了,他们表示模型做好了,但是怎么部署是个大问题~
嗯,所以浩彬老撕决定这期“愉快地”谢谢SPSS Modeler模型部署那些事~
确实,在模型建好以后并不意味着结束,我们还需要进一步地把模型部署到合适的环境当中。
更进一步地,浩彬老撕也多次谈到建立好的模型并不是一成不变的,即使模型结构不发生任何变化,但是我们也会希望,在经过一段时间后,模型能够根据新的数据进行适当的更新,但是这个事情如果都需要个人手工打开modeler客户端再点击作操作的话,不仅耗时麻烦,而且还容易出错,因此我们就需要一个可以自动化部署运行的方式了,最好可以设定定时运行~

2.批处理模式概述
2.1适用情况
首先,一般来说Modeler的批处理模式一般适用于如下的3种情况:
- 已经建立好模型,需要定期更新,如每每周一次,每月一次重新进行模型训练;
- 考虑到计算机资源分配问题,需要要在夜间或特定的空闲时段运行;
- 针对计算量较大的模型,需要在后台处理;
2.2批处理模式工具
其次,批处理模式我们需要用到“ClemB”,即Clementine Batch

那么“ClemB”在哪里可以找到呢?(放心,这是免费使用的功能~)
我们知道SPSS Modeler时一个典型的C/S架构(客户端与服务器架构),可以分为Modeler Server以及Modeler client,因此“ClemB”也分别适用于在客户端与服务器端的情况:
1. 客户端:在SPSS Modeler client端安装后,我们可以到Modeler的安装目录,bin文件夹下找到,以17.0版本为例,如果你安装采取的是默认路径,则可以在:C:\Program Files\IBM\SPSS\Modeler\17\bin 找到;
2. 服务器端:由于服务器端本身再并没有带“ClemB”,因此,如果你想利用服务器端的计算资源进行自动化运行的话,你可以选择(1)使用在客户端的“ClemB”或(2)安装另一个Modeler Server的插件IBM SPSS Modeler Batch。在安装该插件后,你可以在当中的bin文件下找到“ClemB”,如果你安装采取的是默认路径,则可以在:C:\Program Files\IBM\SPSS\ModelerBatch\17\bin 找到;
2.3 批处理模式步骤
最后简要介绍利用批处理模式过程的步骤
1. 构建好需要运行的流文件;
2. 编写需要执行的脚本文件;
3.利用Windows的计划任务程序,设定自动执行任务;
3. 具体案例及代码
3.1 构建好需要运行的流文件;
该流是以Modeler示例中的druglearn.str修改而成,为检验结果,在模型之后接Excel导出节点。
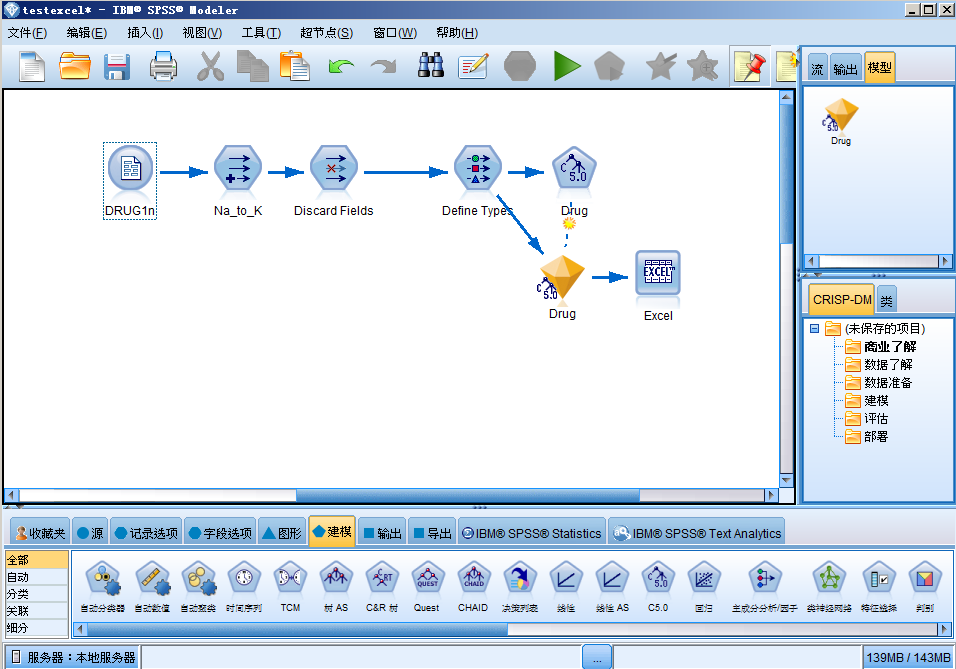
3.2编写需要执行的脚本文件;
(1)新建一个.txt文本文件;
(2)输入如下命令行;
cd C:\Program Files\IBM\SPSS\Modeler\17\bin
clemb -client -hostname winpc -port 28054 -username haobin -password 12345678 -stream "C:\IBM\testexcel.str" -execute
对于第一行代码,是定位于clemb位置,具体执行为第二段代码;
低于第二段代码,各参数前有-分割,各参数作用如下:
- clemb:调动clemb;
- client:由于此处调用的是Modeler client端运行,所以为client。若调用的是server,则改为server;
- hostname:主机名;
- port:SPSS Modeler:主机的端口号;
- usename:主机登录用户名;
- password:主机登录密码;
- stream:需要调用的流文件(包括详细路径及名称)
- execute:执行
(3)将该.txt文件修改后缀为.bat,例如:testexcel for client.bat
3.3利用Windows的计划任务程序,设定自动执行任务;
控制面板 -> 所有控制面板项 -> 管理工具 ->任务计划程序
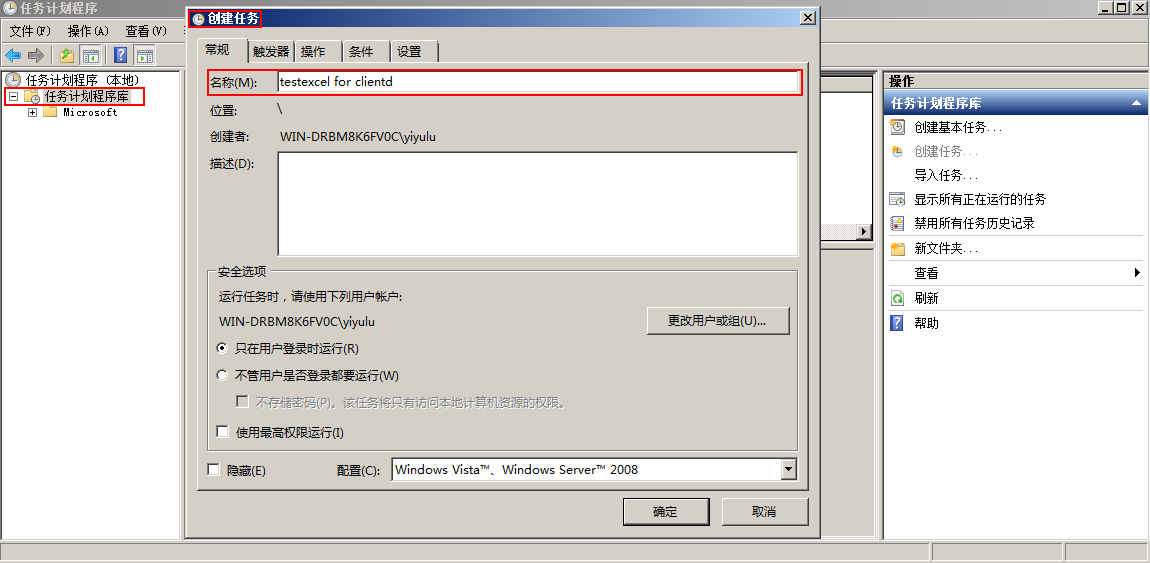
(1)创建任务
(2)新建触发器,设定为2017/01/13开始,每周运行一次
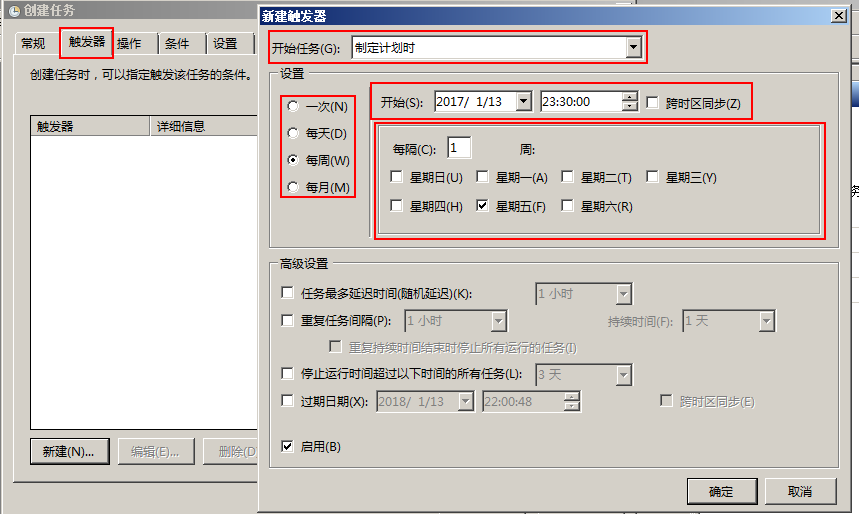
设置好后按确定,即可完成自动运行任务。
4. 含有数据库的应用案例及帮助
当流当中,包含有数据库数据源的时候,会需要在数据源中需要输入密码,因此脚本文件需要额外的参数。
4.1 构建好需要运行的流文件;
与第三节一样,构建好需要的流,只是该示例中的数据源和最后目标都是数据库节点。
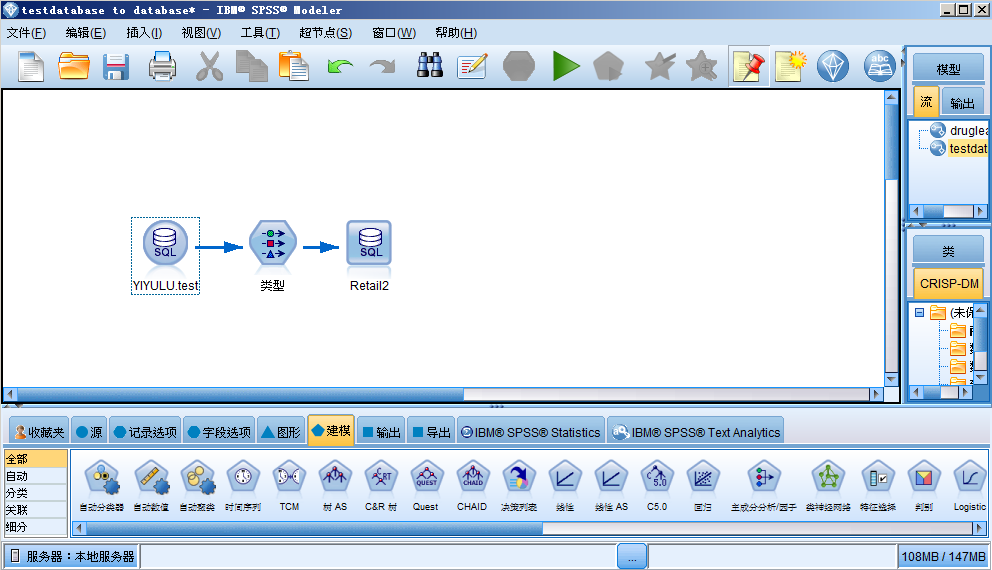
4.2编写需要执行的脚本文件;
(1)新建一个.txt文本文件;
(2)输入如下命令行;
cd C:\Program Files\IBM\SPSS\ModelerBatch\17\bin
clemb -server -hostname 192.168.199.201 -port 28054 -username haobin -password 12345678 -stream "C:\IBM\testdatabase to database.str" -P:databasenode.datasource={"Retail",haobin,12345678,False} -execute
为了案例多样性,此处我们调用的是Modeler batch的“clemb”
特别地针对第二段代码,可以看到
- server:调用了server端
- -P:databasenode.datasource={"Retail",haobin,12345678,False}:分别对应数据源名称,数据库用户名,登录密码(并不是前面主机的登录用户和密码,尽管示例是刚巧一样);最后一项参数与经过加密的密码配合使用。 如果将其设为 true,将会在使用之前对密码进行解密。
(3)将该.txt文件修改后缀为.bat,例如:testdatabase to database.bat
4.3执行任务及日志文件;
自动执行任务与3.3内容一样,这里不再详述;而如果需要检查脚本是否能够正确运行,可以直接点击.bat文件,查看运行成功还是出现报错。
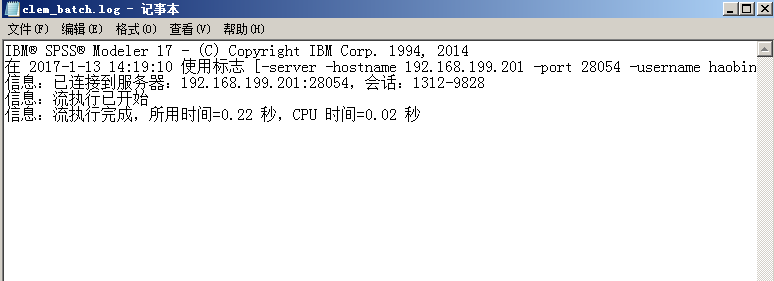
另外,对应的执行日志在“clemb”对应的文件夹,名为:clem_batch.log,打开后可以查看运行结果:
近期热门文章精选(点击标题即可阅读):
1.R vs Python:R是现在最好的数据科学语言吗?
2.干货教程|可能是最方便好用的文字云工具
3.可视化干货|可能是最好玩的像素地图
4.(理论+案例)如何通俗地理解极大似然估计?
5.XGBoost 与 Boosted Tree

作者简介:浩彬老撕
好玩的IBM数据工程师,
立志做数据科学界的段子手,
致力知识分享,每月至少一次送书活动


