前言
上一篇写到了mysql与python的简单交互
还讲到了一些基础的面向对象设计
这两天探索了一下,发现如果是用pandas做数据分析
简单的几行代码即可将mysql的数据导入pandas进行分析
前文传送门:Python操作Mysql数据库入门——查看和增加记录
环境
Python 3.X
IDE : juyter notebook
使用Python连接数据库
import MySQLdb
import pandas as pd
#使用python连接数据库
conn = MySQLdb.connect(
host = '127.0.0.1',#本地地址
user = 'root',#一般默认用户名
passwd = '********',#本地数据库登录密码(这里用你自己的密码!!!)
db = 'test',#数据库名称(这里用你自己的数据库名称!!!)
port = 3306,#安装mysql默认的端口号
charset = 'utf8'#设置数据库统一编码
)
sql = 'SELECT * FROM `tdb_goods`;'
df = pd.read_sql(sql,conn)
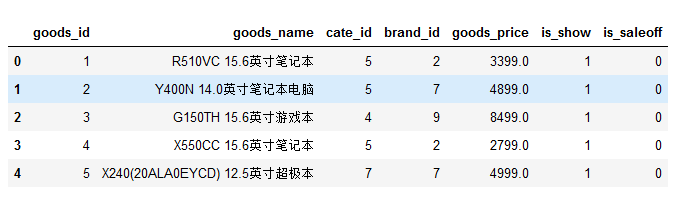
导入表中所有数据并查看前五行
sql = 'SELECT * FROM `tdb_goods`;'
df = pd.read_sql(sql,conn)
df.head()
选你所想
一般来说,学sql增删查改基础中,查用的比较多,接下来我们简单使用一些sql查询
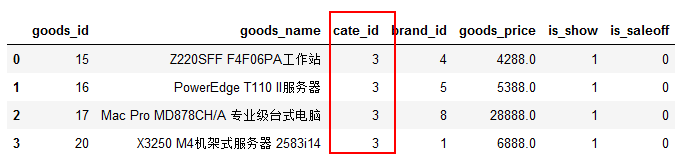
查找cate_id=3的记录:
sql1 = 'SELECT * FROM `tdb_goods` WHERE `cate_id` = 3;'
df1 = pd.read_sql(sql1,conn)
df1
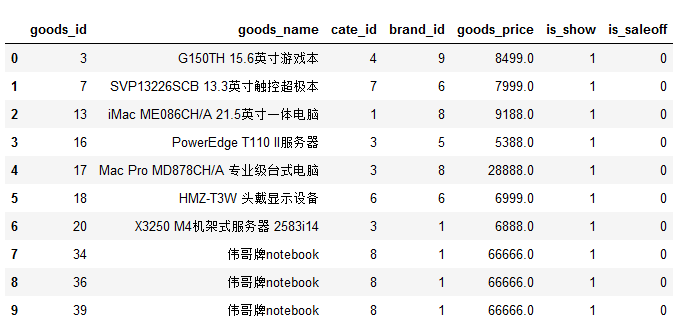
查找价格大于5000的商品,注意这里默认按照goods_id排序的:
sql2 = 'SELECT * FROM `tdb_goods` WHERE `goods_price` > 5000;'
df2 = pd.read_sql(sql2,conn)
df2
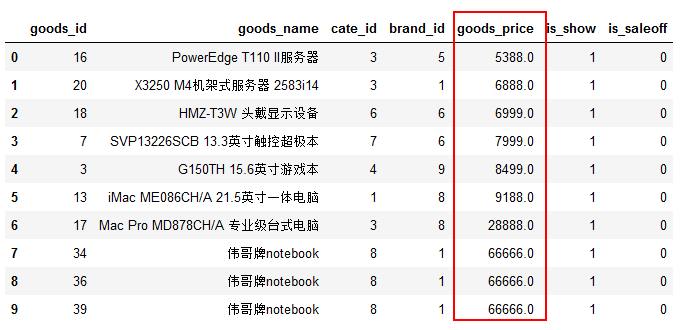
加上ORDER BY `goods_prices`之后,就是按照价格升序排列:
sql2 = 'SELECT * FROM `tdb_goods` WHERE `goods_price` > 5000 ORDER BY `goods_price;'
df2 = pd.read_sql(sql2,conn)
df2
sql默认的是按照升序排列,如果想按照降序排列,可以这样写:
sql2 = 'SELECT * FROM `tdb_goods` WHERE `goods_price` > 5000 ORDER BY `goods_price` DESC;'
df2 = pd.read_sql(sql2,conn)
df2
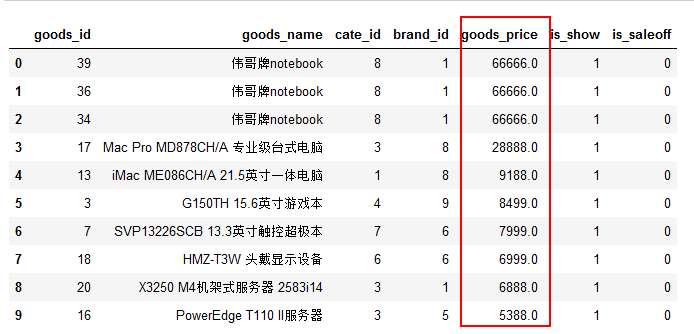
查找所有的平板电脑:
sql3 = 'SELECT * FROM `tdb_goods` WHERE `goods_name` like "%平板电脑%";'
df3 = pd.read_sql(sql3,conn)
df3

将数据库文件导出成csv
df.to_csv('E:\goods_info.csv', encoding = 'utf-8', index = False)

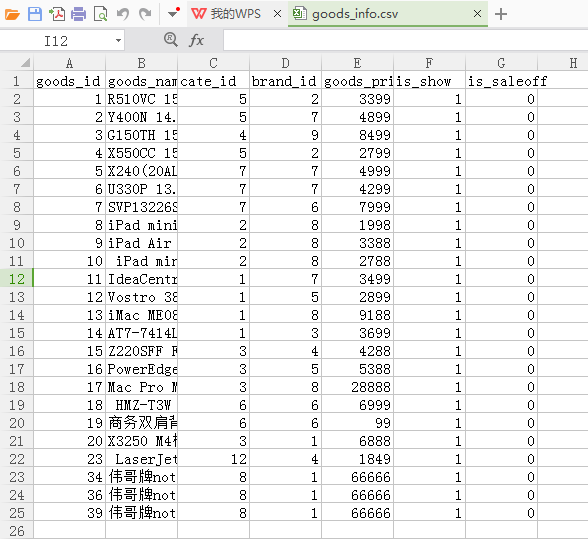
可以看到,数据成功导出成csv了~
最后养成好习惯,断开与数据库的连接:
conn.close()
我们再次查询,发现报错了,说明确实已经断开了连接:
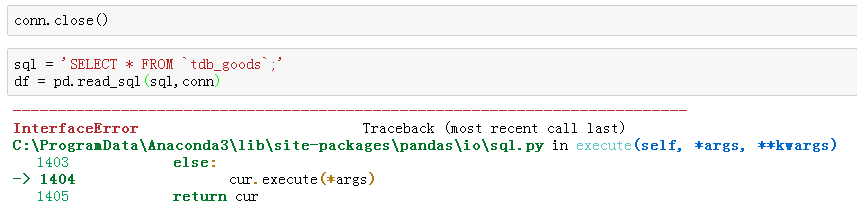
如果运行代码报错,很可能是你的数据库名和数据库登录密码没有修改~
文中如有错误和叙述不妥之处,望指正。
