前言
这个故事的开始是一个师姐(现在是本校图书馆老师)想要看看图书馆的被借过的书和没被借过的书的特征
可能是想为之后图书馆采购书籍做个参考。
于是当师姐找到我时
我欣然接受这个task啦~
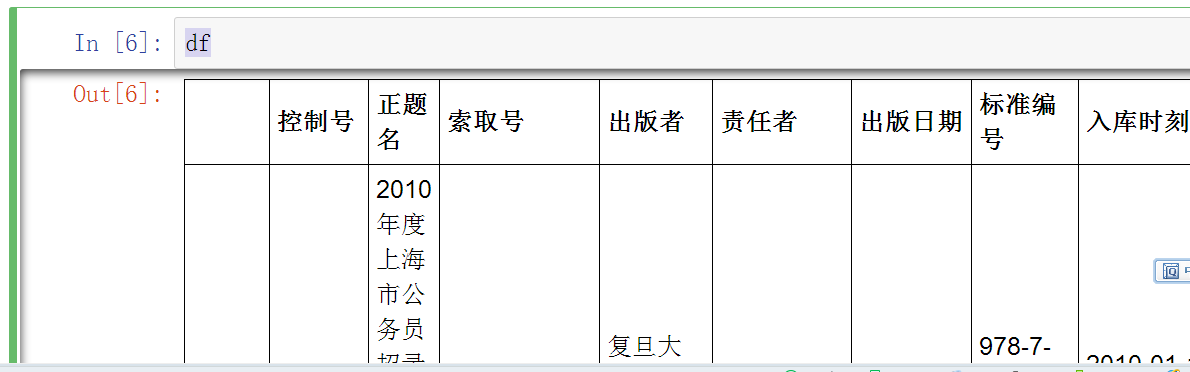
首先,她给我两个excel文档

打开是这样的:

不重要和敏感信息已经打码脱敏~
pandas大法好
接下来,就要使用Python中学过的pandas啦~
在使用pandas过程中,感谢@秦路老师和@诛胖土豆的深夜指导!
import pandas as pd
import numpy as np
df=pd.read_excel("被借过的书.xlsx")#如果不是放在jupyter notebook目录里,要加上相应路径
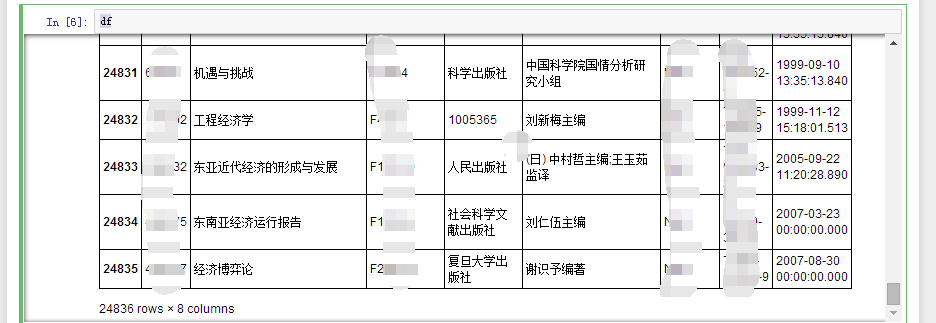
df#看看效果
我选择jupyter notebook作为IDE 而不是pycharm,就是因为喜欢它的可视化展现和保存执行结果
处理思路:将正题名一列的名字全部合成一条字符串,然后分词。
a=''.join(df['正题名'])#使用join()方法将df正题名一列名字顺序连接起来放在字符串a中
a#看一下a的内容

分词处理
import jieba#导入jieba分词模块,安装和简单使用方法已经在我之前的文章里说过啦~
统计词频
思路:建立一个空字典,用jieba的精准模式分词通过key存分出来的词,value存词频,最后打印词和对应词频
wordsall = {} #define return dic
seg_list = jieba.cut(a, cut_all=False)
rowlist = ' '.join(seg_list)
words = rowlist.split(' ')
for word in words:
if word !=' ':
if word in wordsall:
wordsall[word]+=1
else:
wordsall[word] = 1
wordsall = sorted(wordsall.items(), key=lambda d:d[1], reverse = True)
for (word,cut) in wordsall:
print ('%s:' % word,cut)
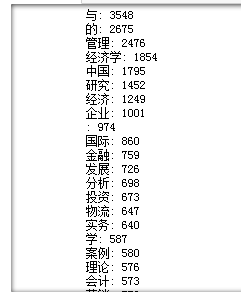
被借过的书分析结果如下:
没被借过的书分析结果如下:
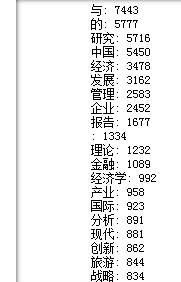
通过观察可以发现:有与、的等无意义的词也被统计了,管理、经济、中国、研究等词在被借过的书和没被借过的书里都高频出现,说明图书馆有很多类似字样的书,而投资、物流、会计等在被借过的书中高频出现,而报告、产业、国际、现代等词在没被借过的书中高频出现,这为图书馆新采购书提供了一点点点点点点参考。
