我们在学习别人家的代码时,总是看到大神对数组各种犀利的取值、赋值、维度变换,看得我们眼(yi)花(lian)缭(meng)乱(bi),毫(zhua)无(er)脾(nao)气(sai)。有的时候,大神用[::3],有的时候又用[:,:,3],更加逆天的是还有[...,3],这个“...”又是什么?难道大神的代码会自动隐藏核心代码,以“...”取而代之?还让不让人活了?佩服佩服。今天我们就来总结一波list和numpy数组的“:”操作。
先看list的“:”
list[:]
先从简单的来,相信大家用的也多。新建一个list变量a。比如
a = [0,3,8,11,15,16,20,17,28]
a[:n]意思是取出a中的前n个元素,当n>len(a)时,不会报错哦,会返回a的所有元素。
a[:2]
输出[0, 3]
a[:2000]
输出[0, 3, 8, 11, 15, 16, 20, 17, 28] 。
如果
a[:-3]
意思是取出a从第0个元素到倒数第三个元素之前的元素,即[0, 3, 8, 11, 15, 16]。而当n<-len(a)时,返回[],这很好理解。
接下来a[:n]表示输出a的从第n个元素到最后一个元素,例如
a[2:]
输出[8, 11, 15, 16, 20, 17, 28]。
a[-2:]输出后2个元素。同样的,如果abs(n)>len(a)也不会报溢出错误,和上述情况相同。
那么,a[:]是啥玩意呢?
a[:]输出的信息和a是一样的。a[:]可以看作是对a的复制,而不是a本身。举个栗子:
a = [1,2,3]
b = a
a[0] = 0
print(b)
输出为[0, 2, 3]。这说明b仅仅是对a的引用。
而如果写成这样:
a = [1,2,3]
b = a[:]
a[0] = 0
print(b)
输出就是[1, 2, 3]。此时b相当于对a的复制,改变a不会对b产生影响。
list[::]
接下来是“::”了,这是啥玩意?其实list[::]的意思是list[start:end:step],其中,
-start:起始位置,默认=0;
-end:结束位置,默认=list的长度;
-step:步长,默认=1;
因此,a[::]就相当于是从a的第一个元素开始,到最后一个元素为止,一步一步的输出a的所有元素。
a[::2] (等价于a[0:len(a):2])就是每两跳输出一个值,即[0, 8, 15, 20, 28]。
再看numpy
这是重头戏。不论是keras、pytorch还是tensorflow,都对张量(即高维矩阵)有维度操作。有些框架对张量的操作是继承于numpy;有些和numpy的操作极为类似。因此如果想在深度学习中对张量灵活操作,需要好好理解这一块的内容。
import numpy as np
a = np.arange(9).reshape(3,3)
print(a)
输出为
[[0 1 2]
[3 4 5]
[6 7 8]]
是一个3x3的二维array。
先来一个简单的栗子
a[:,2]的输出是[2 5 8]。注意是a[:,2]而不是a[:2],有个逗号在里面,这是对维度进行操作的显著标志。
怎么理解呢?在这种情况下,把“:”理解为all,然后从后往前看可能会更清晰一点。比如在a[:,2]中,从后往前看2表示取出第1维的第2列,“:”表示取出第0维的所有列。这样就会得到[2 5 8]。
画图说明,来个大的!
a = np.arange(120).reshape(2,3,4,5)
得到shape为(2,3,4,5)的张量a,输出a为:
[[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[ 10 11 12 13 14]
[ 15 16 17 18 19]]
[[ 20 21 22 23 24]
[ 25 26 27 28 29]
[ 30 31 32 33 34]
[ 35 36 37 38 39]]
[[ 40 41 42 43 44]
[ 45 46 47 48 49]
[ 50 51 52 53 54]
[ 55 56 57 58 59]]]
[[[ 60 61 62 63 64]
[ 65 66 67 68 69]
[ 70 71 72 73 74]
[ 75 76 77 78 79]]
[[ 80 81 82 83 84]
[ 85 86 87 88 89]
[ 90 91 92 93 94]
[ 95 96 97 98 99]]
[[100 101 102 103 104]
[105 106 107 108 109]
[110 111 112 113 114]
[115 116 117 118 119]]]]
假如我要输出a[:,2,:,4],从后往前看就是,取出最后一维的第4列(红色框),取出第2维所有列,取出第1维的第2列(黄色框),取出第0维的所有列。

最后输出的结果就是红黄框交界的地方的值:
[[ 44, 49, 54, 59],
[104, 109, 114, 119]]
同时也可以看到,输出结果的shape变成了两维。因此对于一个numpy多维array,[:,:,:,:,...,:],将多少个“:”替换为具体的值,最后的结果就降低几维。
“...”在numpy中的操作
“...”在什么地方出现呢,当你要处理的多维array维度过高,而且你只处理其中的前几维或后几维,那么剩下的维度,就可以用“...”代替了。比如a[1,...]就是将a第0维的第1列取出,得到
[[[ 60 61 62 63 64]
[ 65 66 67 68 69]
[ 70 71 72 73 74]
[ 75 76 77 78 79]]
[[ 80 81 82 83 84]
[ 85 86 87 88 89]
[ 90 91 92 93 94]
[ 95 96 97 98 99]]
[[100 101 102 103 104]
[105 106 107 108 109]
[110 111 112 113 114]
[115 116 117 118 119]]]
花式索引取值
对于这样一个代码:
#a还是取上一小节的值,即shape=(2,3,4,5)
a[[0,1],[1,2]] = 1
print(a)
输出:
[[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[ 10 11 12 13 14]
[ 15 16 17 18 19]]
[[ 1 1 1 1 1]
[ 1 1 1 1 1]
[ 1 1 1 1 1]
[ 1 1 1 1 1]]
[[ 1 1 1 1 1]
[ 1 1 1 1 1]
[ 1 1 1 1 1]
[ 1 1 1 1 1]]]
[[[ 60 61 62 63 64]
[ 65 66 67 68 69]
[ 70 71 72 73 74]
[ 75 76 77 78 79]]
[[ 80 81 82 83 84]
[ 85 86 87 88 89]
[ 90 91 92 93 94]
[ 95 96 97 98 99]]
[[100 101 102 103 104]
[105 106 107 108 109]
[110 111 112 113 114]
[115 116 117 118 119]]]]
a[[0,0],[1,2]]的意思就是对维度=(0,1,...) ,和维度=(0,2,...)的元素都赋值为1。简单来说,可以将a[[0,0],[1,2]]看作是a的索引坐标,即a[x,y], 其中 x=[0,0], y=[1,2]。x和y的个数必须相等,因为是一一对应的。当然了,还可以是a[x,y,z],也可以是a[x,y,z,w]的形式,因为a是四维的,只要x,y,z,w的值不要超过2,3,4,5就可以了(因为a的shape=(2,3,4,5))。
对索引的操作还可以用
num = a[np.ix_([0,1],[0,1,2],[0,1])]
表示对(0,0,0,...),(0,0,1,...),(0,1,0,...),(0,1,1,...),(0,2,0,...)等位置上的元素进行赋值1操作。大家可以输出看一下,这里就不再贴结果了。
太大了,来个小点的栗子
a = np.arange(24).reshape(2,3,4)
print(a)
a为
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
试验两个骚操作:
a[:,0,1] = 99
print(a)
它的意思是:
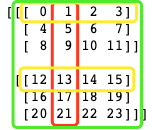
嗯,就是将1和13所在的位置赋值为99。
[[[ 0 99 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 99 14 15]
[16 17 18 19]
[20 21 22 23]]]
而!
a[:,[0,1]] = 99
是对下图红框内的元素进行骚操作,赋值为99
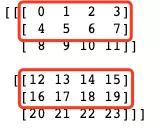
得到:
[[[99 99 99 99]
[99 99 99 99]
[ 8 9 10 11]]
[[99 99 99 99]
[99 99 99 99]
[20 21 22 23]]]
嗯,请大家慢慢消化。
送个彩蛋!
对于高维array, [n,:]和[n,::]的结果是一样的,因为“:”是all的意思,即取出剩下的所有,而“::”是从头到尾逐个取出来,上面在list的":"操作中已经讲过了。
维度变换以及高维张量的相乘在深度学习中会经常被用到,更是烧脑,大家要多练习多实践,共勉!
扫码下图关注我们不会让你失望!

