前言
继续在kaggle找不错的数据集
传送门:
https://www.kaggle.com/sogun3/uspollution
这次是美国空气污染的数据

数据集介绍:
这个数据集涉及到美国的污染问题。美国环境保护署详细记录了美国的污染情况,但下载所有的数据并按照数据科学家感兴趣的格式进行安排是一件痛苦的事情。 因此,我从2000年至2016年每天收集四种主要污染物(二氧化氮,二氧化硫,一氧化碳和臭氧),并将它们整齐地放置在一个csv文件中。
数据探索
将数据下载到本地,使用pandas打开:
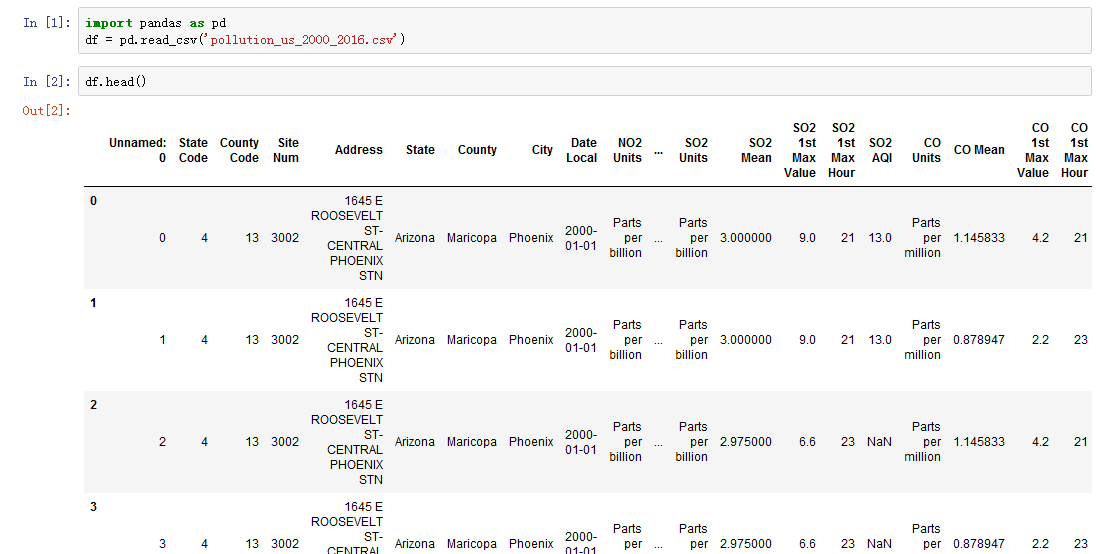
我们先去除掉无意义的字段(列):
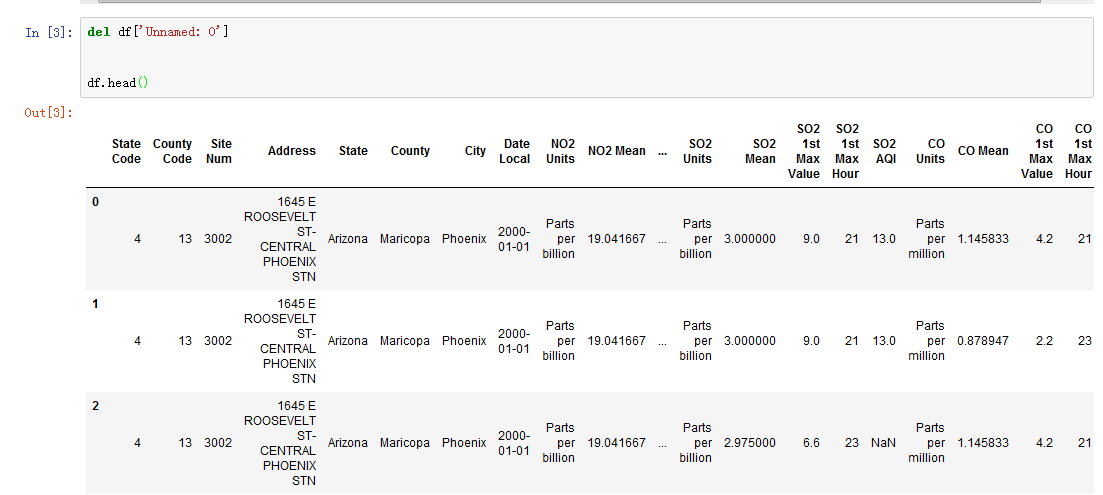
接着看一下各字段信息:
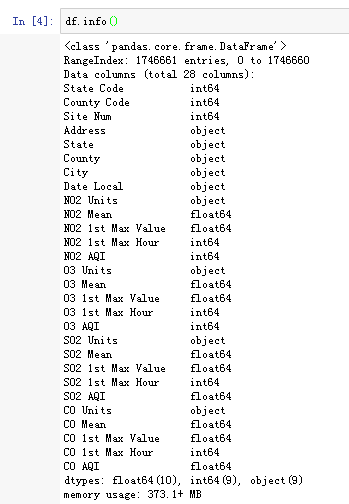
发现数值型的值很多,很棒~
内容
总共有28个字段:
州代码:由美国环保局分配给每个州的代码
县代码:由美国环保署分配的特定州的代码
地点编号:由美国环保局分配的特定县的地点编号
地址:监测站点的地址
状态:监测点的状态
县:县监测站点
城市:监测点的城市
日期本地:监视日期
四种污染物(NO2,O3,SO2和O3)各有5个专栏。 例如,对于NO2:
NO2单位:测量NO2的单位
NO2平均值:给定日内NO2浓度的算术平均值
NO2 AQI:一天内NO2计算的空气质量指数
NO2第一最大值:给定日期的NO2浓度的最大值
NO2第1小时:指在某一天记录的最大NO2浓度的小时数
观察总数超过140万。
对于这么大一个数据集分析是比较困难的,而且是随时间变化的
我们仔细观察一下数据:
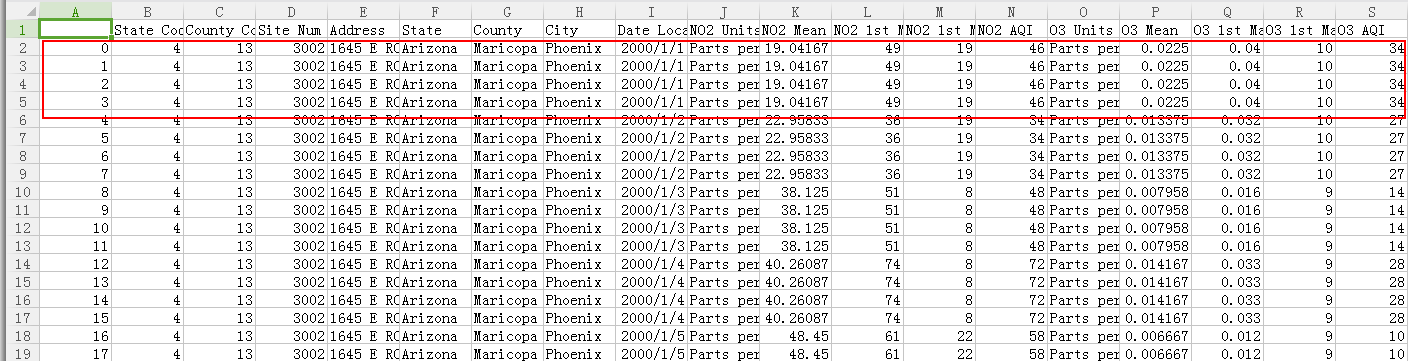
发现每四个是重复的数据,看后面的字段部分:
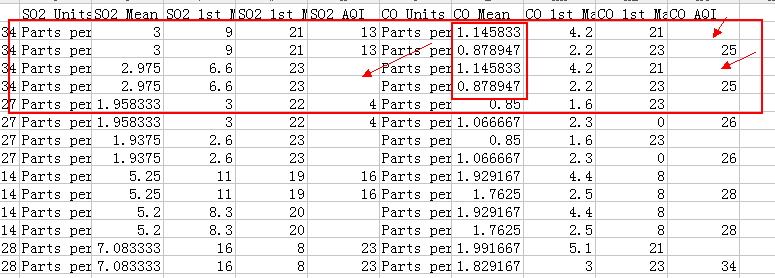
发现有缺失值,并且有少量字段数据是不一样的,为什么会产生这种情况呢?
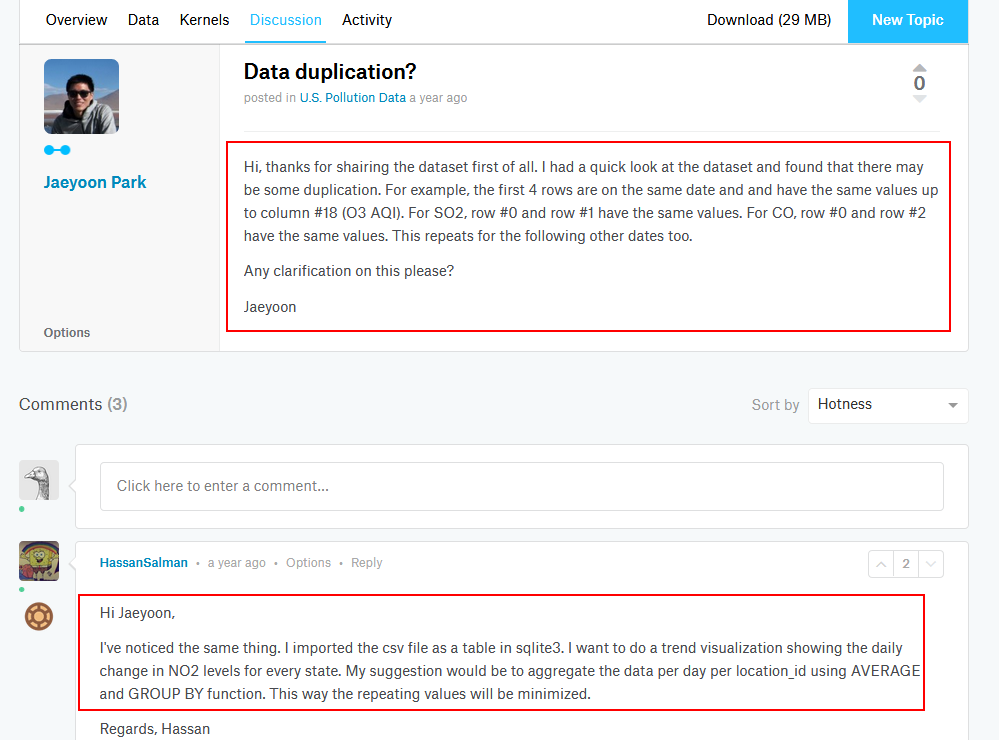
在kaggle的讨论区找到了答案,建议使用平均值

经过观察,发现每四个相似数据只有一个是没有缺失值的
为了方便分析,去除有缺失值的记录(行)
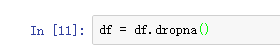
再看一下信息:
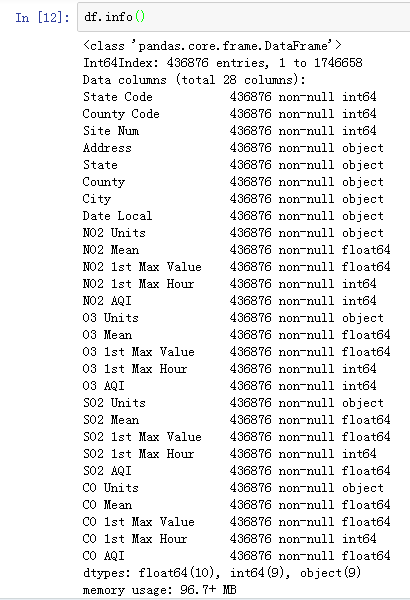
此时已经没有缺失值了
我们把剩下的新数据写入新的csv文件,然后打开文件:
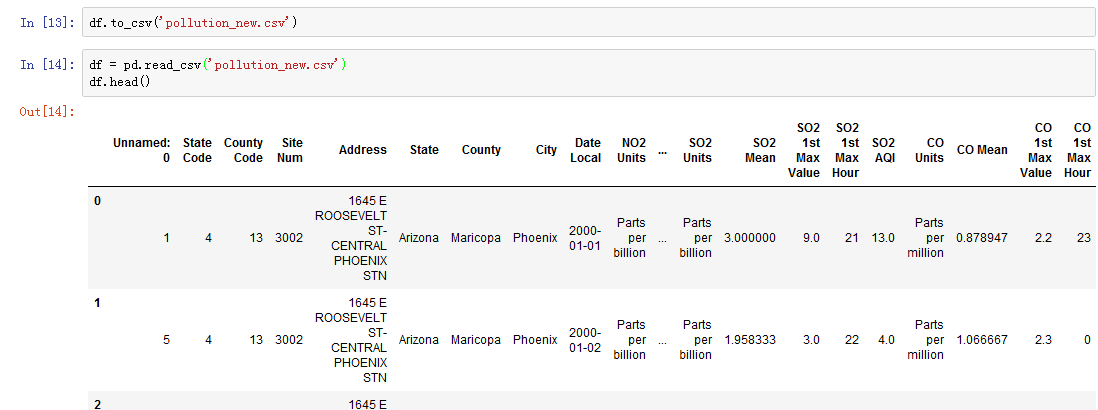

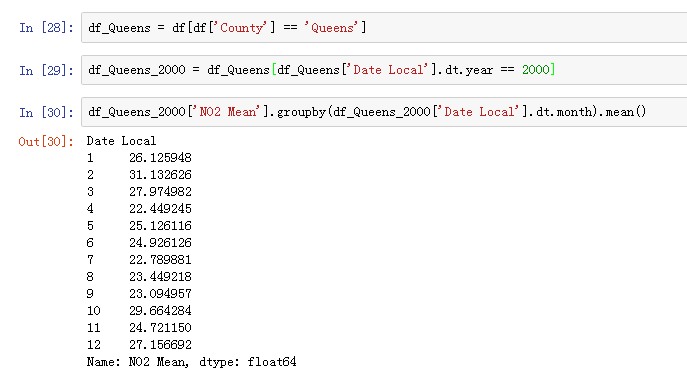
稍作处理后,我们筛选出皇后区的数据:

将日期转换成pandas中的时间格式:

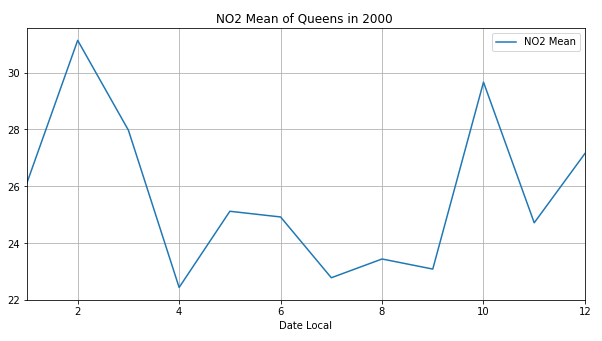
ok,我们看一下皇后区2000年每个月二氧化氮的平均值:
数据可视化
绘制出二氧化氮的平均值变化曲线
再将其他三种污染物的变化图画出:
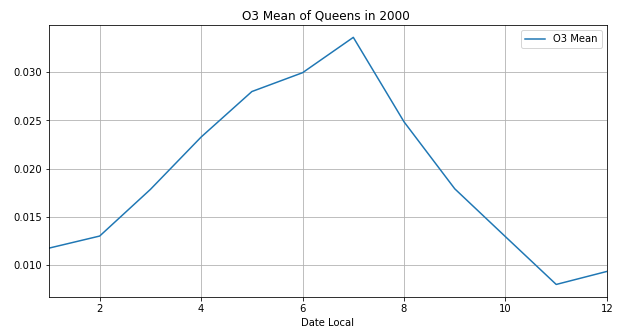
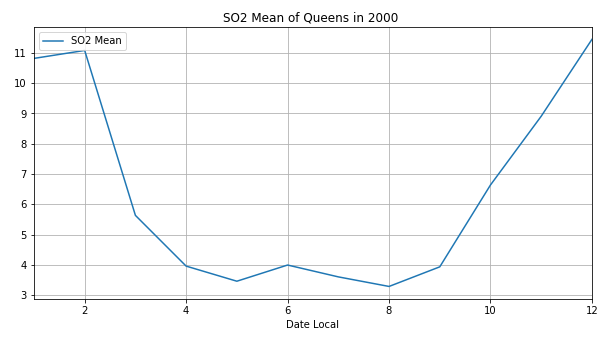
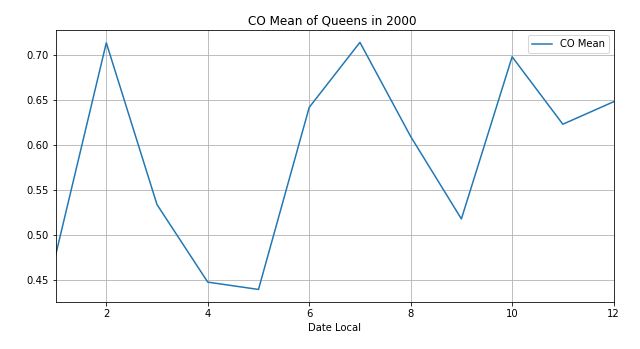
发现二氧化氮和一氧化碳的波动比较大,臭氧和二氧化硫有类似负相关的关系
接下来我们看一下2000年-2016年皇后区的四项污染物的年平均值
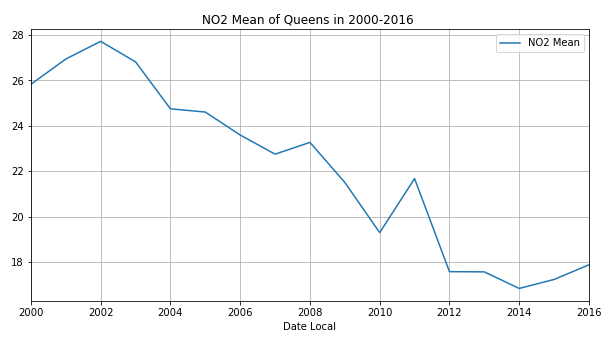

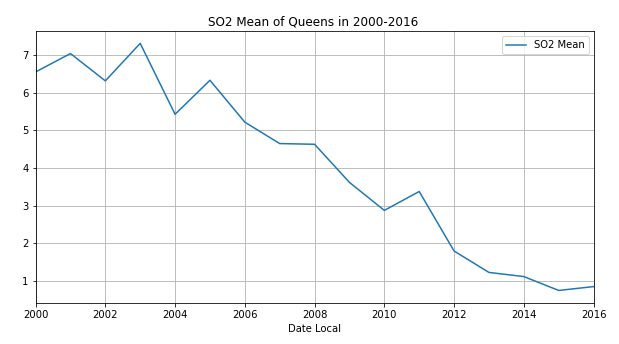
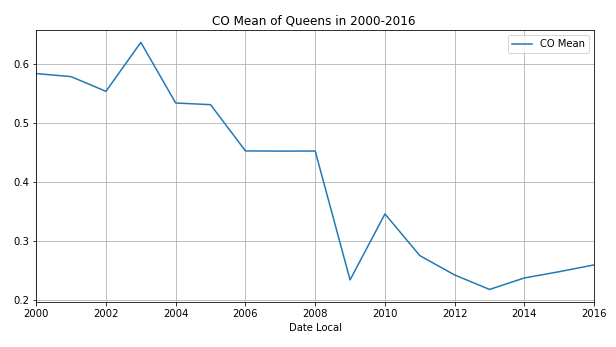
通过观察,发现除了臭氧,其他三种空气污染物随着时间变化,总体呈现下降趋势!
AQI空气质量指数
通过查阅百度百科:

发现AQI分为六级,值越大,空气质量越差:
计算时按照如下方式:
各种污染物的AQI值分别算出来后,取数值最大的那个即为最终报告的AQI值。比如SO2浓度为20.5μg/m3,算出来对应的 AQI为29;PM10浓度为150.8μg/m3,对应的AQI为98;PM2.5浓度为130.7μg/m3,对应的AQI为190。最终报告的 AQI值就是190,而贡献了那个最大值的PM2.5则称为首要污染物。
参考:https://www.guokr.com/post/431588/focus/0143499827/
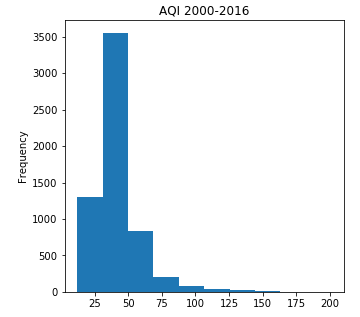
所以我们取出2000-2016每天皇后区的AQI值:

看一下数据的分布情况:

按照每年365天算,2000-2016年有17年,共有6205天,现在的数据有6047条
因为2016年数据并不是到年底的
通过查看数据,发现只是到四月底的:

我们看一下美国标准的划分:

我们使用map函数对pandas的AQI列分等级(依照实际得分)


通过查看前五项数据:
发现搞定啦~
我们对空气质量统计一下:

发现空气质量GOOD占比很大
为了看出比重,我们做个饼图:


发现占比超过3/4
通过此次分析,大体可以看出:
1.纽约皇后区总体空气质量越来越好(时间序列)
2.从总体上看,空气质量良好占比非常大。




