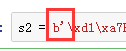你的浏览器禁用了JavaScript, 请开启后刷新浏览器获得更好的体验!
前文传送门:
Python从零开始系列连载(1)——安装环境
Python从零开始系列连载(2)——jupyter的常用操作(上)
Python从零开始系列连载(3)——jupyter的常用操作(中)
Python从零开始系列连载(4)——jupyter的常用操作(下)
Python从零开始系列连载(5)——Python的基本数据类型(上)
Python从零开始系列连载(6)——Python的基本数据类型(中)
Python从零开始系列连载(7)——Python的基本数据类型(中二)
Python从零开始系列连载(8)——Python的基本数据类型(下)
Python从零开始系列连载(9)——Python的基本运算和表达式(上)
Python从零开始系列连载(10)——Python的基本运算和表达式(中)
Python从零开始系列连载(11)——Python的基本运算和表达式(中二)
Python从零开始系列连载(12)——Python的基本运算和表达式(下)
Python从零开始系列连载(13)——Python程序的基本控制流程(上)
Python从零开始系列连载(14)——Python程序的基本控制流程(中)
Python从零开始系列连载(15)——Python程序的基本控制流程(中二)
Python从零开始系列连载(16)——Python程序的基本控制流程(下)
Python从零开始系列连载(17)——Python特色数据类型(列表)(上)
Python从零开始系列连载(18)——Python特色数据类型(列表)(中)
Python从零开始系列连载(19)——Python特色数据类型(列表)(下)
Python从零开始系列连载(20)——Python特色数据类型(元组)(上)
Python从零开始系列连载(21)——Python特色数据类型(元组)(下)
Python从零开始系列连载(22)——Python特色数据类型(字典)(上)
Python从零开始系列连载(23)——Python特色数据类型(字典)(下)
Python从零开始系列连载(24)——Python特色数据类型(集合)(上)
Python从零开始系列连载(25)——Python特色数据类型(集合)(下)
Python从零开始系列连载(26)——Python特色数据类型(函数)(上)
Python从零开始系列连载(27)——Python特色数据类型(函数)(中)
Python从零开始系列连载(28)——Python特色数据类型(函数)(下)
Python从零开始系列连载(29)——Python文件操作(上)
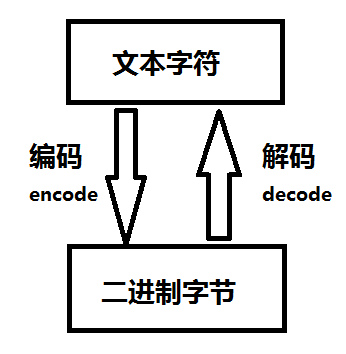
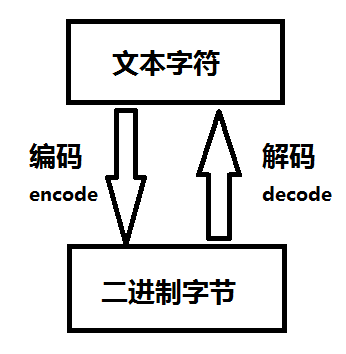
根据编码的不同,可以将文件分为文本字符和二进制字节
文本字符,如汉字、英文字母、数字、标点等,字符是为了显示
二进制字节是计算机存储的形式,在计算机中,任何数据都是01串构成的二进制字节
当我们打开文本,看到的是字符,最终保存时候存储的是二进制字节
文本字符的编码可以在win自带的记事本保存时选择各种编码
这里不详细讲解这些编码方式,如果有兴趣,可以自行摆渡!
因为我们使用的是Python3.X版本,在这个版本中,文件默认的编码方式就是utf-8
文本字符的常用的编码有ASCII和Unicode
值得注意的是,在Python3.X中,字符串等所有的文本字符使用的是unicode编码,可以使用encode()进行编码为utf-8
使用decode()可以将utf-8文件解码为文本字符
相互转换如图所示:
我们在Python中看看具体例子:
这里将文本字符中的字符串编码为默认的utf-8文件
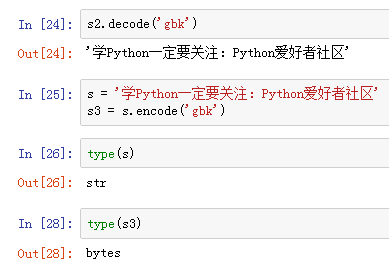
当然,除了utf-8编码,还有很多其他编码,比如gbk编码
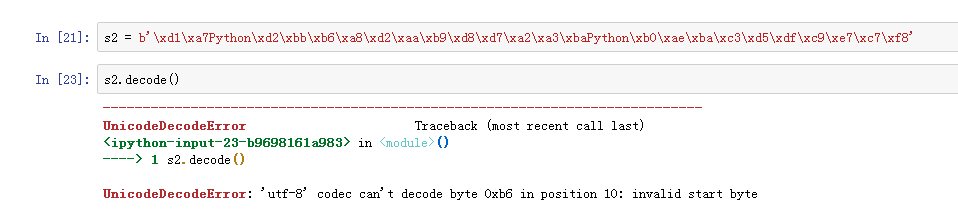
我们将utf-8解码回来
但是,如果我们将编码出的utf-8使用gbk解码,则会报错
从错误原因看出,某位置的内容不能被解码出来
想想原因,可以这样理解
一句中文,可以翻译为英文,也可以翻译为韩文
而只懂中文和英文的翻译A可以将中文翻译(编码)为英文,也可以将英文翻译(解码)为中文
如果想要让翻译A去将韩文翻译(解码)为中文,他不懂韩文,做不到啊!
而不同的编码解码就像这里的各种国家语言相互翻译
我们继续看看:
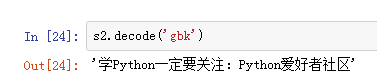
我们将gbk编码后的内容解码
报错了!因为我们解码没加参数,默认的是用utf-8解码
所以,我们得用gbk解码:
用gbk编码的内容当然不能用utf-8解码咯~
所以总结一下,utf-8编码出的内容只能用utf-8解码,gbk编码的内容只能用gbk解码!
注意到编码后的内容像个字符串,在字符串前面有个b,这个b表示的是二进制
也印证了字符编码后转为二进制字节
此时再来看一下这个图,是不是更清晰了
我们可以通过之前学的type()函数查看内容的状态
编码前的字符串显示为str字符串类型
编码后的字符串显示为bytes字节类型
如果你熟悉网络爬虫,遇到的最麻烦的问题之一就是编码问题,你对这种编码解码问题一定很熟悉吧,哈哈
下课
人生苦短,我选Python
未完待续,连载中......
今日作业:
将自己的名字用utf-8和gbk分别编码,看看结果啥样~
现在还坚持再看连载学习的你们真的很棒棒!
入门部分已经学完大部分啦!加油
下一篇:Python从零开始系列连载(31)——Python文件操作(中二)
海苔
要回复文章请先登录或注册