

















本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。
32 个评论
以后可以试试加上停用词的处理

写得好详细!已经把京东评论爬下来了!!谢谢~~
大神,为什么我的每个页都出现问题!
楼主,有源程序吗??能发下吗
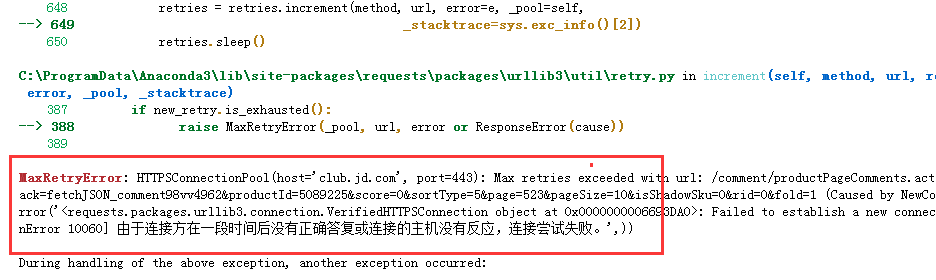
老师好 请问我在运行这个代码时 这个错误是什么原因
OSError Traceback (most recent call last)
<ipython-input-337-ddc2fe21a74f> in <module>()
----> 1 word_cloud = cloud.generate(cut_text)
E:\anaconda3\lib\site-packages\wordcloud\wordcloud.py in generate(self, text)
568 self
569 """
--> 570 return self.generate_from_text(text)
571
572 def _check_generated(self):
OSError Traceback (most recent call last)
<ipython-input-337-ddc2fe21a74f> in <module>()
----> 1 word_cloud = cloud.generate(cut_text)
E:\anaconda3\lib\site-packages\wordcloud\wordcloud.py in generate(self, text)
568 self
569 """
--> 570 return self.generate_from_text(text)
571
572 def _check_generated(self):
老师,可以再介绍一下怎么安装 wordcloud 模块吗?下载安装老是报错。。谢谢
安装 wordcloud提示如下错误:请老师帮忙给看看 怎么解决。
error: command 'cl.exe' failed: No such file or directory
error: command 'cl.exe' failed: No such file or directory
如何去除html标签的内容?还有就是图片和字体放到哪一个默认运行的目录呢?谢谢
for i in res: #这段for代码能实现将html的标签删除掉吗?谢谢
h = re.compile(r'<[^>]+>',re.S)
i = h.sub('',i)
f.write(i)
for i in res:
i = i.replace('\\n','')
#print(i)
f.write(i)
f.write('\n')
对于在list格式的文件中进行替换,上面这些写有什么问题?
h = re.compile(r'<[^>]+>',re.S)
i = h.sub('',i)
f.write(i)
for i in res:
i = i.replace('\\n','')
#print(i)
f.write(i)
f.write('\n')
对于在list格式的文件中进行替换,上面这些写有什么问题?
大伟老师您好,
不知道为什么我从官网上下的词云import的时候还是会报错
我的代码是:
from wordcloud import WordCloud
报错是:
箭头指向from .query_integral_image import query_integral_image这行
ModuleNotFoundError: No module named 'wordcloud.query_integral_image'
然后我看了一眼源文件,发现后缀是个.c,会不会和这个有关呢。
然后我安装的时候是手动的,把解压的文件放在了site-packages文件夹里面。
后来尝试下自动安装(pip install wordcloud),结果还是报错invalid syntax。
请问应该如何解决呢?
不知道为什么我从官网上下的词云import的时候还是会报错
我的代码是:
from wordcloud import WordCloud
报错是:
箭头指向from .query_integral_image import query_integral_image这行
ModuleNotFoundError: No module named 'wordcloud.query_integral_image'
然后我看了一眼源文件,发现后缀是个.c,会不会和这个有关呢。
然后我安装的时候是手动的,把解压的文件放在了site-packages文件夹里面。
后来尝试下自动安装(pip install wordcloud),结果还是报错invalid syntax。
请问应该如何解决呢?
跟着老师做了这个例子,也成功的获取到所有信息,中间也没有异常出现,那么我有一个问题:是不是所有的爬虫都是从他的url地址开始的呢,就是说url是爬虫的基础。
我是一个python小白,刚开始学习,见笑了哈!
我是一个python小白,刚开始学习,见笑了哈!
我生成的词云都是客服的回复。。。
老师,您好,为什么我爬的评论无法写入文件呢?报错信息如下:
UnsupportedOperation Traceback (most recent call last)
<ipython-input-10-c5369ec6f3dc> in <module>()
7 for i in res:
8 i=i.replace('\\n','')
----> 9 f.write(i)
10 f.write('\n')
11 f.close()
UnsupportedOperation: not writable
UnsupportedOperation Traceback (most recent call last)
<ipython-input-10-c5369ec6f3dc> in <module>()
7 for i in res:
8 i=i.replace('\\n','')
----> 9 f.write(i)
10 f.write('\n')
11 f.close()
UnsupportedOperation: not writable
UnicodeEncodeError Traceback (most recent call last)
<ipython-input-14-05196aa944fa> in <module>()
7 for i in res:
8 i=i.replace('\\n','')
----> 9 f.write(i)
10 f.write('\n')
11 f.close()
C:\ProgramData\Anaconda3\lib\encodings\cp1252.py in encode(self, input, final)
17 class IncrementalEncoder(codecs.IncrementalEncoder):
18 def encode(self, input, final=False):
---> 19 return codecs.charmap_encode(input,self.errors,encoding_table)[0]
20
21 class IncrementalDecoder(codecs.IncrementalDecoder):
UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-2: character maps to <undefined>
<ipython-input-14-05196aa944fa> in <module>()
7 for i in res:
8 i=i.replace('\\n','')
----> 9 f.write(i)
10 f.write('\n')
11 f.close()
C:\ProgramData\Anaconda3\lib\encodings\cp1252.py in encode(self, input, final)
17 class IncrementalEncoder(codecs.IncrementalEncoder):
18 def encode(self, input, final=False):
---> 19 return codecs.charmap_encode(input,self.errors,encoding_table)[0]
20
21 class IncrementalDecoder(codecs.IncrementalDecoder):
UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-2: character maps to <undefined>
f=open('H:/comment_iphone8.txt','a',encoding='utf-8')
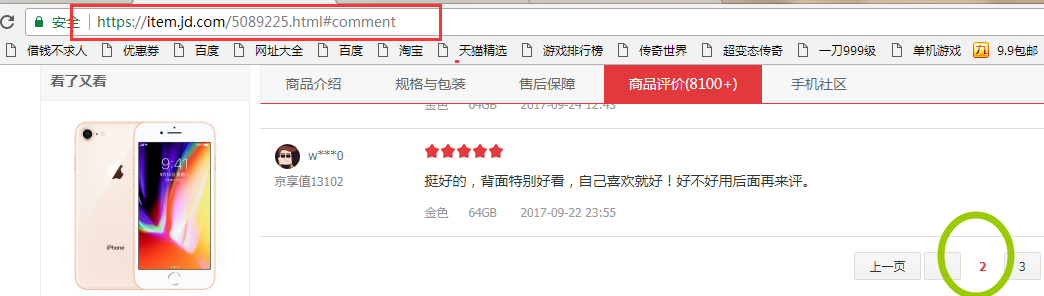
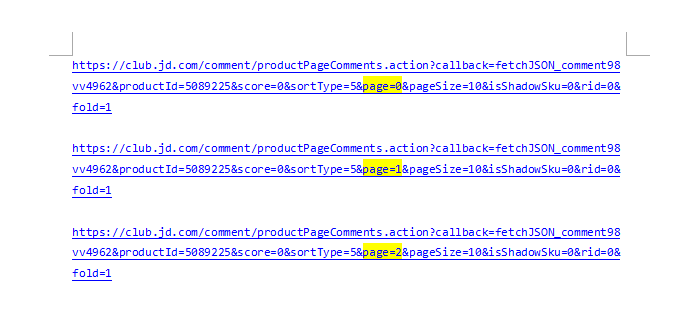
现在只能爬100页了吗?网址页数99打开有内容,到100就没东西了
我在 word_cloud = cloud.generate(cut_text) 出错 OSError: cannot open resource
不知道怎么解决 希望老师帮忙
不知道怎么解决 希望老师帮忙
def getComment(url):
Comment_1Page = []
res = requests.get(url)
jd = json.loads(res.text.lstrip('fetchJSON_comment98vv49037(').rstrip(');'))
for comment in jd['comments']:
Comment_1Page.append(comment['content'])
return Comment_1Page
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv49037&productId=5089269&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&rid=0&fold=1'
Comment_morePages = []
for i in range(1,10):
urls = url.format(i)
Comment_morePages.extend(getComment(urls))
print(Comment_morePages)
改良的代码 用json包直接提取 大家可以试一下
Comment_1Page = []
res = requests.get(url)
jd = json.loads(res.text.lstrip('fetchJSON_comment98vv49037(').rstrip(');'))
for comment in jd['comments']:
Comment_1Page.append(comment['content'])
return Comment_1Page
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv49037&productId=5089269&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&rid=0&fold=1'
Comment_morePages = []
for i in range(1,10):
urls = url.format(i)
Comment_morePages.extend(getComment(urls))
print(Comment_morePages)
改良的代码 用json包直接提取 大家可以试一下
两个疑问:
1、为什么生成词韵前不把所有重复的评论删掉?请问怎么操作
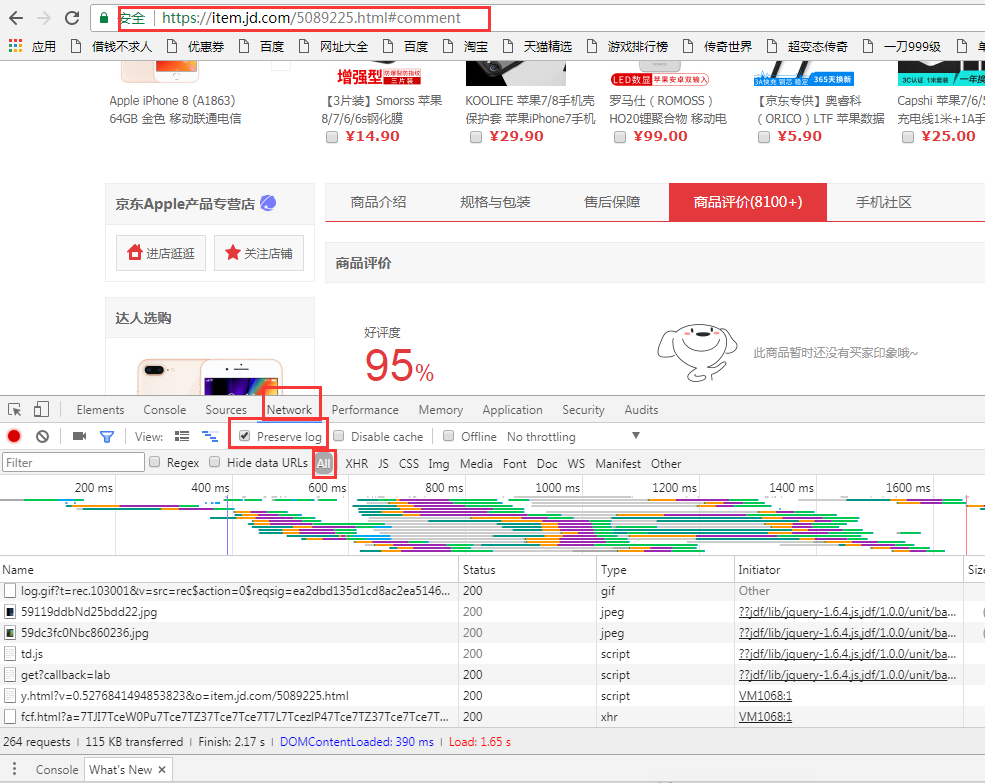
2、异步评论我记得是可以直接在XHR中找,先清除浏览痕迹,再刷新页面,一般出来的第一个新的就是。
1、为什么生成词韵前不把所有重复的评论删掉?请问怎么操作
2、异步评论我记得是可以直接在XHR中找,先清除浏览痕迹,再刷新页面,一般出来的第一个新的就是。