如前两篇文章介绍的,在Inceptor中,Jobs被划分为Stage执行,每个Stage由多个Task在不同Executor上实现,以处理存储位于不同节点的数据。Jobs、Stage、Executor以及关于存储的标签页分析方法已经提供于之前两篇文章,本文将介绍如何观察指定Stage中的Task信息,该信息页面通过点击Cluster标签页中相关Stage的链接进入(如下所示),我们称之为Stage信息页面。

Stage信息页面包含了三种信息列表Stage Summary Metrics、Aggregated Metrics by Executor、Tasks,以及DAG Visualization和Event Time两个图形化反馈信息。下面是对它们的具体介绍。
Stage的信息列表
- Summary Metrics for N Completed Tasks
该列表反映了Stage中N个已完成的Tasks的统计分析信息,提供了任务各类开销的整体占用统计分布情况。页面显示如下图所示:
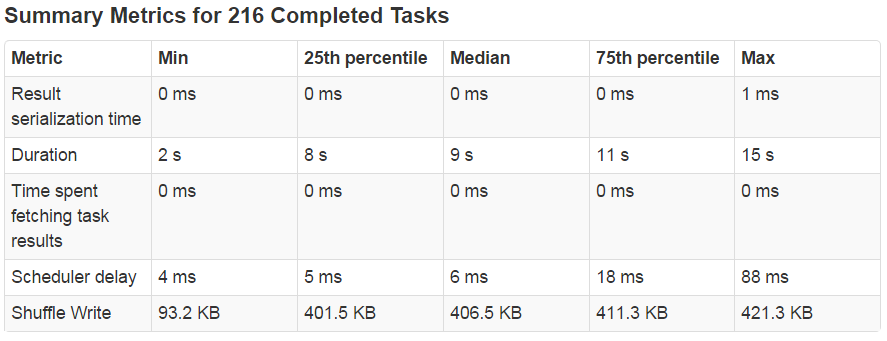
该列表将Task的开销细分为五个方面,通过Metric字段列举这五种开销的名称,由上至下分别为:结果序列化时间、总执行时间、结果获取时间、延时、Shuffle写的数据量。Min、25th percentile、Median、75th percentile和Max分别表示当把所有Task的对应开销看做集合时,该集合元素按从小到大排列后的最小值、1/4处的值、中位数、3/4处的值、最大值,从而获得各Task的各方面开销集中在哪一区间和跨度情况。
- Aggregated Metrics by Executor
该列表的示例如下图所示:

该表中的各字段含义和字面意思一致,除去同Shuffle Spill相关的两列,其余列的含义和已介绍的Executors列表中列值代表意义相同(参考技术|Inceptor任务的图形化分析(二))。Shuffle Spill(Memory)和Shuffle Spill(Disk)分别代表在实现Shuffle时中写入内存和硬盘的数据量,对调优帮助不大,读者可以忽略。
Tasks列表的示例如下图所示:
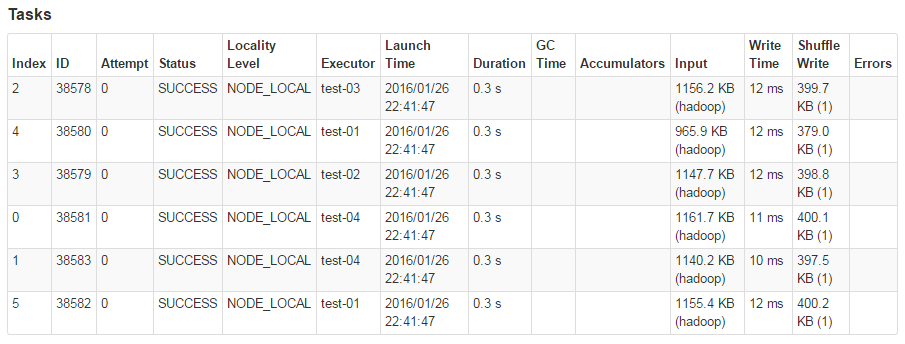
该列表共有14个描述信息,其含义可以从其字面理解:ID表示为该Task分配的唯一ID号;Status表示Task状态;Executor表示该Task的执行位置;Launch Time表示任务的触发时间;Duration为执行时长;Input为读入数据量;Write Time为Shuffle写时间;Shuffle Write为Shuffle写的数据量。这里对Attempt和Locality Level两个指标的含义做特别讲解。
Attempt代表Task重试(Retry)的次数,如果Attempt数值过大则说明Task的可用资源匮乏(很可能是内存)或者待处理的数据过多,难以应对业务需求。
Locality Level表示计算的执行位置和数据存放位置的关系,可能的取值有三个,名称和代表含义见下表:
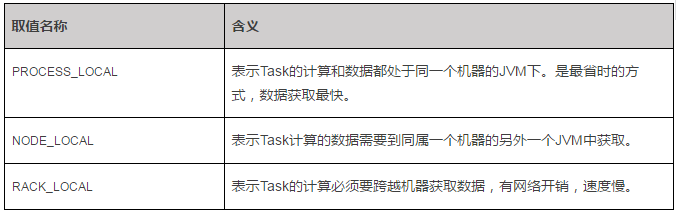
所以用户应该尽量保证数据被均衡的分布在各个节点,以尽可能的使计算和数据处于同一个节点、同一个JVM中,从而减少数据远距离传输。当各Task的Locality Level取值都为PROCESS_LOCAL时将处于最好状态。
另外观察Task的Duration情况也可以了解是否存在数据倾斜现象。如果个别Task的执行时长远远大于其余Tasks,即表明数据出现倾斜,应该及时进行数据均衡分配。特别的,如果所有耗时长的Task基本都聚集在一个Executor或一台机器上,说明该Executor或者这台机器出现了问题,需要针对性的排查。
Stage页面的按钮
Stage信息页面左上方有两个用于显示图形描述信息的按钮,分别是DAG Visualization和Event Timeline。
点击该按钮将获得关于当前Stage的有向无环图(DAG),该DAG和Jobs页的DAG显示方式相同,只是这里是对单个Stage过程的图形化描述,提供了在该Stage中各Operator的执行顺序和关系。

Event Timeline给出了各Executor的运行开销分布图,如下图所示。
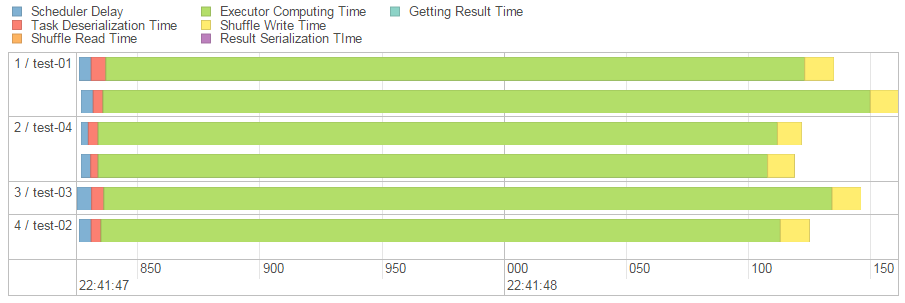
其中每一个横向柱状表示一个Task的执行时间,同一个Executor执行的Task在同一个单元显示。柱型中的不同颜色表示不同类型任务的时长,因此从该图中我们可以发现计算时长(绿色部分)通常占据最大比重。
该图和Summary Metrics类似,反映了Stage中任务执行情况的统计信息,但是是更加直观的表达。
总结
本文对Stage信息页面中的Summary Metric、Aggregate Metrics by Executor、Tasks三个信息列表各列的内容含义进行了解释,并介绍了DAG Visualization和Event Timeline两个图形信息。
其中,Summary Metrics列表通过将Task的整体开销细分为五种,以使用户了解Task的开销具体消耗在哪个环节,以及Task的开销分布从这五个指标上看是否均衡。例如,如果读者发现该列表的Duration行中Max的值远远高于其他几列的数值,那么就说明其中有一个Task的耗时过长,应定位至相关节点检查数据分布以及资源使用情况。
Aggregated Metrics by Executor提供了关于Executor的执行信息。观察该页面时应确保每个Executor都有任务跑,且每个Executor分配的Task数量差距不宜过大。
在浏览Tasks列表时,除了应注意Task的运行时长、GC压力以及Shuffle写的数据量之外,还应该特别关注Attempt和Locality Level两个指标。
最后还可以利用DAG Visualization和Event Timeline这两个图表能来辅助我们对Stage的执行过程及其开销的分布进行更加直观的了解和把控。
Inceptor的图形化页面是重要的分析辅助工具,将这三篇文章介绍的标签页的信息进行结合分析,用户可以从多个维度,多个方向,不同粒度的了解集群任务的处理状态。我们在这三篇文章中对不同指标的异常状态情况进行说明,为的是帮助用户通过指标数值的表象分析出问题出现的本因,如果能利用这一点采取相应措施,将能较快的提升运行与查错效率。
TDH 5.0及之后版本页面
星环计划在TDH 5.0推出新版本页面,新页面的浏览效果更好,速度更快,更方便于观察分析。在这里我们对5.0的Inceptor分析页面做一个小型的预告~~
分析界面的更新和提升主要在以下三方面进行:
1. 合并Cluster和Local标签页
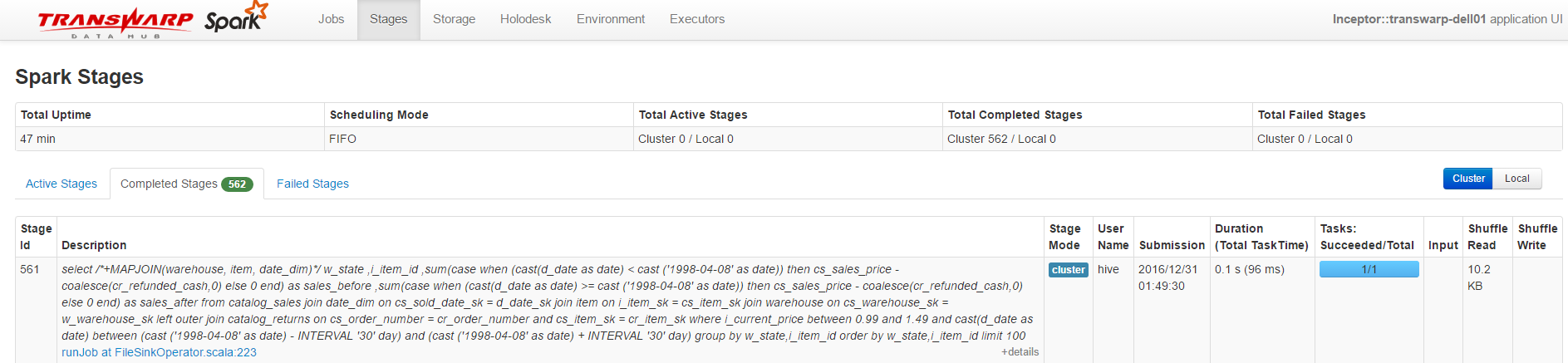
将Cluster和Local两个标签页的信息合并在一个新的名为Stages的标签页中,通过'Cluster'|'Local'按钮进行切换,而且每个Stage信息中增加了‘Stage Mode’一项,用于表示它是在集群还是本地模式下执行,如下图所示:
2. 不同类型Jobs/Stages的情况分子页显示
旧版本的Jobs和Cluster页面将不同类型(Active、Completed、Failed)的Jobs和Stage统一显示在一个页面,而新版本则将显示在不同子页里,并在子页的Tab名称右侧提供该类Jobs/Stages的数量,如下图所示:

从该图可以知道Completed Stages数量为562个,当前没有Active和Failed Stage。
这种显示方式下,页面的刷新速度更快。
3. 分页显示Jobs/Stages信息
原来的分析页面是把所有Jobs/Stages信息提供在同一个页面中,当Jobs/Stages的数量过多时使用者要通过不断滚动鼠标的方式阅读页面下面的信息,影响使用感。新版本将提供分页的功能,信息记录拆分到不同页,用户可以通过选择页号选择阅读某页信息。

除了对于Inceptor分析页面的改进,我们在5.0中开发了很多新产品和功能,敬请各位期待TDH 5.0带来的更好使用体验。
————————
往期回顾:
技术|Inceptor任务的图形化分析(二)
技术|六种常见SQL场景及其在TDH中的优化策略
技术|Inceptor任务的图形化分析(一)
关于:本文由公众号大数据开放实验室原创
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
————————
