前言
Hadoop的出现让人们尝到了大数据技术的甜头,它的批处理能力已经被工业界充分认可,但是它的延迟性也一直为大家所诟病。随着各行各业的发展,越来越多的业务要求大数据系统既可以处理历史数据,又可以进行实时计算。比如电商推荐系统,当你在京东浏览商品时,京东会根据你的浏览、加车、收藏、删除等行为,实时为你推荐商品。要实现这个功能,推荐引擎首先需要根据历史数据预先离线计算推荐模型,然后从消息队列中实时拉取用户行为数据,结合两者,实时生成推荐结果。
再举一个智慧交通系统的例子。在智慧交通系统中,需要对未年检、未报废等危险车辆进行实时预警,这就要求该系统预先根据历史数据删选出未年检或未报废的车辆信息库,然后将道路上实时获取到的车辆信息与车辆信息库进行对比,判断有没有违章车辆。
面对这样复杂的业务需求,开发者首先需要一个比较好的架构设计思路,在架构设计完成后再做相应的技术选型。目前业界有几个知名的架构设计来处理此类需求,如Lambda和Summingbird,但是它们在架构的设计上又有比较大的不同。就目前而言,Summingbird和Lambda架构都考虑到了实时计算和批处理相结合的问题,只不过Summingbird主张以统一的方式来执行代码,有关两者的区别,大家可以自行上网了解一下,这里我们只讨论Lambda架构。
背景介绍
Lambda架构是Nathan Marz提出的一个实时大数据处理框架。Nathan Marz是著名的实时大数据处理框架Storm的作者,Lambda架构就是其根据多年分布式大数据系统的经验总结提炼而成。
Nathan Marz 在Big Data:Principles and best practices of scalable real-time data systems一书中提到了很多实时大数据系统的关键特性,包括容错性,健壮性,低延迟,可扩展,通用性,方便查询等,Lambda就是其根据这些特性设计的一个实时大数据框架。需要注意的是,Lambda并不是一个具有实体的软件产品,而是一个指导大数据系统搭建的架构模型,因此,用户可以根据自己的需要,在Lambda的三层模型中,任意集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件,或者选用商用软件来构建系统。
原理讲解
大数据系统的特性
在讲大数据系统的特性之前,我们先来分析一下数据系统的本质。
Nathan Marz认为,数据系统的本质是“查询+数据”,用公式表达如下:

数据系统其实是一个提供了数据存储和数据查询功能的系统。在数据存储过程中,数据可能会发生丢失,在数据查询的过程中,查询也可能出现错误,因此,数据系统必须能够应对这些问题,这就是我们所说的数据系统的容错性和健壮性。除此之外,随着数据的规模越来越大,查询越来越复杂,我们希望数据系统是易于扩展的,并且是可维护的,最好查询仍然是低延迟的,至此,我们就可以来总结一下大数据系统的关键特性了,具体如下:
a. 容错性和健壮性:对于分布式系统来说,保证人为操作不出错,程序也不出错是不可能的,因此,大数据系统必须对这样的错误有足够的适应能力。
b. 低延迟:很多应用对于读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
c. 横向扩容:当数据量/负载增大时,系统可以采用scale out(通过增加机器的个数),而不是scale up(通过增强机器的性能)来维持性能。
d. 可扩展:当系统需要增加一些新功能或者新特性时,所花费的代价比较小。
e. 方便查询:数据系统的本质是“查询+数据”,因此,数据系统应具备方便、快速的数据查询功能。
f. 易于维护:系统要想做到易于维护,其关键是控制其复杂性,越是复杂的系统越容易出错、越难维护。
Lambda架构的三层模型
前面提到,Query = Function(All Data),那么大数据系统的关键问题就变成了:如何实时地在任意大数据集上进行查询?如果单纯地对全体数据集进行在线查询,那么计算代价会很大,延迟也会很高,比如Hadoop。
Lambda的做法是将大数据系统架构拆分成了三层:Batch Layer,Speed Layer和Serving Layer。Lambda的分层结构图如图1所示:
图1 Lambda分层结构图
a. Batch Layer
既然对全体数据集进行在线查询,计算代价会很高,那么如果对查询事先进行预计算,生成对应的Views,并且对Views建立索引,这样,查询的速度会提高很多,这就是Batch Layer所做的事。
Batch Layer层采用不可变模型对所有数据进行了存储,并且根据不同的业务需求,对数据进行了不同的预查询,生成对应的Batch Views,这些Batch Views提供给上层的Serving Layer进行进一步的查询。另外,每隔一段时间都会进行一次预查询,对Batch Views进行更新,Batch Views更新完成后,会立即更新到Serving Layer中去。
预查询的过程是一个批处理的过程,因此,这一层可以选择诸如Hadoop这样的组件。Batch Layer层的结构图如图2所示:

图2 Batch Layer
b. Speed Layer
如上一节中提到,预查询的过程是一个批处理的过程,该过程花费的时间会比较长,在该过程中,Serving Layer使用的仍然是旧版本的Batch Views,那么仅仅依靠Batch Layer这一层,新进入系统的数据将无法参与最后结果的计算,因此,Marz为Lambda设计了Speed Layer层来处理增量的实时数据。
Speed Layer和Batch Layer比较类似,对数据计算生成Realtime Views,其主要的区别是:
第一,Speed Layer处理的数据是最近的增量数据流,Batch Layer处理的是全体数据集。
第二,Speed Layer为了效率,接收到新数据时,就更新Realtime Views,并且采用的是Incremental Updates(增量计算模型),而Batch Layer则是根据全体离线数据集得到Batch Views,采用的是Recomputation Updates(重新计算模型)。
c. Serving Layer
Serving Layer用于响应用户的查询请求,它将Batch Views和Realtime Views的结果进行了合并,得到最后的结果,返回给用户,图3给出了Lambda的整体架构图:
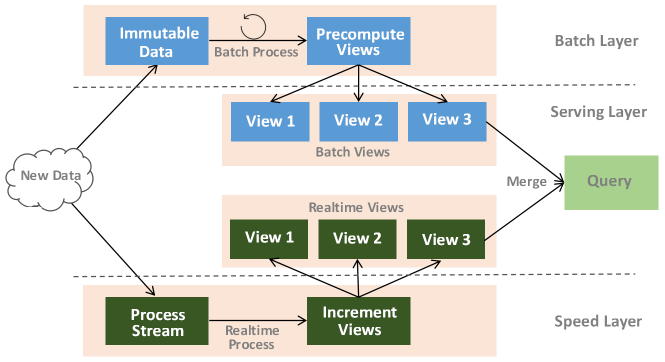
图3 Lambda架构图
概括起来,Lambda架构通过Batch Layer和Speed Layer的分层设计来实现在一个系统内同时支持实时和批处理业务,并且通过Serving Layer在逻辑上统一了两种数据源的接口,让应用能够以一个统一的数据视图来开发和部署,从而达到数据和应用的融合。
在每个Layer的实际设计中,开发人员可以根据自身的需求来选择合适的组件或者产品来构建相应的系统,目前有很多开源组件可以用于构建此类系统,如Storm/Spark Streaming/Flink可以用来构建Speed Layer,Spark/MapReduce可以用于构建Batch Layer,HBase/Redis/MongoDB可以用于存储。
由于一套系统需要同时处理实时业务和批处理业务,并且两批业务之间有比较明确的数据耦合,Lambda系统本身的技术复杂度非常高,选择方案的时候需要充分考虑系统构建成本以及稳定性。从笔者了解的情况看,选择开源技术来构建类似系统,目前国内只有很少的成功商业实践。对于技术实力不那么强的企业,选择一个可靠的商业软件往往是个更合适的选择。星环科技在这方面有非常不错的成功经验,接合着Transwarp Data Hub的技术优势,我们帮助客户在智慧交通系统领域完成了非常大规模的实际业务部署。下文我们将以某一个项目来做具体的案例分析,来描述如何使用TDH来完成一个用于大规模生产业务的Lambda系统。
案例分析
本案例为某省的智慧交通系统。
系统各层组件的选型
根据上面的介绍,Lambda架构包括三层,其中Batch Layer负责数据集的存储和批处理的执行,数据存储我们选择Hyperbase。Hyperbase支持快速高并发的查询,可以方便用户做一些精确类查询(如根据车牌号检索等)。由于此项目还有一些统计类的业务需求,我们选择将部分数据在HDFS上保留一份用作后期的分析之用,Inceptor的强大的数据分析能力可以帮助用户在任意维度上做复杂的数据分析工作。
Speed Layer主要负责对数据的实时处理,可以使用Transwarp Stream。此外,Kafka选择使用Transwarp Kafka 0.9版本,由于增加了Kafka队列内的kerberos安全认证功能,消息队列中的数据更安全。
HDFS和Hyperbase的数据通过SQL以及JDBC接口开放给用户,企业可以开发Serving Layer中自身需要的业务。由于这些应用程序是具体的企业内部业务,此处不做讨论。
系统各层机器规划
有了上面的组件选型,下面我们可以进行机器规划。主要考虑的是以下几个方面:
就某地市而言,每天约有1000w的过车记录产生,高峰时期每秒能约有1w条过车记录产生,每条过车记录对应的结构化数据约有30个字段,大小为200Byte;每天还有50w张左右大小约为500KB的图片数据,按照规划数据需要存储的周期为2年,因此对集群容量要求如下:
结构化数据存储三份、图片数据存储两份,2年的数据总量约为:
(1000w * 200B *3 + 50 w * 500KB * 2) * 365 * 2 = 344TB
每台机器有8个硬盘,每个硬盘容量为3TB,则需要数据节点数为:
344TB / (3TB*8) = 15台
另外,Hadoop分布式存储集群需要2台管理节点。
目前需要进行实时处理的业务包括:
a. 实时检测业务:逾期未年检、黑名单、逾期未报废、凌晨2点到5点上路行驶的客运车辆、车主驾驶证无效车辆等。
b. 实时分析业务:包括流量统计、旅行时间分析、套牌车检测、区间测速等。
其中实时检测业务以及套牌车检测等要求在秒级别反馈结果以对违法行为进行实时拦截;分析业务要求在分钟级别更新结果。
按照每秒1w条过车记录计算,总共有20+个流处理业务(比对和复杂分析)同时运行,预估需要实时处理集群机器6台。
另外,所有的过车记录都会预先被接入Kafka分布式消息处理集群,每条记录写入3份,保存7天,预估需要Kafka集群机器4台。
除了实时处理业务之外,还需要对历史数据进行统计分析,对于时间跨度在一个月内的统计分析需要在秒级返回结果;对于时间跨度在三个月以上的复杂统计分析需要在分钟级别返回结果。
依据上述的要求分析,给出机器数目和配置参考图如下:
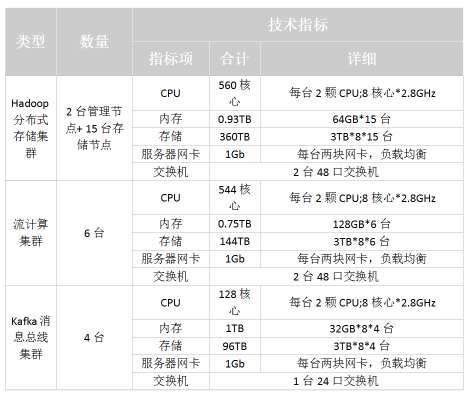
图4 某智能交通系统的配置情况
该智慧交通系统的架构图如图5所示:
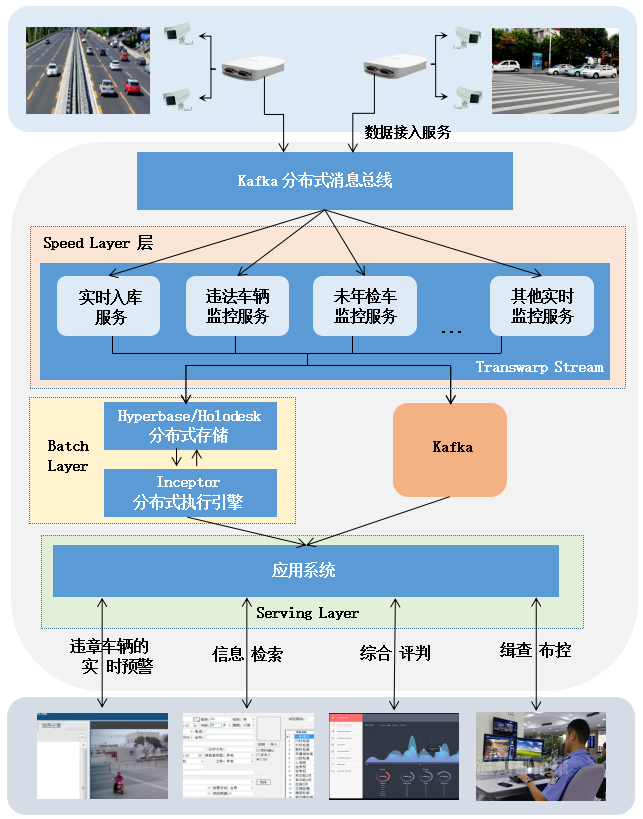
图5 智能交通的整体架构图
前端卡口会实时采集过往车辆信息,采集到的车辆信息首先被接入Kafka分布式消息总线。Kafka分布式消息总线,会对这些数据进行归类分拣,分发给不同的服务集群,比如实时入库服务集群、未年检车监控服务集群等。
假设有部分数据被送入到了未年检车监控服务集群中,该集群需要将待检查车辆与车辆数据库进行数据比对。为了减少数据比对时间,该系统预先根据历史数据生成了未年检车辆数据库,由Batch Layer层的批处理引擎完成。待检查车辆只需与未年检车辆数据库进行在线比对即可,如果发现违章车辆,则进行标记显示,并进行预警。
a. 实时监控预警业务
实时监控预警业务主要由Speed Layer层的Transwarp Stream负责,按照技术可以分为以下三类:
1) ETL功能
将实时采集的过车数据,按照一定的清洗转化规则进行处理,转化成规范的记录后写入后端存储Hyperbase和 Holodesk。其中Hyperbase为持久化的列式存储,保存所有的历史过车数据;Holodesk为临时存储,提供高速的分析能力,可以保存一周以内的短期数据。
2) 实时检测业务
最简单的检测规则可以直接根据过车记录判断,例如凌晨2点到5点行驶的车辆;其次是和一些基础表进行比对的业务,例如黑名单车辆/未年检车辆检测,需要事先进行预查询,生成并保存相应的黑名单车辆表/未年检车辆表。
3) 实时分析业务
实时统计业务如流量统计,通常基于窗口技术实现。例如需要统计分钟流量、小时流量,可以设定一个长度为1分钟的滚动窗口,统计每分钟的流量,并基于分钟流量对小时流量进行更新。
b. 数据统计分析业务
1) 基于全量历史数据的统计分析
通过Inceptor组件能够对存储在Hyperbase中的数据使用SQL语句进行统计分析,比如统计一天的车流量,一个月的碰撞次数等。Hyperbase的Rowkey具有去重的功能,可以帮助用户得到精准的统计结果。
2) 基于临时数据的交互式分析
除了一些固定的统计报表之外,还需要处理一些突发的临时性统计业务。例如伴随车分析,就是统计出一段时间内和某个车一同行驶的车辆,这在犯罪分析中有很大的作用。TDH中的Holodesk组件能够很好处理这部分业务需求,创建Holodesk上的一张有窗口限制的表(例如窗口长度为1周,超过1周的数据将被删除),通过Transwarp Stream将数据实时写入Holodesk,前端通过Inceptor的SQL实现交互式分析。
结语
Lambda架构是大数据中一个非常重要的设计,但是由于原理的抽象和系统的复杂性,大数据从业人员要设计出一个有生产质量的Lambda系统是非常有挑战性的。本文通过原理的梳理和具体商业的剖析,希望给读者一个总体的思路,如何从无到有设计出一个有效的系统,同时满足实时和离线业务的需求,帮助企业从数据中创造更大的价值。
(正文内容到此结束)
往期回顾:
一站式rJava自主开发的应用实现
技术 | Docker+Jenkins打造自动化测试以及部署
关于:此文由公众号大数据开放实验室原创
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。


