最近在测试hive on Spark的功能, 由于数据库Oracle习惯使用PLsql了,其他我都使用DbVisualizer,就尝试配置了一下。
0.测试环境
测试了2个hadoop集群,机器都是4台普通的服务器2U服务器
测试环境1:hive on hadoop
hive-1.0
hadoop-common-2.2
测试环境2:hive on spark
cdh5.7
hive-1.1.0
hadoop-2.6.0
spark-1.6.0
1.安装DbVisualizer9.5
下载地址http://www.dbvis.com/
修改dbvisgui.bat
增加PATH=JDK_PATH;%PATH%
2.配置DbVisualizer里的hive jdbc
DbVisualizer\jdbc\hive下复制这2个文件
hadoop-common-2.6.4.jar
hive-jdbc-1.1.1-standalone.jar
可以从hadoop的安装文件(http://hadoop.apache.org/releases.html)和hive的安装文件获取(http://www.apache.org/dyn/closer.cgi/hive/)
然后在tools/Driver manager按如下配置即可
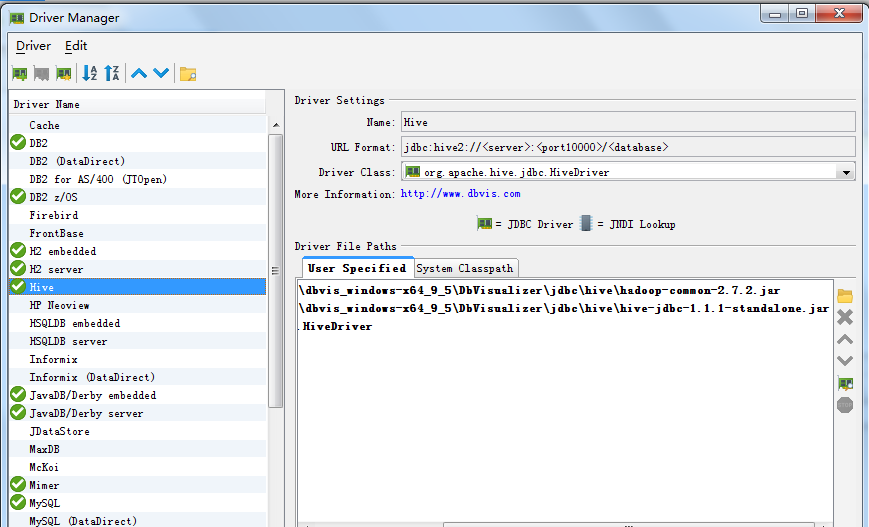
注意hive server如果是1.x的版本,hive-jdbc就不能使用2.x版本,会报如下错误:
Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{use:database=default})
hadoop版本高一点没关系,使用hadoop-common-2.7.2.jar也可以。
如果要使用老版本
需要在DbVisualizer\jdbc\hive下复制以下文件
hadoop-2.2.0/share/hadoop/common/hadoop-common-2.2.0.jar
hadoop-2.2.0/share/hadoop/common/lib/slf4j-api-1.7.5.jar
hadoop-2.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar
hive-1.0.0/lib/*
3.性能比较
数据表test 3000万的数据量,字段就是20个左右。
语句select sum(quantity),count(*) from test
hive on spark 大概第一次50三s+ ,以后20 s+
hive on hadoop 大概都是70 s+
具体的性能还要再加点数据看看。

