今天主要分享一下使用Scrapy框架抓取当当网的图书数据。
前言:
scrapy框架自带twisted线程池,默认10个线程,在爬虫这种IO密集型任务中可充分利用请求返回的等待时间。本次爬虫单机运行,2小时抓取完82万条图书信息。
Github地址:点这里
当当图书数据 密码:dt1q
文章目录结构:
在Windows命令行下进入当前文件目录输入:tree /f > tree.txt 命令,出现当前文件的目录
C:.
│ run.py
│ scrapy.cfg
│
└─dangdang
│ items.py
│ pipelines.py
│ settings.py
│ __init__.py
│
└─spiders
dangdang.py
__init__.py
想必大家对Scrapy框架中各模块的用途已经比较了解了,我这里先做下简要介绍,下面进行详细展开。run.py:设置在pycharm控制台运行程序,items.py:定义抓取的数据字段包括哪些, pipelines.py :将抓取到的数据持久化到本地, settings.py:设置运行参数,如数据库配置、时间间隔、消息队列 , dangdang.py:抓取数据的核心程序,包括解析页面,匹配字段,异常处理。下面我结合程序,进行详细说明。
运行管理:
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl dangdangspider".split())
一般我们通过cmd进入当前文件路径的方式运行程序,为更方便我们调试程序,这里我们可以通过引入cmdline的方式,直接运行此文件可在pycharm控制台下查看程序运行效果。
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for dangdang project
BOT_NAME = 'dangdang'
SPIDER_MODULES = ['dangdang.spiders']
NEWSPIDER_MODULE = 'dangdang.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
SCHEDULER = "scrapy_redis.scheduler.Scheduler" #调度
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #去重
SCHEDULER_PERSIST = True #不清理Redis队列
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" #队列
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 27017
MONGODB_DBNAME = "dangdang"
MONGODB_DOCNAME = "saveinto_2"
settings中需要设置一些程序中运行的关键配置信息:
DOWNLOAD_DELAY:设置爬取的延时等待时间,这里设置1s
SCHEDULER:scrapy中的调度器配置
DUPEFILTER_CLASS:对爬取的链接去重,当发现有重复链接时对第二个链接不再爬取
SCHEDULER_PERSIST:如果这一项设为True,那么在Redis中的URL队列不会被清理掉,但是在分布式爬虫共享URL时,要防止重复爬取。如果设为False,那么每一次读取URL后都会将其删掉,但弊端是爬虫暂停后重新启动,他会重新开始爬取。
SCHEDULER_QUEUE_CLASS:爬虫的请求调度算法,这里有三种可供选择
- scrapy_redis.queue.SpiderQueue:队列。先入先出队列,先放入Redis的请求优先爬取;
- scrapy_redis.queue.SpiderStack:栈。后放入Redis的请求会优先爬取;
- scrapy_redis.queue.SpiderPriorityQueue:优先级队列。根据优先级算法计算哪个先爬哪个后爬,比较麻烦
下面的一些是对mongodb的配置,默认主机127.0.0.1,端口27017,数据库名称设为dangdang,表名称设为saveinto_2。
Redis的信息不配置的话,默认在本地运行
下载和存储管理:
items.py
# -*- coding: utf-8 -*-
import scrapy
class DangdangItem(scrapy.Item):
_id = scrapy.Field()
title = scrapy.Field()
comments = scrapy.Field()
time = scrapy.Field()
press = scrapy.Field() #出版社
price = scrapy.Field()
discount = scrapy.Field()
category1 = scrapy.Field() # 种类(小)
category2 = scrapy.Field() # 种类(大)
我们需要抓取的字段包括:书名、评论数量、出版时间、出版社、价格、折扣、图书归属的大种类、图书归属的小种类(大种类如:童书,小种类如:中国儿童文学 / 科普 / 百科 / 3~6岁)
pipelines.py
# -*- coding: utf-8 -*-
import pymongo
from scrapy.conf import settings
from .items import DangdangItem
class DangdangPipeline(object):
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
db_name = settings['MONGODB_DBNAME']
client = pymongo.MongoClient(host=host,port=port)
tdb = client[db_name]
self.post = tdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
'''先判断itme类型,在放入相应数据库'''
if isinstance(item,DangdangItem):
try:
book_info = dict(item) #
if self.post.insert(book_info):
except Exception:
pass
return item
这里我们在__init__函数中首先初始化连接到mongodb数据库,关于mongodb的配置信息见上面的setting.py介绍。接下来在process_item函数中通过 isinstance 判断传入的item类型,然后持久化到对应的数据库。
spider抓取程序:
终于写到抓取的关键环节了。在贴上代码之前,先对抓取的页面和链接做一个分析:
http://category.dangdang.com/pg4-cp01.25.17.00.00.00.html
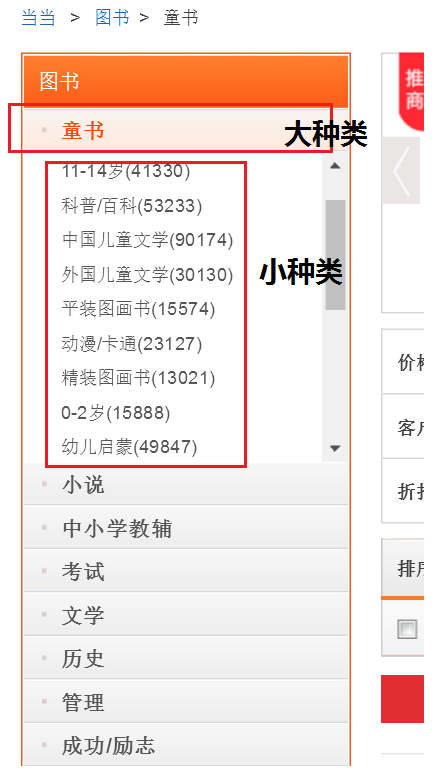
这个是当当网图书的链接,经过分析发现:大种类的id号对应 cp01.25 中的25,小种类对应id号中的第三个 17,pg4代表大种类 —>小种类下图书的第17页信息。
为了在抓取图书信息的同时找到这本图书属于哪一大种类下的小种类的归类信息,我们需要分三步走,第一步:大种类划分,在首页找到图书各大种类名称和对应的id号;第二步,根据大种类id号生成的链接,找到每个大种类下的二级子种类名称,及对应的id号;第三步,在大种类 —>小种类的归类下抓取每本图书信息。
分步骤介绍下:
1、我们继承RedisSpider作为父类,start_urls作为初始链接,用于请求首页图书数据
# -*- coding: utf-8 -*-
import scrapy
import requests
from scrapy import Selector
from lxml import etree
from ..items import DangdangItem
from scrapy_redis.spiders import RedisSpider
class DangdangSpider(RedisSpider):
name = 'dangdangspider'
redis_key = 'dangdangspider:urls'
allowed_domains = ["dangdang.com"]
start_urls = 'http://category.dangdang.com/cp01.00.00.00.00.00.html'
def start_requests(self):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
yield scrapy.Request(url=self.start_urls, headers=headers, method='GET', callback=self.parse)
2、在首页中抓取大种类的名称和id号,其中yield回调函数中传入的meta值为本次匹配出的大种类的名称和id号
def parse(self, response):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
lists = response.body.decode('gbk')
selector = etree.HTML(lists)
goodslist = selector.xpath('//*[@id="leftCate"]/ul/li')
for goods in goodslist:
try:
category_big = goods.xpath('a/text()').pop().replace(' ','') # 大种类
category_big_id = goods.xpath('a/@href').pop().split('.')[1] # id
category_big_url = "http://category.dangdang.com/pg1-cp01.{}.00.00.00.00.html".\
format(str(category_big_id))
# print("{}:{}".format(category_big_url,category_big))
yield scrapy.Request(url=category_big_url, headers=headers,callback=self.detail_parse,
meta={"ID1":category_big_id,"ID2":category_big})
except Exception:
pass
3、根据传入的大种类的id号抓取每个大种类下的小种类图书标签,yield回调函数中传入的meta值为大种类id号和小种类id号
def detail_parse(self, response):
'''
ID1:大种类ID ID2:大种类名称 ID3:小种类ID ID4:小种类名称
'''
url = 'http://category.dangdang.com/pg1-cp01.{}.00.00.00.00.html'.format(response.meta["ID1"])
category_small = requests.get(url)
contents = etree.HTML(category_small.content.decode('gbk'))
goodslist = contents.xpath('//*[@class="sort_box"]/ul/li[1]/div/span')
for goods in goodslist:
try:
category_small_name = goods.xpath('a/text()').pop().replace(" ","").split('(')[0]
category_small_id = goods.xpath('a/@href').pop().split('.')[2]
category_small_url = "http://category.dangdang.com/pg1-cp01.{}.{}.00.00.00.html".\
format(str(response.meta["ID1"]),str(category_small_id))
yield scrapy.Request(url=category_small_url, callback=self.third_parse, meta={"ID1":response.meta["ID1"],\
"ID2":response.meta["ID2"],"ID3":category_small_id,"ID4":category_small_name})
# print("============================ {}".format(response.meta["ID2"])) # 大种类名称
# print(goods.xpath('a/text()').pop().replace(" ","").split('(')[0]) # 小种类名称
# print(goods.xpath('a/@href').pop().split('.')[2]) # 小种类ID
except Exception:
pass
4、抓取各大种类——>小种类下的图书信息
def third_parse(self,response):
for i in range(1,101):
url = 'http://category.dangdang.com/pg{}-cp01.{}.{}.00.00.00.html'.format(str(i),response.meta["ID1"],\
response.meta["ID3"])
try:
contents = requests.get(url)
contents = etree.HTML(contents.content.decode('gbk'))
goodslist = contents.xpath('//*[@class="list_aa listimg"]/li')
for goods in goodslist:
item = DangdangItem()
try:
item['comments'] = goods.xpath('div/p[2]/a/text()').pop()
item['title'] = goods.xpath('div/p[1]/a/text()').pop()
item['time'] = goods.xpath('div/div/p[2]/text()').pop().replace("/", "")
item['price'] = goods.xpath('div/p[6]/span[1]/text()').pop()
item['discount'] = goods.xpath('div/p[6]/span[3]/text()').pop()
item['category1'] = response.meta["ID4"] # 种类(小)
item['category2'] = response.meta["ID2"] # 种类(大)
except Exception:
pass
yield item
except Exception:
pass
抓取的效果:
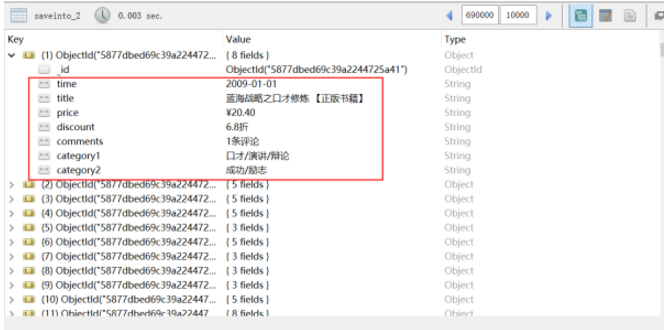
5、从mongodb导出数据:
>mongoexport -d dangdang -c saveinto_2 -f discount,title,comments,price,time,category1,category2 --type=csv -o dangdang.csv
结束,谢谢大家耐心地看到这里

