前言
朴素贝叶斯算法仍然是流行的十大挖掘算法之一,该算法是有监督的学习算法,解决的是分类问题,如客户是否流失、是否值得投资、信用等级评定等多分类问题。该算法的优点在于简单易懂、学习效率高、在某些领域的分类问题中能够与决策树、神经网络相媲美。但由于该算法以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,就会导致算法精度在某种程度上受影响。接下来我们就详细介绍该算法的知识点及实际应用。
朴素贝叶斯的思想
思想很简单,就是根据某些个先验概率计算Y变量属于某个类别的后验概率,请看下图细细道来:
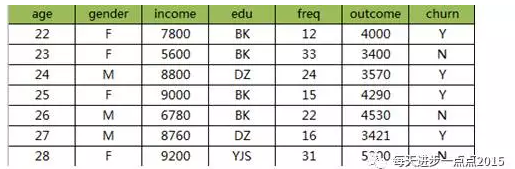
假如,上表中的信息反映的是某P2P企业判断其客户是否会流失(churn),而影响到该变量的因素包含年龄、性别、收入、教育水平、消费频次、支持。那根据这样一个信息,我该如何理解朴素贝叶斯的思想呢?再来看一下朴素贝叶斯公式:
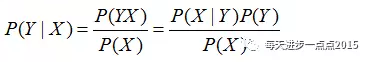
从公式中可知,如果要计算X条件下Y发生的概率,只需要计算出后面等式的三个部分,X事件的概率(P(X)),是X的先验概率、Y属于某类的概率(P(Y)),是Y的先验概率、以及已知Y的某个分类下,事件X的概率(P(X|Y)),是后验概率。从上表中,是可以计算这三种概率值的。即:
P(x)指在所有客户集中,某位22岁的本科女性客户,其月收入为7800元,在12次消费中合计支出4000元的概率;
P(Y)指流失与不流失在所有客户集中的比例;
P(X|Y)指在已知流失的情况下,一位22岁的本科女性客户,其月收入为7800元,在12次消费中合计支出4000元的概率。
如果要确定某个样本归属于哪一类,则需要计算出归属不同类的概率,再从中挑选出最大的概率。
我们把上面的贝叶斯公式写出这样,也许你能更好的理解:
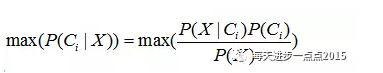
而这个公式告诉我们,需要计算最大的后验概率,只需要计算出分子的最大值即可,而不同水平的概率P(C)非常容易获得,故难点就在于P(X|C)的概率计算。而问题的解决,正是聪明之处,即贝叶斯假设变量X间是条件独立的,故而P(X|C)的概率就可以计算为:
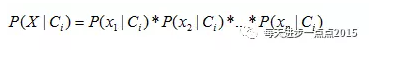
也许,这个公式你不明白,我们举个例子(上表的数据)说明就很容易懂了。
对于离散情况:
假设已知某个客户流失的情况下,其性别为女,教育水平为本科的概率:

上式结果中的分母4为数据集中流失有4条观测,分子2分别是流失的前提下,女性2名,本科2名。
假设已知某个客户未流失的情况下,其性别为女,教育水平为本科的概率

上式结果中的分母3为数据集中未流失的观测数,分子2分别是未流失的前提下,女性2名,本科2名。
从而P(C|X)公式中的分子结果为:
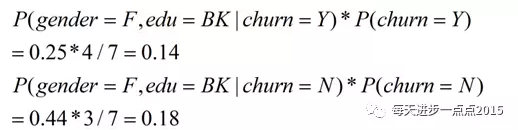
对于连续变量的情况就稍微复杂一点,并非计算频率这么简单,而是假设该连续变量服从正态分布(即使很多数据并不满足这个条件),先来看一下正态分布的密度函数:
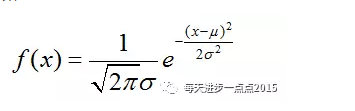
要计算连续变量中某个数值的概率,只需要已知该变量的均值和标准差,再将该数值带入到上面的公式即可。
有关朴素贝叶斯分类器的理论部分就讲解到这里,希望读者能够理解,如果您还有不明白的地方可以给我留言。接下来我们就看一下,在R语言中,是如何实现朴素贝叶斯算法的落地的。
R语言函数简介
R语言中的klaR包就提供了朴素贝叶斯算法实现的函数NaiveBayes,我们来看一下该函数的用法及参数含义:
NaiveBayes(formula, data, ..., subset, na.action= na.pass)
NaiveBayes(x, grouping, prior, usekernel= FALSE, fL = 0, ...)
formula指定参与模型计算的变量,以公式形式给出,类似于y=x1+x2+x3;
data用于指定需要分析的数据对象;
na.action指定缺失值的处理方法,默认情况下不将缺失值纳入模型计算,也不会发生报错信息,当设为“na.omit”时则会删除含有缺失值的样本;
x指定需要处理的数据,可以是数据框形式,也可以是矩阵形式;
grouping为每个观测样本指定所属类别;
prior可为各个类别指定先验概率,默认情况下用各个类别的样本比例作为先验概率;
usekernel指定密度估计的方法(在无法判断数据的分布时,采用密度密度估计方法),默认情况下使用正态分布密度估计,设为TRUE时,则使用核密度估计方法;
fL指定是否进行拉普拉斯修正,默认情况下不对数据进行修正,当数据量较小时,可以设置该参数为1,即进行拉普拉斯修正。
R语言实战
本次实战内容的数据来自于UCI机器学习网站,后文会给出数据集合源代码的链接。
# 下载并加载所需的应用包
if(!suppressWarnings(require('caret'))){
install.packages('caret')
require('caret')
}
if(!suppressWarnings(require('klaR'))){
install.packages('klaR')
require('klaR')
}
if(!suppressWarnings(require('pROC'))){
install.packages('pROC')
require('pROC')
}
# 读取蘑菇数据集
mydata <- read.csv(file = file.choose())
# 简单的了解一下数据
str(mydata)
summary(mydata)
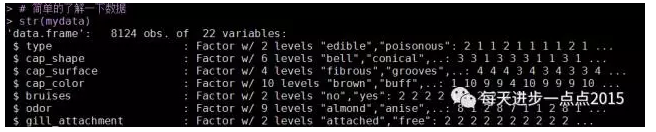
该数据集中包含了8124个样本和22个变量(如蘑菇的颜色、形状、光滑度等)。
# 抽样,并将总体分为训练集和测试集
set.seed(12)
index <- sample(1:nrow(mydata), size = 0.75*nrow(mydata))
train <- mydata[index,]
test <- mydata[-index,]
# 大致查看抽样与总体之间是否吻合
prop.table(table(mydata$type))
prop.table(table(train$type))
prop.table(table(test$type))
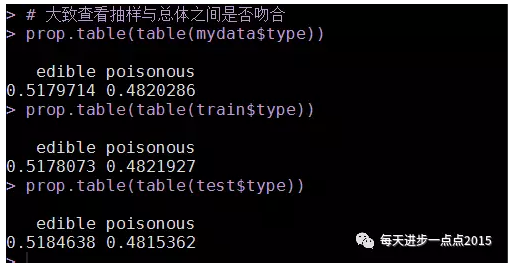
原始数据中毒蘑菇与非毒蘑菇之间的比较比较接近,通过抽选训练集和测试集,发现比重与总体比例大致一样,故可认为抽样的结果能够反映总体状况,可进一步进行建模和测试。
由于影响蘑菇是否有毒的变量有21个,可以先试着做一下特征选择,这里我们就采用随机森林方法(借助caret包实现特征选择的工作)进行重要变量的选择:
#构建rfe函数的控制参数(使用随机森林函数和10重交叉验证抽样方法,并抽取5组样本)
rfeControls_rf <- rfeControl(
functions = rfFuncs,
method = 'cv',
repeats = 5)
#使用rfe函数进行特征选择
fs_nb <- rfe(x = train[,-1],
y = train[,1],
sizes = seq(4,21,2),
rfeControl = rfeControls_rf)
fs_nb
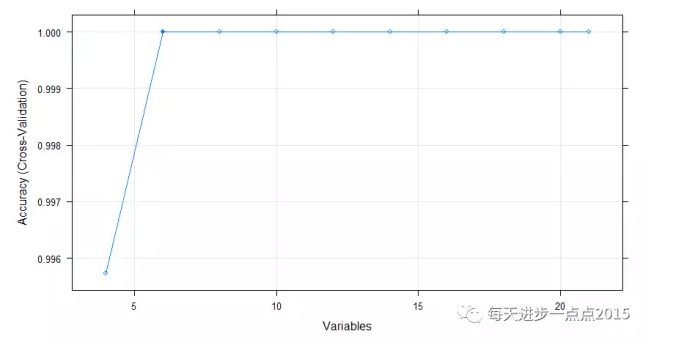
plot(fs_nb, type = c('g','o'))
fs_nb$optVariables
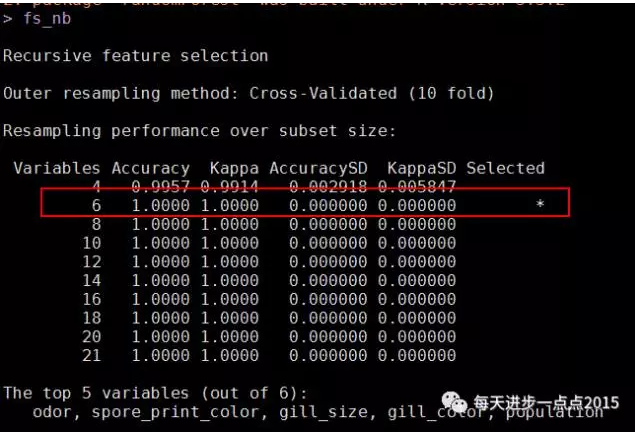
结果显示,21个变量中,只需要选择6个变量即可,下图也可以说明这一点:
所需要选择的变量是:

接下来,我们就针对这6个变量,使用朴素贝叶斯算法进行建模和预测:
# 使用klaR包中的NaiveBayes函数构建朴素贝叶斯算法
vars <- c('type',fs_nb$optVariables)
fit <- NaiveBayes(type ~ ., data = train[,vars])
# 预测
pred <- predict(fit, newdata = test[,vars][,-1])
# 构建混淆矩阵
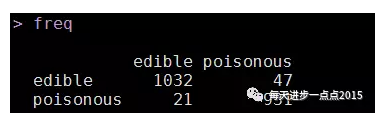
freq <- table(pred$class, test[,1])
freq
# 模型的准确率
accuracy <- sum(diag(freq))/sum(freq)
accuracy

# 模型的AUC值
modelroc <- roc(as.integer(test[,1]),
as.integer(factor(pred$class)))
# 绘制ROC曲线
plot(modelroc, print.auc = TRUE, auc.polygon = TRUE,
grid = c(0.1,0.2), grid.col = c('green','red'),
max.auc.polygon = TRUE, auc.polygon.col = 'steelblue')
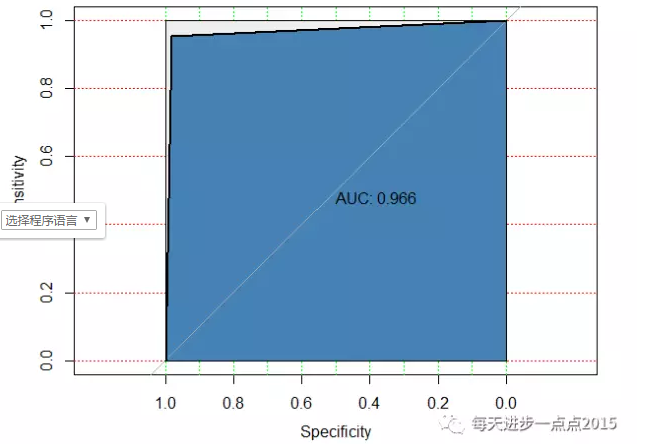
通过朴素贝叶斯模型,在测试集中,模型的准确率约为97%,而且AUC的值也非常高,一般超过0.8就说明模型比较理想了。
好了,关于朴素贝叶斯分类器的理论和应用的讲解就到这里,如有不理解的朋友还可以继续交流。
数据与源代码链接:
链接:http://pan.baidu.com/s/1dEBGvC1 密码:loqg
每天进步一点点2015
学习与分享,取长补短,关注小号!

长按识别二维码 马上关注
