文本分析是目前比较热门的一项研究,例如如何切词、文档矩阵的建立、主题模型的应用、文档聚类、分类、情感分析等。就情感分析而言,目前比较流行的方法有两种,一是词库法、二是机器学习法。词库法在下一段落中介绍其思想,而机器学习法则是在已知分类语料的情况下,构建文档--词条矩阵,然后应该各种分类算法(knn、NB、RF、SVM、DL等),预测出其他句子的情感。在此就分享一下自己如何通过词库的方式为每一句评论定性为正面或负面。
通过词库的方式定性每一句话的情感没有什么高深的理论基础,其思想就是对每一句话进行分词,然后对比正面词库与负面词库,从而计算出句子的正面得分(词中有多少是正面的)与负面得分(词中有多少是负面的),以及综合得分(正面得分-负面得分)。虽然该方法通俗易懂,但是非常耗人力成本,如正负面词库的构建、自定义词典的导入等。
言归正传,接下来我们就以某汽车的空间评论数据作为分析对象,来给每条评论打上正面或负面的标签:
# 导入所需的开发包
library(readxl)
library(jiebaR)
library(plyr)
library(wordcloud2)
# 读入评论数据
evaluation <- read_excel(file.choose())
head(evaluation)
str(evaluation)
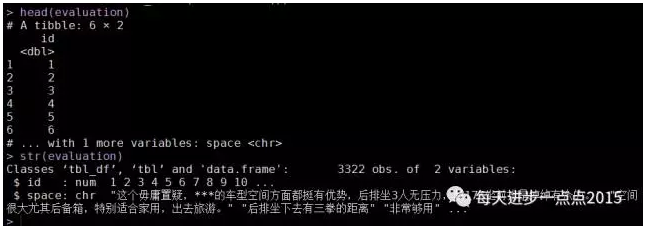
数据集中包含了两个变量,一个是用户id,一个是用户的具体评价内容(字符串类型)。
# 读入正负面词库及停止词
pos <- readLines(file.choose(), encoding = 'UTF-8')
neg <- readLines(file.choose(), encoding = 'UTF-8')
stopwords <- readLines(file.choose(), encoding = 'UTF-8')
# 合并情感词库
mydict <- c(pos, neg)
# 为jieba分词准备工作引擎
engine <- worker()
往jieba分词引擎中添加自定义词汇,目的是能够将一些词正常的切开。
# 例如,不添加自定义词汇
sentence <- '超韧细密,湿水不易破'
segment(sentence, engine)
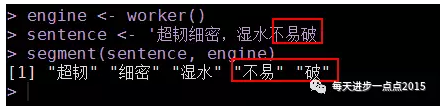
“不易破”被分成了两个词,显然意思就变了,如何使“不易破”被整体切割出来呢?采用的办法是添加自定义词汇。
# 添加自定义词汇
new_user_word(engine, '不易破')
segment(sentence, engine)

# 将正负面词加入到自定义词库中
new_user_word(engine, mydict)
# 对每一条评论进行切词
segwords <- sapply(evaluation$space, segment, engine)
head(segwords)

# 删除停止词(即对分析没有意义的词,如介词、虚词等)
# 自定义函数:用于删除停止词
removewords <- function(target_words,stop_words){
target_words = target_words[target_words%in%stop_words==FALSE]
return(target_words)
}
# 删除一个字的词
segwords2 <- sapply(segwords, removewords, stopwords)
head(segwords2)
#自定义情感类型得分函数
fun <- function(x,y) x %in% y
getEmotionalType <- function(x,pwords,nwords){
pos.weight = sapply(llply(x,fun,pwords),sum)
neg.weight = sapply(llply(x,fun,nwords),sum)
total = pos.weight - neg.weight
return(data.frame(pos.weight, neg.weight, total))
}
# 计算每条评论的正负得分
score <- getEmotionalType(segwords2, pos, neg)
head(score)
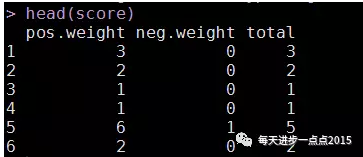
# 将原始数据与得分数据进行合并
evalu.score <- cbind(evaluation, score)
为给每个评论打上正负情感的标签,不妨将总得分大于等于0的记录设置为正面情感,小于0的记录设置为负面情感。
evalu.score <- transform(evalu.score,
emotion = ifelse(total>=0, 'Pos', 'Neg'))
# 随机挑选10条评论,做一个验证
set.seed(1)
validation <- evalu.score[sample(1:nrow(evalu.score),
size = 10),]
validation[,c(2,6)]
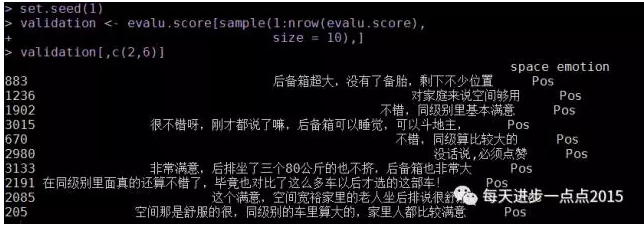
通过验证,发现随机挑选的10条评论与判定的情感还是非常吻合的。
不妨,我们再对评论数据绘制文字云。
# 计算词频
wf <- unlist(segwords2)
wf <- as.data.frame(table(wf))
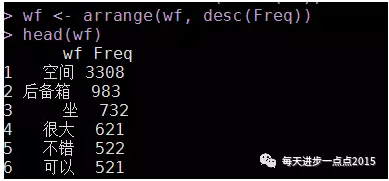
wf <- arrange(wf, desc(Freq))
head(wf)
# 绘制Top50的词云
wordcloud2(wf[1:50,], backgroundColor = 'black')

有很多一个字的词在词云中,影响了表达的内容,不妨我们在词云中只保留包含2个字及以上的词。
#自定义函数:保留至少2个字符长度的词语
more2words <- function(x){
words = c()
for (word in x) {
if (nchar(word)>1) words = c(words,word)
}
return(words)
}
segwords3 <- more2words(unlist(segwords2))
# 计算词频
wf2 <- unlist(segwords3)
wf2 <- as.data.frame(table(wf2))
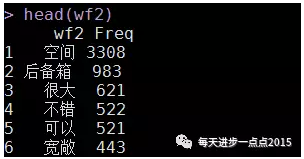
wf2 <- arrange(wf2, desc(Freq))
head(wf2)
# 绘制Top50的词云
wordcloud2(wf2[1:50,], backgroundColor = 'black')

由于该评论就是针对汽车的空间加以说明的,显然词云中的“空间”的存在并没有意义。
wordcloud2(wf2[2:51,], backgroundColor = 'black')

通过文字云绘制结果可以判断,消费者还是非常认可该款汽车的空间大小,普遍表示满意,表达了空间宽敞、足够用的心情。
OK, 有关基于词库的情感分析就讲到这里,虽然在一定程度上保证了预判的准确性,但前期的人工构造词典是非常耗时耗力的,后期我们将尝试用机器学习的方法来对评论做情感预判。
本文的数据及源代码下载链接:
链接:http://pan.baidu.com/s/1slauy1B 密码:1oi4
每天进步一点点2015
学习与分享,取长补短,关注小号!


