自打春节后从家里回到学校以来就一直在捣鼓爬虫,总琢磨着个抓些数据来玩玩,在文档里保存一些自己的datasets。从一开始学Python3写scrapy框架到现在的rvest包R语言数据抓取,好歹有了自己固定的爬虫操作模式,这期间学着别人爬过当当网的商品数据,爬过豆瓣电影和图书top250,还爬过前程无忧的招聘信息等等,既然有了一些R语言的爬虫经验,那这个公众号的第一次推送就从用rvest+SelectorGadget抓取链接杭州二手房数据开始吧。
rvest包简介
rvest包是Hadley Wickham大神开发的一个专门用于网络数据抓取的R语言包,目前的发行版本为0.3.2,关于rvest包的描述以及用法可参考rvest帮助文档,花上一点时间阅读帮助文档,相信你就可以写出自己的爬虫了。
help(package=“rvest”)
rvest帮助文档: http://127.0.0.1:17483/library/rvest/html/00Index.html
csdn中文版版:
http://blog.csdn.net/sadfasdgaaaasdfa/article/details/45372307
rvest包基础语法
library(rvest)
google <- read_html("http://google.com", encoding = "ISO-8859-1")
#解析网页,规定编码
google %>% xml_structure()
google %>% html_nodes("div")%>% html_text()
#根据html标签节点读取位置信息,抓取想要的数据
SelectorGadget简介
http://selectorgadget.com/
SelectorGadget是一款开源工具,为复杂网站的元素生成CSS选择器,有了这款神器,在定位html节点信息时将变得无比轻松,也支持Xpath表达式。
rvest+SelectorGadget抓取杭州二手房信息
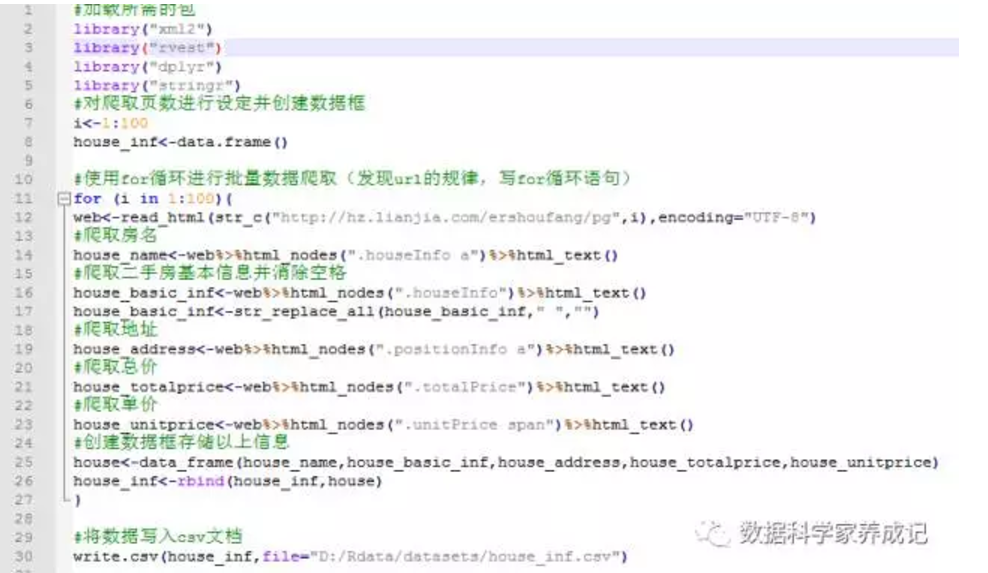
#加载所需的包
library("xml2")
library("rvest")
library("dplyr")
library("stringr")
#对爬取页数进行设定并创建数据框
i<-1:100
house_inf<-data.frame()
#使用for循环进行批量数据爬取(发现url的规律,写for循环语句)
for (i in 1:100){
web<- read_html(str_c("http://hz.lianjia.com/ershoufang/pg",i),encoding="UTF-8")
#用SelectorGadget定位节点信息并爬取房名
house_name<-web%>%html_nodes(".houseInfo a")%>%html_text()
#爬取二手房基本信息并消除空格
house_basic_inf<-web%>%html_nodes(".houseInfo")%>%html_text()
house_basic_inf<-str_replace_all(house_basic_inf," ","")
#SelectorGadget定位节点信息爬取地址
house_address<-web%>%html_nodes(".positionInfo a")%>%html_text()
#SelectorGadget定位节点信息爬取总价
house_totalprice<-web%>%html_nodes(".totalPrice")%>%html_text()
#SelectorGadget定位节点信息爬取单价
house_unitprice<-web%>%html_nodes(".unitPrice span")%>%html_text()
#创建数据框存储以上信息
house<-data_frame(house_name,house_basic_inf,house_address,house_totalprice,house_unitprice)
house_inf<-rbind(house_inf,house)
}
#将数据写入csv文档
write.csv(house_inf,file="D:/Rdata/datasets/house_inf.csv")
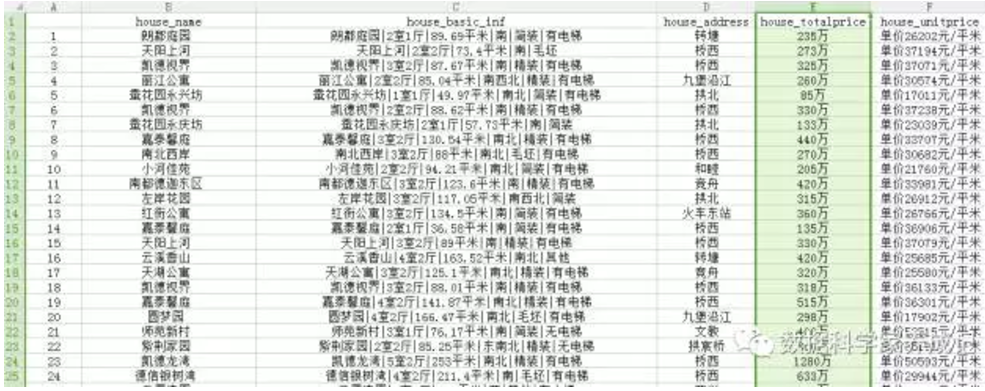
总共抓取了链家杭州二手房100个页面3000条房价信息,抓取数据如图所示:
总结
用rvest包结合SelectorGadget CSS选择器能够快速实现R语言下的网络数据抓取,并适当结合stringr包中的字符串处理函数对网页数据进行清洗和整理,既省时也省力。

