优化阅读Python练习第九题,爬取贴吧图片
一、问题:用 Python爬取妹子图片 :)
杉本有美_杉本有美吧_百度贴吧

二、分析贴吧网页源码
打开网页杉本有美_杉本有美吧_百度贴吧,F12
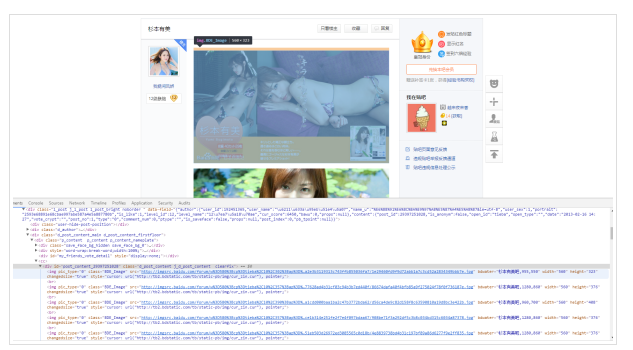
发现图片链接都在<img>标签中
<cc>
<div...>
<img...>
<img...>
测试发现,src中的链接就是图片链接。那么就很简单,只需要把<img>中的src的链接拿出来即可。
三、写代码
环境:Python3,Pycharm
使用requests和xpath,最近才学了xpath,发现超级好用,比bs4简洁,有兴趣看看这个爬虫入门到精通-网页的解析(xpath) - 知乎专栏
import requests
from lxml import etree
url = 'http://tieba.baidu.com/p/2166231880'
header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = requests.get(url,headers=header).content
s = etree.HTML(r)
print(s.xpath('//div/img/@src'))
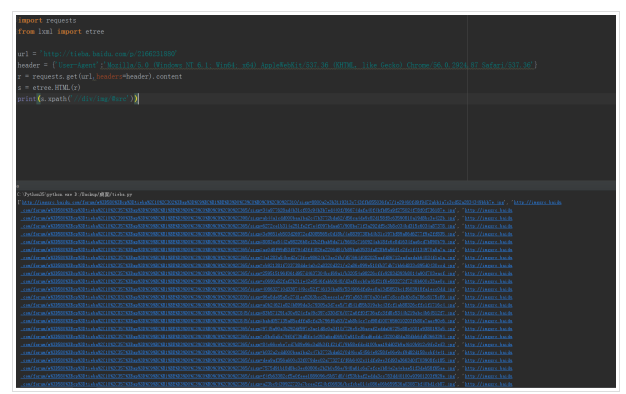
发现链接都已经拿到手,下一步就是下载了~
下载图片的语句:
import urllib.request
path = '......' #下载链接
jpg_link = '......' #图片链接
request.urlretrieve(jpg_link, path)
加在一起,大功告成。
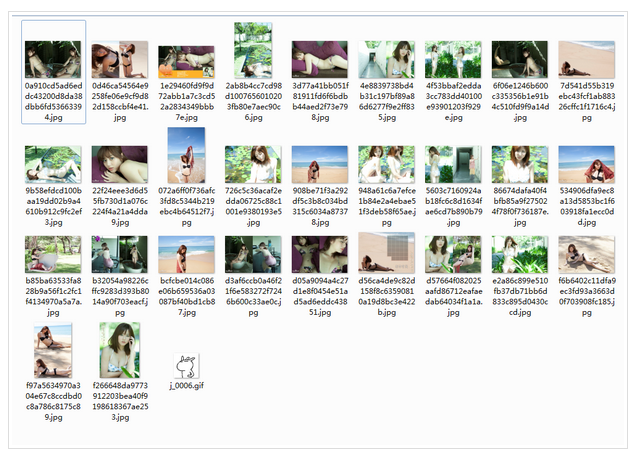
四、总结
经测试,贴吧里面其他网页如:[Sabra][08-04]strictly GIRLS瀬戸早妃
本代码都可以下载,顺便说一说问题。
1、图片名称使用图片链接中的名称,包含大量数字和字母,可以优化。
2、可以看到,下载文件中包含了一个表情,查看那是用户所发,说明筛选出了问题。
3、帖子数量多,翻页过后,需要在代码中加入获取下一页链接。
除此之外,还有什么问题呢?
源码请见:https://github.com/zhangslob/TiebaImg

