

本章内容:
- K-近邻分类算法
- 从文本文件中解析和导入数据
- 使用matplotlib创建扩散图
- 归一化数值
2-1 K-近邻算法概述
简单的说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
K-近邻算法
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和标称型
K-近邻算法(KNN),工作原理:
- 存在一个样本数据集合,称之为训练样本集,并且样本集中的每个数据都存在标签,即我们知道集中每一数据与所属分类的对应关系。
- 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。
- 一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。
- 最后,选择K个最相似数据出现次数最多的分类,作为新数据的分类。
数学公式

K-近邻算法的一般流程
- 收集数据:可以使用任何方法
- 准备数据:距离计算所需要的数值,最好是结构化的数据格式
- 分析数据:可以使用任何方法
- 训练算法:此步骤不适用于K-近邻算法
- 测试算法:计算错误率
- 使用算法:首先需要输入样本数据和结构化的输出结果,然后运行K-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
2.1.1 准备:使用python导入数据
首先,我们创建名为kNN.py的python模块。
from numpy import *
import operator
def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
上面的代码中,我们导入了两个模块,第一个是科学计算包NumPy,第二个是运算符模块,k-近邻算法执行排序操作使用这个模块提供的函数。
我们现在要引入自定义的kNN模块。
要在python shell中调用这个函数,进入python交互开发环境
我们先使用os模块,
查看当前路径 os.getcwd()
更改当前路径 os.chdir()
In [16]: import os
In [17]: os.getcwd()
Out[17]: 'C:\\Users\\Administrator'
In [18]: os.chdir("H:\ML")
In [19]: import kNN
In [20]: group,labels=kNN.createDataSet()
In [21]: group
Out[21]:
array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]])
In [24]: labels
Out[24]: ['A', 'A', 'B', 'B']
2.1.2 从文本文件中解析数据
我们给出k-近邻算法的伪代码和实际的python代码。
伪代码如下:
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k和点;
(4)确定前k个点所在类别的出现频率;
(5)返回当前k和点出现频率最高类别作为当前点的预测分类;
python函数classify0() 代码如下:
def classify0(inX,dataSet,labels,k):
"""应用KNN方法对测试点进行分类,返回一个结果类型
Keyword argument:
testData: 待测试点,格式为数组
dataSet: 训练样本集合,格式为矩阵
labels: 训练样本类型集合,格式为数组
k: 近邻点数
"""
dataSetSize=dataSet.shape[0]
#距离计算,新的数据与样本的距离进行减法
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat=diffMat**2 #对数组的每一项进行平方
sqDistances=sqDiffMat.sum(axis=1) #数组每个特征值进行求和
distances=sqDistances**0.5 #每个值开方
sortedDistIndicies = distances.argsort() 索引值排序
#选取距离最小的前k个值进行索引,从k个中选取分类最多的一个作为新数据的分类
classCount={}
for i in range(k): #统计前k个点所属类别
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount=sorted(classCount.iteritems(),
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0] #返回前k个点钟频率最高的类别
程序中使用了欧氏距离公式,计算两个向量点xA和xB之间的距离

kNN算法核心:
(1)计算当前点和训练集中的每个点的欧式距离
(2)从小到大排列训练集中前k个点
(3)返回这些点中出现频率最高的
python函数classify0() 代码 语法解析:
1.用于分类的向量是inX,输入训练样本集为dataSet,标签向量为labels,参数k表示用于选择最近邻居的数目,其中标签向量的元素数目和矩阵dataSet的行数相同。
2. shape返回array的大小,shape[0] 为第一维大小(训练集数据量)
3.tile(inX,(dataSetSize,1)-dataSet) :把inX按照(dataSetSize,1的形式复制,即:(dataSetSize,1是一个矩阵,把矩阵的每个元素用inX替代的就是最后结果。
例如:
In [31]: import numpy as np
In [32]: a=np.array([0,1,2])
In [34]: np.tile(a,2)
Out[34]: array([0, 1, 2, 0, 1, 2])
In [35]: np.tile(a,(2,2))
Out[35]:
array([[0, 1, 2, 0, 1, 2],
[0, 1, 2, 0, 1, 2]])
In [36]: b=np.array=[[4,5],[6,7]]
In [37]: np.tile(b,2)
Out[37]:
array([[4, 5, 4, 5],
[6, 7, 6, 7]])
4. argsort() ,返回排序后的下标array
5. 字典dict.get(key,x)查找键为key的value,如果不存在返回x
6.operator.itemgetter(1)返回的对象是第i+1个元素,相当于匿名函数
测试算法:
In [85]: import kNN
In [86]: reload(kNN)
Out[86]: <module 'kNN' from 'kNN.pyc'>
In [87]: group,labels=kNN.createDataSet()
In [88]: group,labels
Out[88]:
(array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]]), ['A', 'A', 'B', 'B'])
In [89]: kNN.classify0([0,0],group,labels,3)
Out[89]: 'B'
测试结果,[0,0]属于分类B 。
2.2 使用K-近邻算法来改进约会网站
- 示例:在约会网站上使用K-近邻算法
- 收集数据:提供文本文件
- 准备数据:使用python解析文本文件
- 分析数据:使用matplotlib画二维扩散图
- 训练算法:此步骤不适应于K-近邻算法
- 测试算法:使用海伦提供的部分数据作为测试样本
- 测试样本和非测试样本的区别在于:测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。
- 使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型
2.2.1 准备数据:从文本文件中解析数据
海伦的数据样本特征:
- 每年获得的飞行常客里程数
- 玩视频游戏所耗时间百分比
- 每周消费的冰淇淋公升数
我们将海伦提供的样本特征数据输入到分类器之前,必须将待处理的数据格式转换为分类器可以接受的格式。
我们在kNN.py中创建名为file2matrix的函数,用来处理输入格式问题。
该函数的输入为文本名字符串,输出为训练样本矩阵的和类标签向量。
将下列的代码增加到kNN.py中:
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
#得到文本行数
numberOfLines=len(arrayOLines)
#创建返回的numpy矩阵
returnMat=zeros((numberOfLines,3))
classLabelVector = []
index=0
#解析文本数据到列表
for line in arrayOLines:
line=line.strip() #截取掉所有回车字符
listFromLine=line.split('\t') #以指定字符为分割符分割字符串,不指定则为空格
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index +=1
return returnMat,classLabelVector
我们需要重新加载kNN模块,否则python还是使用之前的加载的模块。
In [46]: import kNN
In [47]: reload(kNN)
Out[47]: <module 'kNN' from 'kNN.pyc'>
In [48]: datingDataMat,datingLabels =kNN.file2matrix('datingTestSet2.txt')
In [49]: datingDataMat
Out[49]:
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])
In [50]: datingLabels[0:20]
Out[50]: [3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3]
我们已经导入数据,接下来需要了解数据的真实含义,一般来说,除了浏览数据,我们会采用图形化的方式直观的去展示数据。
2.2. 分析数据:使用matplotlib创建散点图
In [60]: import numpy as np
...: import matplotlib
...: import matplotlib.pyplot as plt
In [64]: fig = plt.figure() #创建一张新的图像
...: ax=fig.add_subplot(111) #表示把图像分割为1行1列,当前子图像画在第1块
#scatter(X,Y) 以X为x坐标,Y为y坐标绘制散点图
...: ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
...: ax.axis([-2,25,-0.2,2.0])
...: plt.ylabel('Kilogram of ice cream per week')
...: plt.xlabel('Percentage of time spent playing games')
...: plt.show()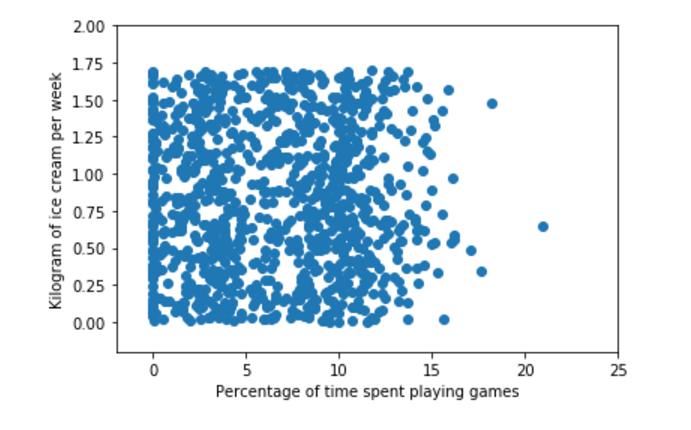
没有使用样本分类的特征值,很难从上图中看到任何有用的数据模式信息。为此,我们重新采用彩色的来标记不同样本。
In [65]: fig = plt.figure()
...: ax=fig.add_subplot(111)
...: ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*np.array(datingLabels), 15.0*np.array(datingLabels))
...: ax.axis([-2,25,-0.2,2.0])
...: plt.ylabel('Kilogram of ice cream per week')
...: plt.xlabel('Percentage of time spent playing games')
...: plt.show()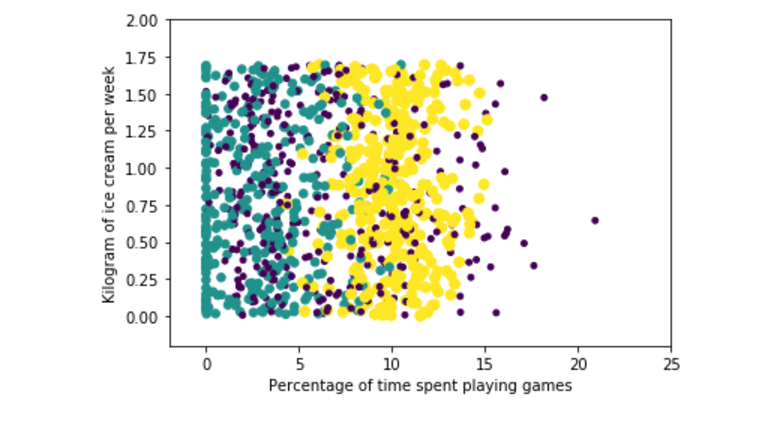
In [66]: fig = plt.figure()
...: ax=fig.add_subplot(111)
...: ax.scatter(datingDataMat[:,0], datingDataMat[:,1], 15.0*array(datingLabels),15.0*array(datingLabels))
...: plt.ylabel('Percentage of time spent playing games')
...: plt.xlabel('The number of frequent flier miles per year')
...: plt.show()
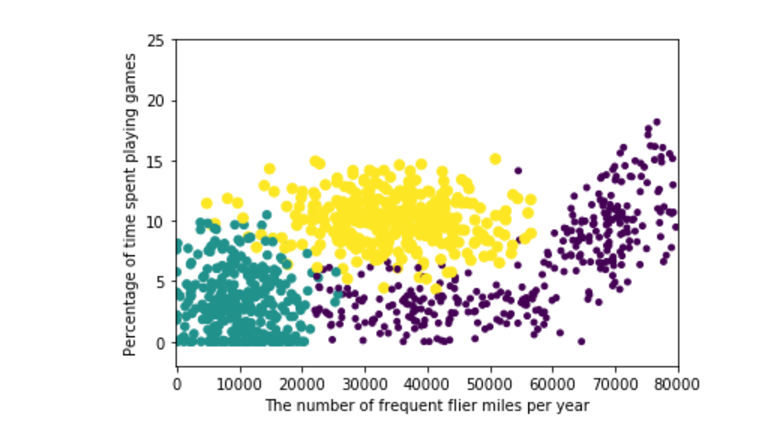
散点图使用datingDataMat矩阵的第一、第二列数据,分别表示特征值“每年获得的飞行常客里程数”和“玩视频游戏所耗时间百分比”。
图中给出了不同样本分类区域。
2.2.3 准备数据:归一化数据
不同的特征值将会有不同的取值和范围,如果直接使用特征值来计算距离,取值范围较大的特征值将会对结果产生较大的影响,取值范围小的值将会对结果产生很小的影响。这使得较小的特征值没有起到作用。
如两组特征:{0, 20000, 1.1}和{67, 32000, 0.1},计算距离的算式为:
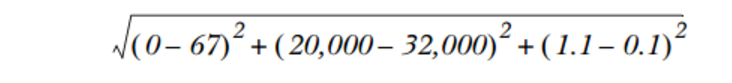
那我们看到上面的计算式里面,只有第二个特征会产生很大的影响,第一个,第三个特征则影响很小,甚至可以忽略掉。
但是三个特征是同等重要的,因此三个等权重的特征之一,飞行时间不能去这么严重的影响结果。
处理上面的问题,我们采用的方式是将数据值归一化:
如将取值范围处理为0到1 的或者-1到1之间。给出一个公式,可以将任意取值范围的特征值转换为0到1区间的值:
newValue=(oldValue-min)/(max-min)
其中,max和min分别是数据集中最大和最小的特征值。
虽然我们改变取值范围增加了分类器的复杂度,但是可以得到准确的结果。
接下来我们在kNN.py中增加一个函数autoNorm(),这个函数可以自动将数字特征值转化为0到1之间的区间。
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(m,1))
#特征值相除
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals
检测函数执行结果:
In [99]: import kNN
In [100]: reload(kNN)
Out[100]: <module 'kNN' from 'kNN.py'>
In [101]: normMat,ranges,minVals=kNN.autoNorm(datingDataMat)
In [102]: normMat
Out[102]:
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])
In [103]: ranges
Out[103]: array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00])
In [104]: minVals
Out[104]: array([ 0. , 0. , 0.001156])
2.2.4 测试算法:作为完整程序验证分类器
我们将测试分类器的效果,如果分类器的正确率满足要求,海伦就可以使用这个名单来处理约会网站这个事情了。
机器学习算法重要的一个工作就是:评估算法的正确率为多少。
通常我们给出样本数据的90%作为训练样本来训练分类器,剩下的10%的数据去测试分类器,检测分类器的正确率。值得注意的是:10%的数据应该是随机选择的。
对于分类器:错误率就是分类器给出错误结果的次数除以测试数据的总数。完美分类器的错误率为0,错误率为1的分类就不会有正确结果。
下面给出分类器针对约会网站的测试代码
def datingClassTest():
hoRatio=0.10
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],\
datingLabels[numTestVecs:m],3)
print "the classifier came back with:%d,the real anwer is:%d"\
% (classifierResult,datingLabels[i])
if (classifierResult!=datingLabels[i]):errorCount +=1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
接下来我们执行分类器的测试程序:
In [112]: import kNN
In [113]: reload(kNN)
Out[113]: <module 'kNN' from 'kNN.py'>
In [114]: kNN.datingClassTest()
the classifier came back with:3,the real anwer is:3
the classifier came back with:2,the real anwer is:2
the classifier came back with:1,the real anwer is:1
...
...
the classifier came back with:2,the real anwer is:2
the classifier came back with:1,the real anwer is:1
the classifier came back with:3,the real anwer is:1
the total error rate is: 0.050000
我们看到最终分类器的处理约会数据集的错误率为5%,这是相对不错的结果。
我们可以改变函数datingClassTest内变量hoRatio和变量k的值,检测错误率是否随着变化量值的变化而增加。
这个例子表明我们可以正确地预测分类,错误率仅仅是2.4%。海伦完全可以输入未知对象的属性信息,由分类软件来帮助她判定某一对象的可交往程度:讨厌、一般喜欢、非常喜欢。
2.2.5使用算法:构建完整的可用系统
上面我们已经在数据上对分类器进行测试,现在就额可以去使用这个分类器来对人们进行分类。
我们给出下面的代码,海伦只需要在约会网站上找到某个人输入信息,代码就可以给出她的喜欢程度的预测值。
我们将代码添加到kNN.py中:(约会网站预函数)
def classifyPerson():
resultList=['not at all','in small dose','in large doses']
percentTats=float(raw_input(\
"percentage of time spent playing video games?"))
ffMiles=float(raw_input("frequent flier miles earned per year?"))
iceCream=float(raw_input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
print "You will probably like this person:",\
resultList[classifierResult -1]
增加了一个运行三个月文本行输入命令的函数raw_input()
我们来检验实际运行效果:
In [127]: import kNN
In [128]: reload(kNN)
Out[128]: <module 'kNN' from 'kNN.py'>
In [129]: kNN.classifyPerson()
percentage of time spent playing video games?9
frequent flier miles earned per year?9000
liters of ice cream consumed per year?0.4
You will probably like this person: in small dose
我们看过最后输入数据之后,程序预测出这个人一点也不喜欢,这样海伦也许就没有必要进行这次约会,可以筛选下一个目标了。
下面给出所有代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 01 22:46:19 2017
@author: yi
"""
from numpy import *
import operator
def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
def classify0(inX,dataSet,labels,k):
"""应用KNN方法对测试点进行分类,返回一个结果类型
Keyword argument:
testData: 待测试点,格式为数组
dataSet: 训练样本集合,格式为矩阵
labels: 训练样本类型集合,格式为数组
k: 近邻点数
"""
dataSetSize=dataSet.shape[0]
#距离计算
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
#得到文本行数
numberOfLines=len(arrayOLines)
#创建返回的numpy矩阵
returnMat=zeros((numberOfLines,3))
classLabelVector = []
index=0
#解析文本数据到列表
for line in arrayOLines:
line=line.strip() #截取掉所有回车字符
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index +=1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(m,1))
#特征值相除
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals
def datingClassTest():
hoRatio=0.10
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],\
datingLabels[numTestVecs:m],3)
print "the classifier came back with:%d,the real anwer is:%d"\
% (classifierResult,datingLabels[i])
if (classifierResult!=datingLabels[i]):errorCount +=1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
def classifyPerson():
resultList=['not at all','in small dose','in large doses']
percentTats=float(raw_input("percentage of time spent playing video games?"))
ffMiles=float(raw_input("frequent flier miles earned per year?"))
iceCream=float(raw_input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
print "You will probably like this person:",resultList[classifierResult -1]
本文参考:
《机器学习实战》
http://blog.csdn.net/baoli1008/article/details/50708507
