评分系统是一种常见的推荐系统。现在使用R语言基于协同过滤算法来构建一个电影评分预测模型。
一,前提准备
1.R语言包:ggplot2包(绘图), recommenderlab包, reshape包(数据处理)
2.获取数据:大家可以在明尼苏达州大学的社会化计算研究中心官网上面下载这些免费数据集,网站链接为http://grouplens.org/datasets/movielens/。或公众号后台回复:943位用户对1682部电影影评数据 即可获取数据。
这里包含了数据集和数据说明,该数据集是由943位用户对1682部电影的一个评分,每个评分值为1,2,3,4,5。关于数据信息,在数据说明里面有详细的说明,这里就不再赘述。
二,数据处理
首先加载我们所需要的包:
library(recommenderlab)
library(reshape)
library(ggplot2)
接下来我们就要读取数据,如果数据在当前的工作目录,那么我们就可以在下面的代码里面直接输入数据名称,即u.data。当数据不在当前工作目录下的时候,我们就可以通过输入路径来读取数据。
mydata<-read.table("E:/my blog/R blog/movie/ml-100k/u.data",header = FALSE,stringsAsFactors = TRUE) #读取数据
代码里面的stringsAsFactors = TRUE表示表中的所有列都不是因子,是数值型数据。我们可以通过head()函数查看该数据集前6行的数据。第一列为用户ID,第二列电影ID,第三列是评分,第四列是用户评分的时间。这些在数据介绍中都要介绍。用户的评论时间对我们的分析没有用处,因此我们可以删掉这一列。
mydata<-mydata[,-4]
现在这份数据集只有三列。我要使用ggplot2分析用户对电影的评分结果。我决定要使用饼图来展现出结果,这样可以很好的展现评分列的分布特点。
ggplot(mydata,x=V3,aes(x=factor(1),fill=factor(V3)))+geom_bar(width = 1)+
coord_polar(theta="y")+ggtitle("评分分布图")+
labs(x="",y="")+
guides(fill=guide_legend(title = '评分分数'))
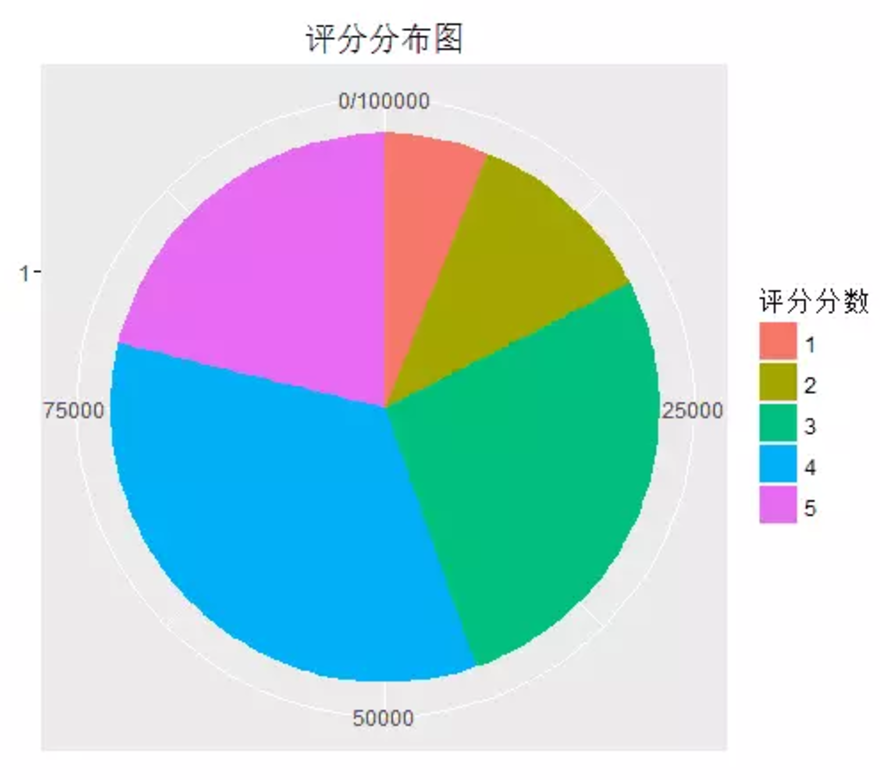
由图可知,评分为一分,两分的特别少,用户给出三分,四分的比较多,占了三分之二多。当一个新电影的评分低于3.5分时,差不多就失去了一半的用户。使用reshape包对数据进行处理,生成一个v1*v2,v3值的填充矩阵。
mydata<-cast(mydata,V1~V2,value="V3") #生成一个以v1为行,v2为列的矩阵,使用v3进行填充
mydata<-mydata[,-1] #第一列数字为序列,可以删除
这个时候,mydata有两个属性值cast_df 和data.frame,想要了解更多关于cast_df,可以查看下面这个网址:
https://www.r-statistics.com/tag/cast_df/ 。我们要将mydata属性改为数据框,其中cast_df是不能直接转换为matrix的,因此需要去掉这个类属性,只保留data.frame。
class(mydata)<-"data.frame"
接下来,我们仍要对数据进行处理,使之转换成recommenderlab包可以处理的realRatingMatrix属性。在下面,我们首先将mydata转化为一个矩阵,然后使用as()函数,进行强制类型转换,达到了我们要的结果。
mydata<-as.matrix(mydata)
mydata<-as(mydata,"realRatingMatrix") #生成一个943*1682realRatingMatrix类型的矩阵,包括了100000条记录
我们还需要给我每列数据命名,否则后面建模会出现报错。
colnames(mydata)<-paste0("M",1:1682,sep="")
as(mydata,"matrix")[1:6,1:6]
三,建立模型
在recommenderlab包里面,针对realRatingMatrix数据类型,总共提供了6种模型,分别是:基于项目协同过滤(IBCF), 主成分分析(PCA), 基于流行度推荐(POPULAR),随机推荐(RANDOM),奇异值分解(SVD),基于用户协同过滤算法(UBCF)。
协同过滤主要有两个步骤:
①依据目标用户的已知电影评分找到与目标用户观影风格相似的用户群。
②计算该用户群对其他电影的评分,并作为目标用户的预测评分。
这份数据是943位用户对1682部电影的一个评分,但每个人不可能将这些电影全都看完,而且不可能对所有看过的电影进行评分,因此我们我们刚刚生成的评分矩阵是一个非常稀疏,而且含有许多缺失值的矩阵。但这些并不影响协同过滤的工作效果。所以我们选择了协同过滤来建立我们的模型。
mydata.model <- Recommender( mydata[1:800], method = "UBCF")
mydata.predict <- predict(mydata.model,mydata[801:803], type="ratings")
#预测
as(mydata.predict,"matrix")[1:3,1:6]
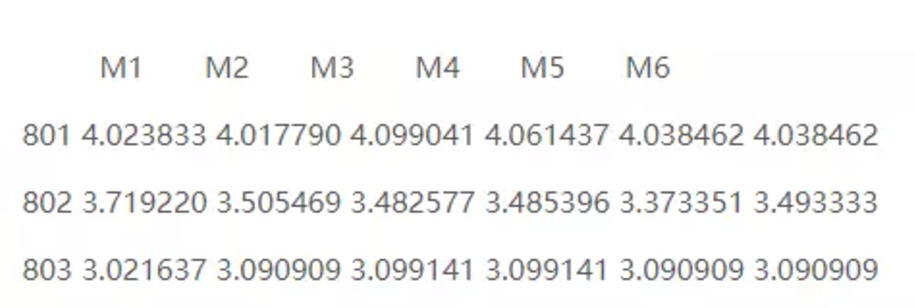
上面这就是对801,802,803用户对M1 M2 M3 M4 M5 M6的预测评分,评分基本都在3—4分之间,与之前我们分析结果相同。我们也可以给用户推荐电影,我们可以使用predict()函数,只需要给修改一下参数就行。
mydata.predict2 <- predict( mydata.model, mydata[801:803], n=5 )
as(mydata.predict2,"list")
运行结果如下:

这里表示的意思是给用户801推荐了电影有"M272" "M258" "M315" "M327" "M298"这么5个,其他代表含义相同。
参考书籍:R语言实战:编程基础,统计分析与数据挖掘宝典

7月11日谢老湿-重在实战!十五大案例,开启R语言实战之门金钥匙,
原价599 现价299
加微信直播管理员微信:HellobiLive(请注明:公司+姓名+行业) ,随后管理员会将你拉入到交流群中。
扫码咨询入群 (备注:R语言)

点击阅读原文+扫码立即参与学习


