
爬虫,往往都会想到用python来做,因为语言简洁,上手也方便。
但有时候就是会要求用java,这里就推荐一个java爬虫框架,webmagic。
WebMagic是一个简单灵活的Java爬虫框架,便于二次开发,提供简单灵活的API,只需少量代码即可实现一个爬虫。
详情可见:http://webmagic.io/
接下来,我们来动手实践一下吧。
目标解析
我们这个demo的目标是爬取天善最热博文列表(https://blog.hellobi.com/hot/weekly)对应的博文信息存入mysql数据库中。
我们需要从博文列表页获取每篇博文的url,并进入对应的url爬取博文的相关信息。
暂定的博文相关信息有:
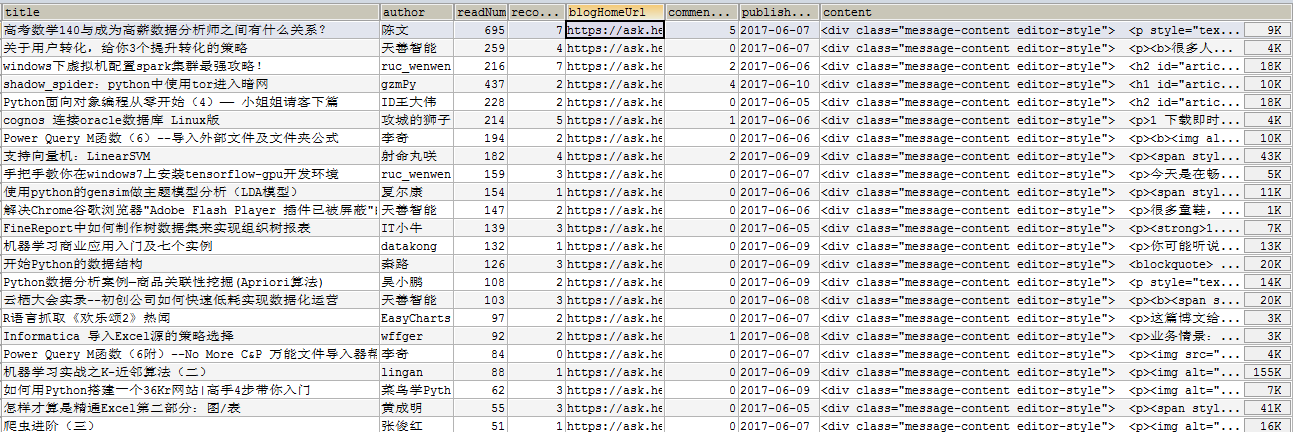
- 博文url::url
- 博文标题::title
- 博文作者::author
- 作者博客地址::blogHomeUrl
- 博文阅读数:readNum
- 博文推荐数:recommandNum
- 博文评论数:commentNum
- 博文内容:content
- 博文发表时间:publishTime
因此,根据相应的信息建表
CREATE TABLE `hot_weekly_blogs` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`url` VARCHAR(100) DEFAULT NULL,
`title` VARCHAR(100) DEFAULT NULL,
`author` VARCHAR(50) DEFAULT NULL,
`readNum` INT(11) DEFAULT NULL,
`recommendNum` INT(11) DEFAULT NULL,
`blogHomeUrl` VARCHAR(100) DEFAULT NULL,
`commentNum` INT(11) DEFAULT NULL,
`publishTime` VARCHAR(20) DEFAULT NULL,
`content` MEDIUMTEXT,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=69 DEFAULT CHARSET=utf8爬虫的思路一般离不开以下三点:
1.获取目标链接
2.抽取需要的信息
3.处理数据
获取目标链接
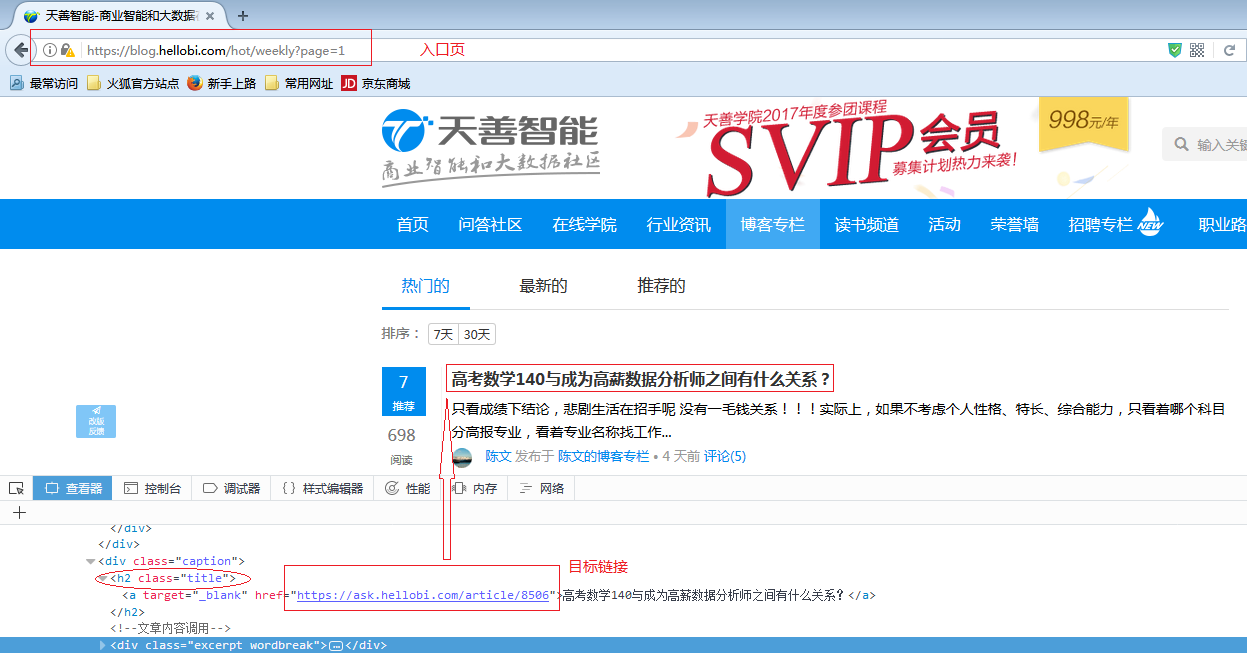
我们需要一个入口页,从入口页获取目标链接,如上图。我们需要将目标链接加入待爬取的集合里
page.addTargetRequests(page.getHtml().xpath("//h2[@class='title']/a").links().all());
抽取需要的信息
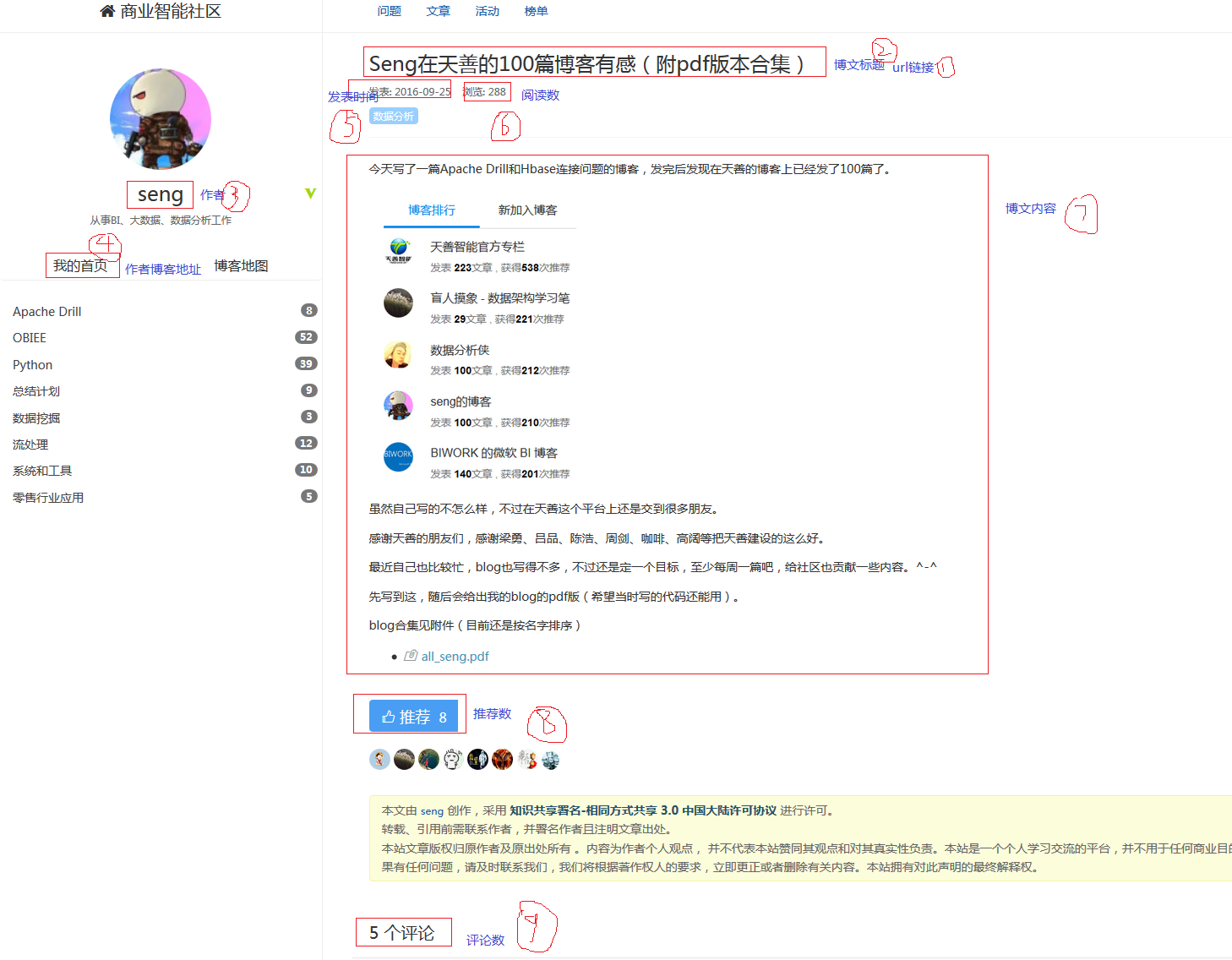
如上图是一篇博文的结构,标出了9个所需要抽取的信息。
确定好目标之后,我们就开始敲代码了。
步骤一:新建maven工程,添加依赖
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.6.1</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.6.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.42</version>
</dependency>
步骤二:创建对应的实体对象
public class BlogInfo {
private String url;
private String title;
private String author;
private String readNum;
private String recommendNum;
private String blogHomeUrl;
private String commentNum;
private String publishTime;
private String content;
// 篇幅太长,省略getter、setter和toString方法,可自己动手生成
}
步骤三:编写PageProcessor
PageProcessor中的process方法是webmagic的核心,负责抽取目标url的逻辑。
package test.repo;
import test.dao.BlogDao;
import test.dao.impl.BlogDaoImpl;
import test.entity.BlogInfo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Created by Administrator on 2017/6/11.
*/
public class BlogPageProcessor implements PageProcessor {
//抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(10).setSleepTime(1000);
//博文数量
private static int num = 0;
//数据库持久化对象,用于将博文信息存入数据库
private BlogDao blogDao = new BlogDaoImpl();
public static void main(String[] args) throws Exception {
long startTime ,endTime;
System.out.println("========天善最热博客小爬虫【启动】喽!=========");
startTime = new Date().getTime();
Spider.create(new BlogPageProcessor()).addUrl("https://blog.hellobi.com/hot/weekly?page=1").thread(5).run();
endTime = new Date().getTime();
System.out.println("========天善最热博客小爬虫【结束】喽!=========");
System.out.println("一共爬到"+num+"篇博客!用时为:"+(endTime-startTime)/1000+"s");
}
@Override
public void process(Page page) {
//1. 如果是博文列表页面 【入口页面】,将所有博文的详细页面的url放入target集合中。
// 并且添加下一页的url放入target集合中。
if(page.getUrl().regex("https://blog\\.hellobi\\.com/hot/weekly\\?page=\\d+").match()){
//目标链接
page.addTargetRequests(page.getHtml().xpath("//h2[@class='title']/a").links().all());
//下一页博文列表页链接
page.addTargetRequests(page.getHtml().xpath("//a[@rel='next']").links().all());
}
//2. 如果是博文详细页面
else {
// String content1 = page.getHtml().get();
try {
/*实例化BlogInfo,方便持久化存储。*/
BlogInfo blog = new BlogInfo();
//博文标题
String title = page.getHtml().xpath("//h1[@class='clearfix']/a/text()").get();
//博文url
String url = page.getHtml().xpath("//h1[@class='clearfix']/a/@href").get();
//博文作者
String author = page.getHtml().xpath("//section[@class='sidebar']/div/div/a[@class='aw-user-name']/text()").get();
//作者博客地址
String blogHomeUrl = page.getHtml().xpath("//section[@class='sidebar']/div/div/a[@class='aw-user-name']/@href").get();
//博文内容,这里只获取带html标签的内容,后续可再进一步处理
String content = page.getHtml().xpath("//div[@class='message-content editor-style']").get();
//推荐数(点赞数)
String recommendNum = page.getHtml().xpath("//a[@class='agree']/b/text()").get();
//评论数
String commentNum = page.getHtml().xpath("//div[@class='aw-mod']/div/h2/text()").get().split("个")[0].trim();
//阅读数(浏览数)
String readNum = page.getHtml().xpath("//div[@class='row']/div/div/div/div/span/text()").get().split(":")[1].trim();
//发布时间,发布时间需要处理,这一步获取原始信息
String time = page.getHtml().xpath("//time[@class='time']/text()").get().split(":")[1].trim();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
Calendar cal = Calendar.getInstance();// 取当前日期。
cal = Calendar.getInstance();
String publishTime = null;
Pattern p = Pattern.compile("^\\d{4}-\\d{2}-\\d{2}$");
Matcher m = p.matcher(time);
//如果time是“YYYY-mm-dd”这种格式的,则不需要处理
if (m.matches()) {
publishTime = time;
} else if (time.contains("天")) { //如果time包含“天”,如1天前,
int days = Integer.parseInt(time.split("天")[0].trim());//则获取对应的天数
cal.add(Calendar.DAY_OF_MONTH, -days);// 取当前日期的前days天.
publishTime = df.format(cal.getTime()); //并将时间转换为“YYYY-mm-dd”这个格式
} else {//time是其他格式,如几分钟前,几小时前,都为当日日期
publishTime = df.format(cal.getTime());
}
//对象赋值
blog.setUrl(url);
blog.setTitle(title);
blog.setAuthor(author);
blog.setBlogHomeUrl(blogHomeUrl);
blog.setCommentNum(commentNum);
blog.setRecommendNum(recommendNum);
blog.setReadNum(readNum);
blog.setContent(content);
blog.setPublishTime(publishTime);
num++;//博文数++
System.out.println("num:" + num + " " + blog.toString());//输出对象
blogDao.saveBlog(blog);//保存博文信息到数据库
}catch (Exception e){
e.printStackTrace();
}
}
}
@Override
public Site getSite() {
return this.site;
}
}
步骤四:处理数据
即将数据存入mysql数据库
Dao接口层
/**
* 博文 数据持久化 接口
* @author Jasmine
*/
public interface BlogDao {
/**
* 保存博文信息
* @param blog
* @return
*/
public int saveBlog(BlogInfo blog);
}
Dao实现类
/**
* 博客 数据库持久化接口 实现
* @author Jasmine
*/
public class BlogDaoImpl implements BlogDao{
@Override
public int saveBlog(BlogInfo blog) {
DBHelper dbhelper = new DBHelper();
StringBuffer sql = new StringBuffer();
sql.append("INSERT INTO hot_weekly_blogs(url,title,author,readNum,recommendNum,blogHomeUrl,commentNum,publishTime,content)")
.append("VALUES (? , ? , ? , ? , ? , ? , ? , ? , ? ) ");
//设置 sql values 的值
List<String> sqlValues = new ArrayList<>();
sqlValues.add(blog.getUrl());
sqlValues.add(blog.getTitle());
sqlValues.add(blog.getAuthor());
sqlValues.add(""+blog.getReadNum());
sqlValues.add(""+blog.getRecommendNum());
sqlValues.add(blog.getBlogHomeUrl());
sqlValues.add(""+blog.getCommentNum());
sqlValues.add(blog.getPublishTime());
sqlValues.add(blog.getContent());
int result = dbhelper.executeUpdate(sql.toString(), sqlValues);
return result;
}
}
步骤五:编写数据库工具类
这个工具类是采自网络,后续会改用mybaits来持久化。
public class DBHelper {
public static final String driver_class = "com.mysql.jdbc.Driver";
public static final String driver_url = "jdbc:mysql://localhost/spider?useunicode=true&characterEncoding=utf8";
public static final String user = "root";
public static final String password = "admin123";
private static Connection conn = null;
private PreparedStatement pst = null;
private ResultSet rst = null;
/**
* Connection
*/
public DBHelper() {
try {
conn = DBHelper.getConnInstance();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 单例模式
* 线程同步
* @return
*/
private static synchronized Connection getConnInstance() {
if(conn == null){
try {
Class.forName(driver_class);
conn = DriverManager.getConnection(driver_url, user, password);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("连接数据库成功");
}
return conn;
}
/**
* close
*/
public void close() {
try {
if (conn != null) {
DBHelper.conn.close();
}
if (pst != null) {
this.pst.close();
}
if (rst != null) {
this.rst.close();
}
System.out.println("关闭数据库成功");
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* query
*
* @param sql
* @param sqlValues
* @return ResultSet
*/
public ResultSet executeQuery(String sql, List<String> sqlValues) {
try {
pst = conn.prepareStatement(sql);
if (sqlValues != null && sqlValues.size() > 0) {
setSqlValues(pst, sqlValues);
}
rst = pst.executeQuery();
} catch (SQLException e) {
e.printStackTrace();
}
return rst;
}
/**
* update
*
* @param sql
* @param sqlValues
* @return result
*/
public int executeUpdate(String sql, List<String> sqlValues) {
int result = -1;
try {
pst = conn.prepareStatement(sql);
if (sqlValues != null && sqlValues.size() > 0) {
setSqlValues(pst, sqlValues);
}
result = pst.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
return result;
}
/**
* sql set value
*
* @param pst
* @param sqlValues
*/
private void setSqlValues(PreparedStatement pst, List<String> sqlValues) {
for (int i = 0; i < sqlValues.size(); i++) {
try {
pst.setObject(i + 1, sqlValues.get(i));
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
![]()

本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。