前言
这两天看了简单灵活的Java爬虫框架——webmagic,其使用Jsoup作为HTML解析工具。因此又看了Jsoup的文档(http://www.open-open.com/jsoup/),发现用起来也比较容易,方法和python中的beautifulsoup比较相像,也可直接用来爬数据。
1.加载包
下载jsoup-1.10.2.jar包(https://jsoup.org/packages/jsoup-1.10.2.jar),这是当前最新的包
如果使用maven构建java工程,则添加maven依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
2.过程与分析
下载url并解析成html Dom结构
String url="https://edu.hellobi.com/course/explore"
Document doc = Jsoup.connect(url).get();

经过页面分析,一页16个课程,分为4行,每行4个课程。
class为mt30的div是包含16个课程的元素,通过class名称获取元素,即采用类DOM的方法来查找元素
Elements container = doc.getElementsByClass("mt30");
Document containerDoc = Jsoup.parse(container.toString());
也可以使用select方法选择元素,参数是CSS Selector表达式,每行的课程在class="row"的元素里
Elements rows = containerDoc.select(".row");
然后对行循环,每行获取单个课程信息(即class为course-box的元素)
for (Element row : rows){
Document rowDc = Jsoup.parse(row.toString());
Elements courses = rowDc.select(".course-box");
}
再然后对每个课程循环,获取详细的课程包含的信息
for(Element course : courses) {
Elements link = course.select(".caption > h3 > a"); //选择器的形式
Elements length = course.select(".length");
Elements people = course.select(".people");
Elements teacher = course.select(".teacher > a");
Elements price = course.select(".price");
}
最后打印输出课程信息
System.out.println("课程名称:" + link.text());
System.out.println("课程链接:" + link.attr("href"));
System.out.println("课时长:" + length.text());
System.out.println("学习人数:" + people.text());
System.out.println("课程老师:" + teacher.text());
System.out.println("课程老师链接:" + teacher.attr("href"));
System.out.println("课程费用:" + price.text());
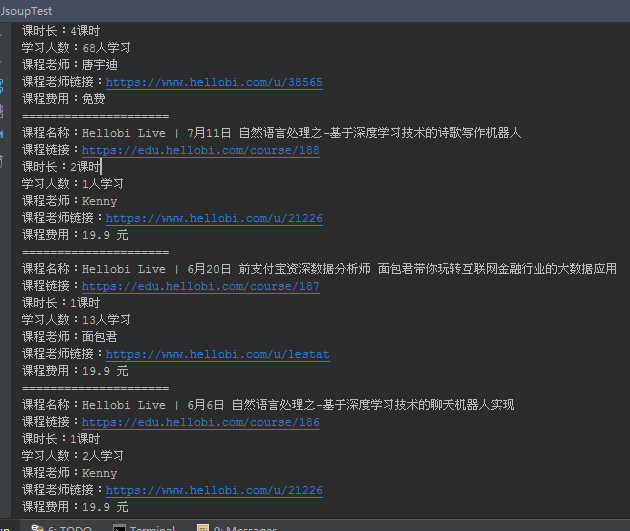
成功啦,结果显示如下:
最后附上完整的java代码
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) throws Exception {
String url="https://edu.hellobi.com/course/explore" ;
//这里对页码进行了循环,共获取10页的课程信息
for (int i=1; i <= 10; i++){
String s = String.valueOf(i);
String newUrl = url+"?page="+s;
getInfo(newUrl);
}
}
public static void getInfo(String url){
try {
// 下载url并解析成html DOM结构
Document doc = Jsoup.connect(url).get();
Elements container = doc.getElementsByClass("mt30");
Document containerDoc = Jsoup.parse(container.toString());
// 使用select方法选择元素,参数是CSS Selector表达式
Elements rows = containerDoc.select(".row");
for (Element row : rows){
Document rowDc = Jsoup.parse(row.toString());
Elements courses = rowDc.select(".course-box");
for(Element course : courses) {
Elements link = course.select(".caption > h3 > a"); //选择器的形式
Elements length = course.select(".length");
Elements people = course.select(".people");
Elements teacher = course.select(".teacher > a");
Elements price = course.select(".price");
System.out.println("课程名称:" + link.text());
System.out.println("课程链接:" + link.attr("href"));
System.out.println("课时长:" + length.text());
System.out.println("学习人数:" + people.text());
System.out.println("课程老师:" + teacher.text());
System.out.println("课程老师链接:" + teacher.attr("href"));
System.out.println("课程费用:" + price.text());
System.out.println("=====================");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}

