
学习了一段时间的scrapy爬虫框架,也模仿别人的写了几个。最近,在编写爬取拉勾网某职位相关信息的过程中,遇到一些小的问题,和之前一般的爬取静态网页略有不同,这次需要提取的部分信息是js生成的。记录一下,后续备查。
整个project的文件结构如下所示:
├── lagou_python
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ ├── lagou_spider.py
│ ├── middleware.py
│ └── rotate_useragent.py
└── scrapy.cfg
接下来,逐个分析一下。
首先,分析一下需要抓取的页面信息,招聘信息(城市为上海,职业为python)URL为:
http://www.lagou.com/jobs/list_Python?kd=Python&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=&lc=&workAddress=&city=%E4%B8%8A%E6%B5%B7&requestId=&pn=1
通过比较,后续的URL只是pn这个参数的值有变化。显然,只需要修改pn这个参数的值,就可以连续抓取不同网页的信息了。那么,总共有多少页呢,在Firebug中查看网页源码可以得到如下图所示的信息:
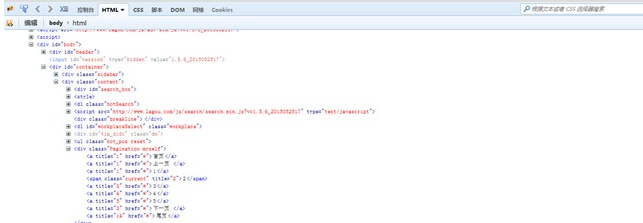
页面的分页是js实现的,应该是开发者修改了一个版本,不太像JQuery中的分页相关代码。js我只懂一点点,所以没有具体分析了。正好有看到scrapy如何处理带js的动态网页相关blog,我就尝试使用scrapy+python-webkit来进行处理。我虚拟机中采用的是Ubuntu14.04.2 Server版本,需要先安装几个包:
apt-get install python-webkit
apt-get install python-jswebkit
apt-get install Xvfb
完成安装之后,就可以在后面的project中让scrapy结合python-webkit来处理带js的动态网页了。我的初步理解是利用webkit处理带js的网页,然后scrapy抓取处理好的网页内容。拿到我的实例中来看,就是让webkit处理带js的网页,这样分页显示等处理都已经触发了,后续只要用xpath定为到最终呈现的页码处获取尾页的数字,然后自己构造后续的职位信息页码,让scrapy不断抓取就OK了。
在scrapy中来说,需要自定义下载中间件的处理类。我在project下建立了一个middleware.py的文件,后续在settings.py中把middleware的处理类添加进去。middleware.py中的内容如下:
from scrapy.http import Request, FormRequest, HtmlResponse
import gtk
import webkit
import jswebkit
from lagou_python import settings
class WebkitDownloader( object ):
def process_request( self, request, spider ):
if spider.name in settings.WEBKIT_DOWNLOADER:
if( type(request) is not FormRequest ):
webview = webkit.WebView()
webview.connect( 'load-finished', lambda v,f: gtk.main_quit() )
webview.load_uri( request.url )
gtk.main()
js = jswebkit.JSContext( webview.get_main_frame().get_global_context() )
renderedBody = str( js.EvaluateScript( 'document.body.innerHTML' ) )
return HtmlResponse( request.url, body=renderedBody )
settings.py中的内容如下:
# -*- coding: utf-8 -*-
# Scrapy settings for lagou_python project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
#
BOT_NAME = 'lagou_python'
SPIDER_MODULES = ['lagou_python.spiders']
NEWSPIDER_MODULE = 'lagou_python.spiders'
WEBKIT_DOWNLOADER=['lagou']
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'lagou_python (+http://www.yourdomain.com)'
ITEM_PIPELINES = {
'lagou_python.pipelines.LagouPythonPipeline':300
}
COOKIES_ENABLED = False
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'TBBKAnalysis (+http://www.yourdomain.com)'
DOWNLOADER_MIDDLEWARES = {
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None,
'lagou_python.spiders.rotate_useragent.RotateUserAgentMiddleware' :400,
'lagou_python.spiders.middleware.WebkitDownloader':543
}
LOG_LEVEL = 'DEBUG'
已经把自定义的下载类添加进去了。
为了把爬取的职位信息存在本地为lagou_python.json的文件中,pipelines.py的源码内容如下所示:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import codecs
class LagouPythonPipeline(object):
def __init__(self):
self.file = codecs.open("lagou_python.json", encoding="utf-8", mode="wb")
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item
为了防止被ban,建立了一个自动切换User-Agent的文件rotate_useragent.py,源码如下所示:
from scrapy import log
import random
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
class RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.user_agent_list)
if ua:
log.msg('Current UserAgent: '+ua, level=log.INFO)
request.headers.setdefault('User-Agent', ua)
#the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape
#for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
最重要的部分,爬虫的编写,在网页中具体内容的定位我就不说明了。职位信息的后续网页是根据尾页的范围,利用xrange产生从第2页到尾页的数字,然后拼接上去的。源码如下:
__author__ = 'sniper.geek'
import re
import json
from scrapy.selector import Selector
from scrapy.spider import Spider
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor as sle
from lagou_python.items import LagouPythonItem
from scrapy import log
from scrapy.http import Request
class LagouSpider(CrawlSpider):
name = "lagou"
download_delay = 2
allowed_domains = ["lagou.com"]
start_urls = [
"http://www.lagou.com/jobs/list_Python?kd=Python&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=&lc=&workAddress=&city=%E4%B8%8A%E6%B5%B7&requestId=&pn=1"
]
#rules = [
# Rule(sle(allow=("l/jobs/list_Python?kd=Python&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=&lc=&workAddress=&city=%E4%B8%8A%E6%B5%B7&requestId=&pn=\d{1}")),follow=True,callback='parse_item')
# Rule(sle(),follow=True,callback='parse_item')
#
#]
def parse(self,response):
log.msg("Fetch page: %s"%response.url)
#items = []
sel = Selector(response)
sites = sel.xpath('//div[@class="content"]/ul[@class="hot_pos reset"]/li')
total_page_value = sel.xpath('//div[@class="Pagination myself"]/a[@href="#"][last()]/@title').extract()
log.msg("total_page_value: %s"%total_page_value)
total_page = int(total_page_value[0])
log.msg("page_number: %s"%total_page)
for site in sites:
item = LagouPythonItem()
item['salary'] =site.xpath('div[@class="hot_pos_l"]/span[1]/text()').extract()
item['experience'] =site.xpath('div[@class="hot_pos_l"]/span[2]/text()').extract()
item['education'] =site.xpath('div[@class="hot_pos_l"]/span[3]/text()').extract()
item['occupation_temptation'] =site.xpath('div[@class="hot_pos_l"]/span[4]/text()').extract()
if len(site.xpath('div[@class="hot_pos_r"]/span')) ==3:
item['job_fields'] = site.xpath('div[@class="hot_pos_r"]/span[1]/text()').extract()
item['stage'] = site.xpath('div[@class="hot_pos_r"]/span[2]/text()').extract()
item['scale'] = site.xpath('div[@class="hot_pos_r"]/span[3]/text()').extract()
item['company'] =site.xpath('div[@class="hot_pos_r"]/div[@class="mb10"]/a/text()').extract()
item['url'] = site.xpath('div[@class="hot_pos_r"]/div[@class="mb10"]/a/@href').extract()
item['founder']=[]
else:
item['job_fields'] = site.xpath('div[@class="hot_pos_r"]/span[1]/text()').extract()
item['founder'] = site.xpath('div[@class="hot_pos_r"]/span[2]/text()').extract()
item['stage'] = site.xpath('div[@class="hot_pos_r"]/span[3]/text()').extract()
item['scale'] = site.xpath('div[@class="hot_pos_r"]/span[4]/text()').extract()
item['company'] =site.xpath('div[@class="hot_pos_r"]/div[@class="mb10"]/a/text()').extract()
item['url'] = site.xpath('div[@class="hot_pos_r"]/div[@class="mb10"]/a/@href').extract()
yield item
next_urls=[]
for k in xrange(2,total_page+1):
base_url = "http://www.lagou.com/jobs/list_Python?kd=Python&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=&lc=&workAddress=&city=%E4%B8%8A%E6%B5%B7&requestId=&pn="+str(k)
next_urls.append(base_url)
for next_url in next_urls:
#log.msg("Next page:%s"%next_url, level=log.INFO)
yield Request(next_url,callback=self.parse)
尝试抓取,并且在本地生成为log的日志文件,命令如下:
scrapy crawl lagou --logfile=log
部分抓取结果:

整个project的源文件我放到百度云了,感兴趣的可以看看。scrapy还用的不熟练,发现自己python写的也一般,任重道远。加油。
链接:http://pan.baidu.com/s/1gdjbKUR 密码:hnrk

