这是个简单又复杂的爬虫。抓取逻辑很简单,但任务实现会略微繁琐。但只要思路清楚,还是很简单的。
对象-路易威登微博
网址:http://m.weibo.cn/u/1836003984
红色部分是微博账号的id
爬取思路
1、我们先写一个微博的所有评论,看网址规律是什么样子,有没有一些奇怪的参数,这些参数要到哪里获取?
2、依次类推,发现爬所有微博评论的微博评论的规律,看看有没有奇怪的参数,这些参数要到哪里才能获取?
说的优点云里雾里的,这里附上三个url模板。
https://m.weibo.cn/api/comments/show?id={id}&page={page}
https://m.weibo.cn/api/container/getIndex?containerid={oid}&type=uid&value={uid}&page={page}
https://m.weibo.cn/api/container/getIndex?type=uid&value={usr_id}
第一个url模板代表的是某条微博的id,打开这个url会返回该微博某页的评论。
第二个url模板代表的是微博用户所发微博的列表,打开该url,返回的是某页的微博列表。
第三个url模板代表的其实是微博用户主页。
访问第一个url需要id,但要访问了第二个url才能获得id
访问第二个url需要oid、uid,但是oid、uid需要访问了第三个url才能获得。
思路很简单,那我们就此展开。
一、微博评论
抓包是一种美德,翻看路易威登一个微博评论,打开开发者工具,进行抓包准备。
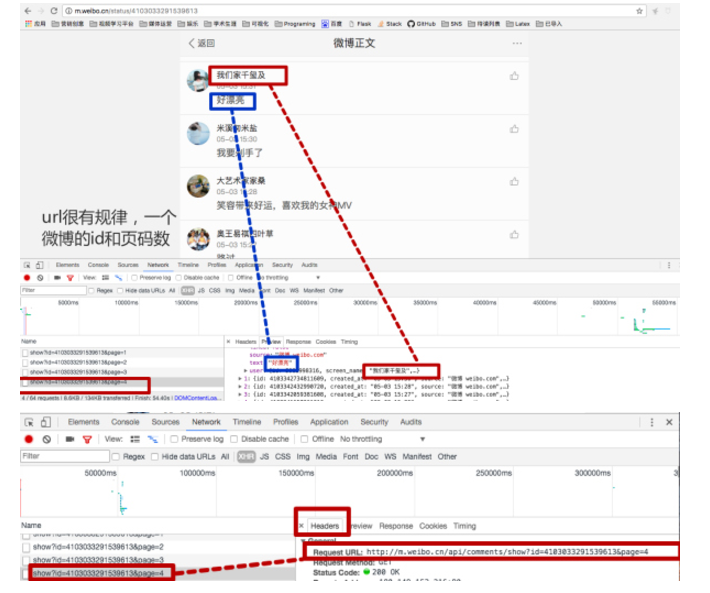
好了,抓包分析,找到我们屏幕中看到的数据了。那么方框中圈中的网址就是评论数据对应的网址。
http://m.weibo.cn/api/comments/show?id=4103033291539613&page=4
网址关键参数,微博id和页码

上面红框中圈中的是第四页评论的数据。
data:第四页的数据
最大的方框,是微博中某条评论的相关数据,如创建时间,评论的id,喜欢数(点赞数)、发布微博的网站(是手机端还是网页端)、评论文本、发评论的用户相关信息(用户id、昵称等)
max:最大页数
total_num:微博评论数
好了,直接附上爬取某微博评论这部分的爬虫脚本截图
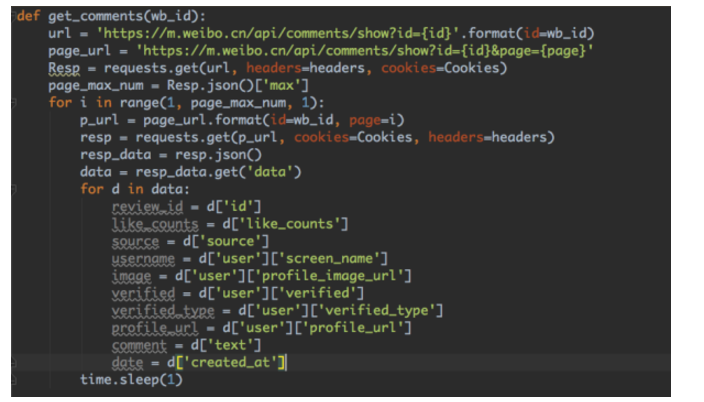
def get_comments(wb_id):
Data = []
url = 'https://m.weibo.cn/api/comments/show?id={id}'.format(id=wb_id)
page_url = 'https://m.weibo.cn/api/comments/show?id={id}&page={page}'
Resp = requests.get(url, headers=headers, cookies=Cookies)
page_max_num = Resp.json()['max']
for i in range(1, page_max_num, 1):
p_url = page_url.format(id=wb_id, page=i)
resp = requests.get(p_url, cookies=Cookies, headers=headers)
resp_data = resp.json()
data = resp_data.get('data')
for d in data:
review_id = d['id']
like_counts = d['like_counts']
source = d['source']
username = d['user']['screen_name']
image = d['user']['profile_image_url']
verified = d['user']['verified']
verified_type = d['user']['verified_type']
profile_url = d['user']['profile_url']
comment = d['text']
time.sleep(1)
我们想自动爬取路易威登发布的所有微博,必须批量获取微博id,才能高效爬取路易威登所有数据。
所以现在,问题来了,怎么批量获得微博id??
二、批量获取微博id
回到主页
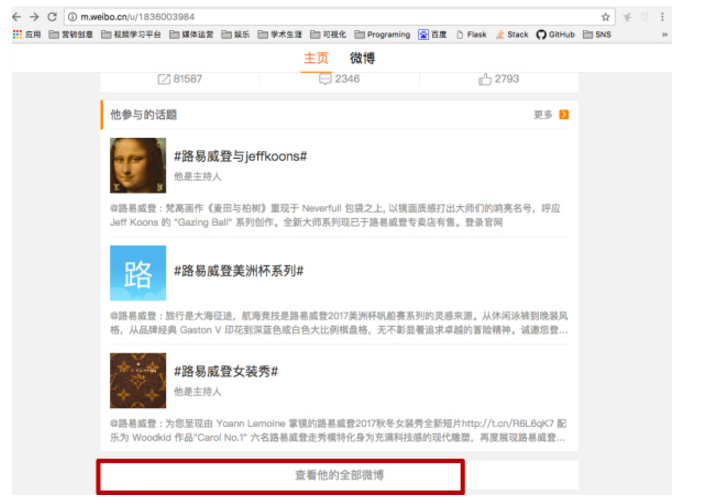
按F12,准备抓包,点击最下方的“查看他的全部微博”。我们不停的向下方滚动,相当于向网站请求了六次,抓包如图。这是我打开的第四页的所有微博对应的网址。
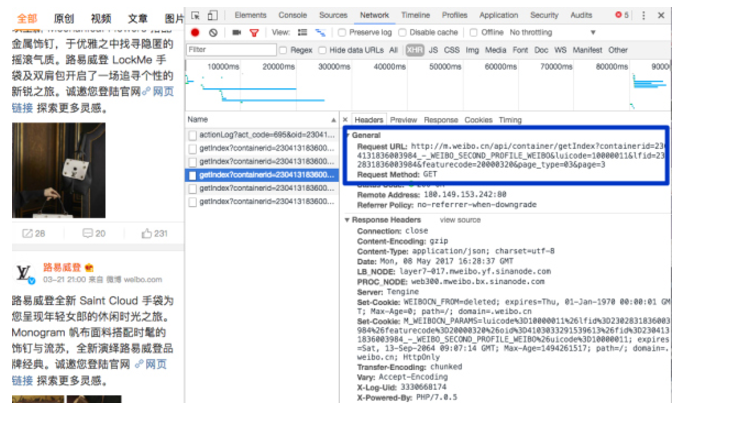
打开第四页的网址对应的数据
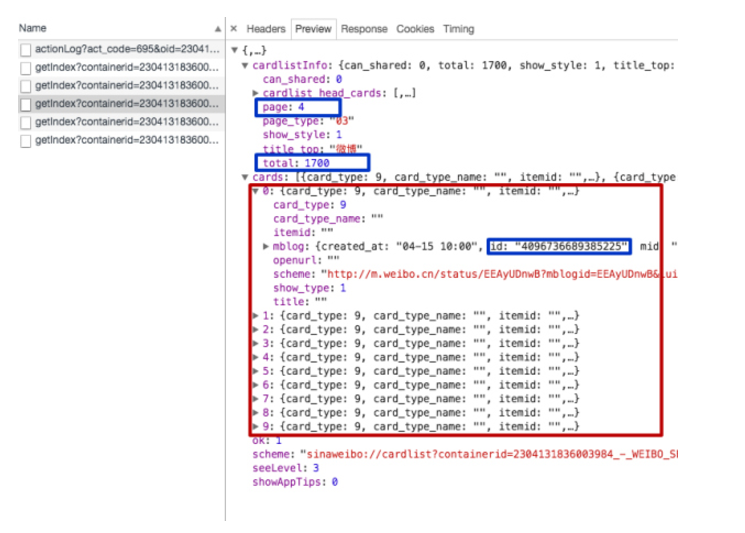
我们得到了上图,这都是我们想要的数据。
page:当前页码
total:微博列表的页面数
cards:当前微博列表对应的数据(含有多个微博数据)
红色方框中的蓝色方框:众多微博id的一个。
现在我们可以写一个关于获取微博id的爬虫,直接附上代码
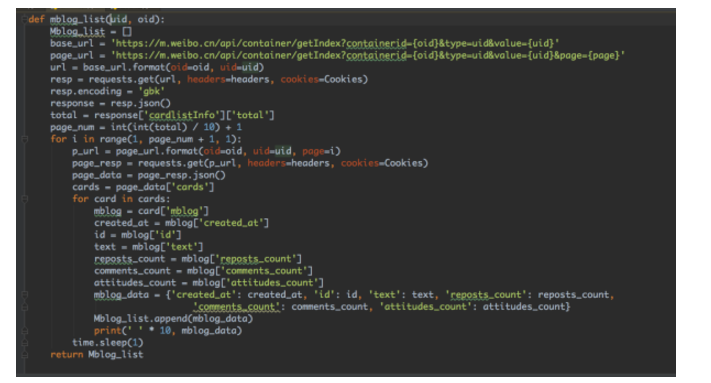
def mblog_list(uid, oid):
Mblog_list = []
base_url = 'https://m.weibo.cn/api/container/getIndex?containerid={oid}&type=uid&value={uid}'
page_url = 'https://m.weibo.cn/api/container/getIndex?containerid={oid}&type=uid&value={uid}&page={page}'
url = base_url.format(oid=oid, uid=uid)
resp = requests.get(url, headers=headers, cookies=Cookies)
resp.encoding = 'gbk'
response = resp.json()
total = response['cardlistInfo']['total']
page_num = int(int(total) / 10) + 1
for i in range(1, page_num + 1, 1):
p_url = page_url.format(oid=oid, uid=uid, page=i)
page_resp = requests.get(p_url, headers=headers, cookies=Cookies)
page_data = page_resp.json()
cards = page_data['cards']
for card in cards:
mblog = card['mblog']
created_at = mblog['created_at']
id = mblog['id']
text = mblog['text']
reposts_count = mblog['reposts_count']
comments_count = mblog['comments_count']
attitudes_count = mblog['attitudes_count']
mblog_data = {'created_at': created_at, 'id': id, 'text': text, 'reposts_count': reposts_count,
'comments_count': comments_count, 'attitudes_count': attitudes_count}
Mblog_list.append(mblog_data)
print(' ' * 10, mblog_data)
time.sleep(1)
return Mblog_list
现在问题来了,uid,oid怎么获取呢?
三、获取uid、oid
重新回到主页
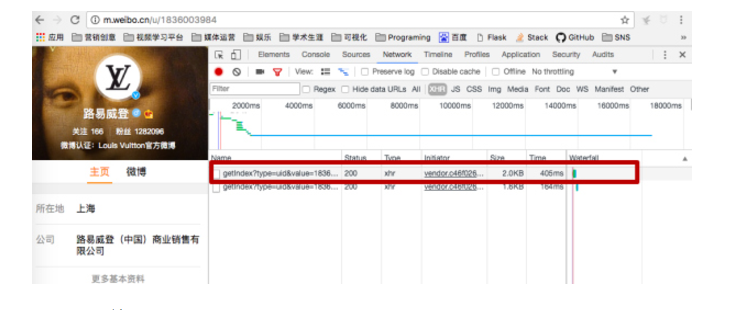
刷新,出现这个网址
http://m.weibo.cn/api/container/getIndex?type=uid&value=1836003984&containerid=1005051836003984
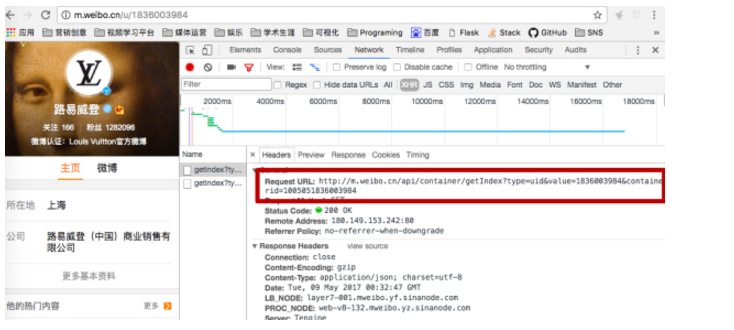
点击Preview,展开每个项目,查找uid、fid、oid
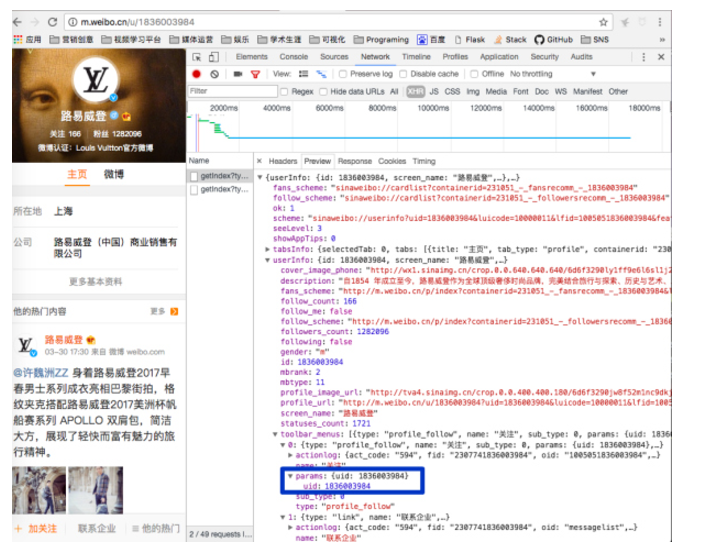
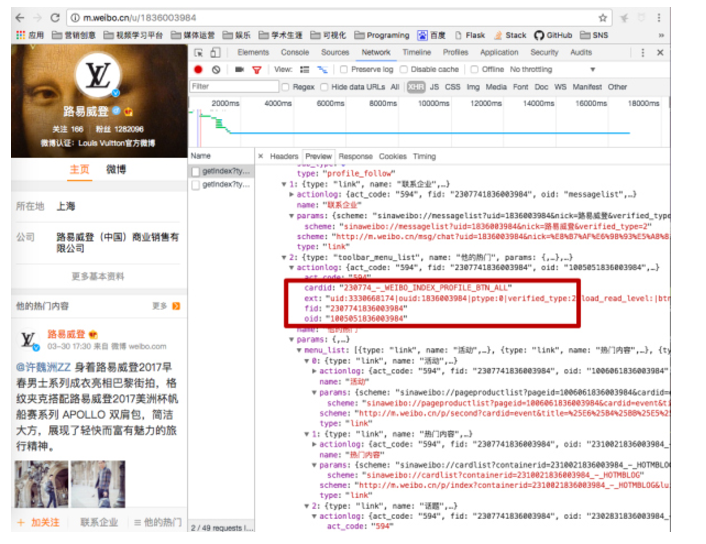
好了,现在uid、oid有了,我们专门写获取这两个参数的小脚本,代码直接上
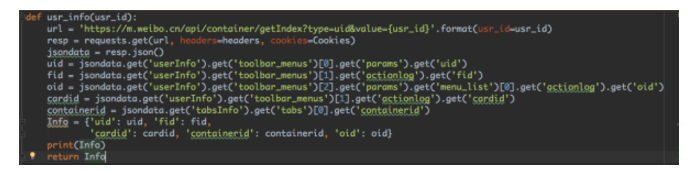
def usr_info(usr_id):
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value={usr_id}'.format(usr_id=usr_id)
resp = requests.get(url, headers=headers, cookies=Cookies)
jsondata = resp.json()
uid = jsondata.get('userInfo').get('toolbar_menus')[0].get('params').get('uid')
fid = jsondata.get('userInfo').get('toolbar_menus')[1].get('actionlog').get('fid')
oid = jsondata.get('userInfo').get('toolbar_menus')[2].get('params').get('menu_list')[0].get('actionlog').get('oid')
cardid = jsondata.get('userInfo').get('toolbar_menus')[1].get('actionlog').get('cardid')
containerid = jsondata.get('tabsInfo').get('tabs')[0].get('containerid')
Info = {'uid': uid, 'fid': fid,
'cardid': cardid, 'containerid': containerid, 'oid': oid}
print(Info)
return Info
获取完整代码,请关注
公众号:大邓带你玩Python
更多内容
文本分析
python居然有情感??真的吗??
文本分析之网络关系
中文分词-jieba库知识大全自然语言处理库之snowNLP用gensim库做文本相似性分析基于共现发现人物关系的python实现
用python计算两文档相似度
数据分析
酷炫的matplotlib
文本分析之网络关系
pandas库读取csv文件用词云图解读“于欢案”
神奇的python
初识Python的GUI编程Python实现文字转语音功能怜香惜玉,我用python帮助办公室文秘
逆天的量化交易分析库-tushare
开扒皮自己微信的秘密
8行代码实现微信聊天机器人
使用Python登录QQ邮箱发送QQ邮件
爬虫
爬虫实战视频专辑【视频】手把手教你抓美女~
当爬虫遭遇验证码,怎么办【视频】于欢案之网民的意见(1)?【视频】有了selenium,小白也可以自豪的说:“去TMD的抓包、cookie”
【视频】快来get新技能--抓包+cookie,爬微博不再是梦
【视频教程】用python批量抓取简书用户信息
爬豆瓣电影名的小案例(附视频操作)
爬豆瓣电影名的小案例2(附视频操作)用Python抓取百度地图里的店名,地址和联系方式

