
有段时间不来了,最近忙了不少事情,投了几家实体火锅店铺,感慨现在杭州的房价真的比股票、黄金还快,动不动都是遍地3W一平的,实在无心写coding了。
BTS(bucket test system)分桶测试在我们日常的搜索优化上应用的比较多,所以就花点时间来整理下吧,希望对一些人能有用。像我们在做算法上线过程中,哪些策略好,哪些算法效果好,哪些query好,都需要通过不同的分桶测试来解释真相。毕竟你在线下跑再多的历史数据回测,都不如线上来的实际。
BTS概念
分桶测试是指,根据分桶逻辑对用户进行的功能测试。所述分桶逻辑是一种访问量分配的方法,分桶就是划分访问量、即按某种方式来分配访问量。其中,A/B测试(A/B Testing)是分桶测试的最简单形式,即设定一个或多个基准桶,基准桶用于测试现有的功能,其作为比较改进后的功能的测试效果的基准,再设定一个或多个测试桶,测试桶用于测试改进后的功能,通过考察基准桶与测试桶之间在测试获得的各项指标上的差异,最终确定测试桶的效果,如是否优于基准桶等等。其中,每一个桶(基准桶、测试桶)具有一个分组号(bucket id)。
线上测试
为了真实验证一个算法模型的好坏,需要有一个系统能提供真实的流量来检验。像淘宝搜索实现的BTS系统就是这样的一个环境,在用户搜索时,由搜索系统根据一定的策略来自动决定用户的分组号(Bucket id),保证自动抽取导入不同分组的流量具有可对比性,然后让不同分组的用户看到的不同算法模型提供的结果。用户在不同模型下的行为将被记录下来,这些行为数据通过数据分析形成一系列指标,而通过这些指标的比较,最后就形成了不同模型之间孰优孰劣的结论。只要分组的流量达到一定的程度,数据指标从统计意义上就具有可比性。
不同的BTS系统会关注不同的数据指标,在淘宝搜索,有一些重要的指标是很多算法模型测试的时候关注的:
访问UV成交转化率:来淘宝搜索的UV,最终通过搜索结果成交的用户占比
IPV-UV转化率:来淘宝搜索的UV,有多少比例的用户点击了搜索结果
CTR:搜索产生的点击占搜索产生的PV的比例
客单价:每个成交用户在淘宝搜索上产生成交的平均价格
基尼系数:基尼系数是一个经济学名词,考量社会财富的集中度;如果社会财富集中到很少一部分富人手中的时候,基尼系数就会增大,社会的稳定性和可持续发展性就会出现问题;淘宝搜索借用了这个概念来衡量搜索带给卖家的PV展示,和点击的集中度,在保证用户体验的前提下,给更多的优质或小小而美的卖家展示的机会。
大部分时候我们都有好几个模型和功能在线上测试,我们用BTS的方式来观察测试的情况,如果提升稳定就逐渐开放给所有用户,如果没有提升,我们也能从中获得经验帮助我们更好的理解用户。
BTS方式
通常有两种常用的分桶方式:
1.基于用户的分桶(User-based bucket):这样的桶是一个随机选定用户的集合。一种简单的方式是,使用一个hash函数,为每个user id生成一个hash值,选择一个特定的范围指向一个桶。例如:Ron Rivest设计的md5。
2.基于请求的分桶(Request-based bucket):这样的桶,是一个随机选择的请求的集合。常用的做法是,为每个请求生成一个随机数,然后将对应指定范围的请求随机数指定到某个桶内。注意,在这样的桶中,在实验期间,同一个用户不同的访问,有可能属于不同的分桶。
BTS经验介绍
基于用户的分桶,通常比基于请求的分桶更简洁、更独立。例如,当使用基于请求的分桶时,一个用户使用模型A的响应(Response),可能会影响到模型B。但是,在基于用户的分桶中,这个现象不会发生。另外,任何长期用户行为都可以在基于用户的分桶中进行。然而,如果在基于用户的分桶中使用一个简单模型,该分桶的用户可能会收到不好的结果,这样也会导致较差的用户体验。而基于请求的分桶则对这种模型相对不敏感些,因为一个用户的所有请求不一样分配到相同的bucket中。总之,基于用户的分桶更受欢迎些。
在受控的实验中,分桶的所有设置应该一致,除了为每个分桶分配的模型不同;模型A用于服务分桶1;模型B用于服务分桶2。特别的,对于两个分桶来说,我们要使用相同的选择方式准则。例如,某一个分桶只包含登陆用户,那么另一个分桶也必须一致。
当使用基于用户的分桶时,对于不同的测试,最好使用独立的各不相同的hash函数,以保持正交性。例如,假设我们在一个web页面具有两个推荐模块,每个模块对应两个要测试的模型。两个对应的测试模块:test1和test2。对于每个test i,都有两个对应的推荐模型:Ai和Bi。如果我们在两组test上使用相同的hash函数为用户分配hash值,hash值低于某个阀值的使用模型Ai,剩下的使用模型Bi,这样,模型A1的用户与模型A2的用户相同;模型B1的用户与模型B2的用户相同。由于涉及到与A2和B2的交互,这会导致模型A1与模型B1之间的比较不够合理。解决这种问题的一个方法是,确保分配给A1模型的用户概率与test2中的A2或B2模型相互独立。这很容易实现,如果我们在test1中使用的将user id映射后的hash值与test2中相互统计独立即可。使用独立的hash函数,可以帮助我们控制当前测试与之前测试的独立性。
现在我们做的还比较简单,可以参考下
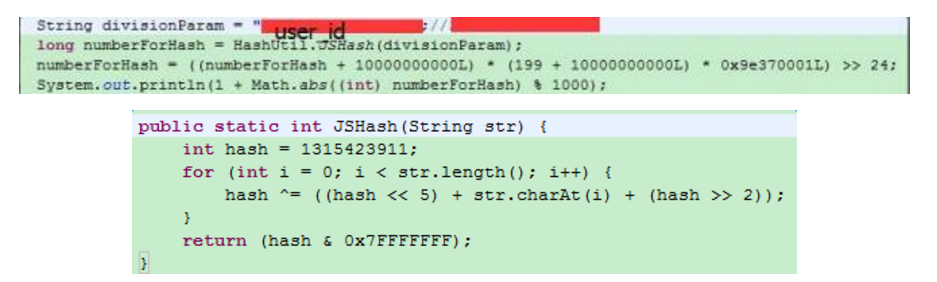
映射user_id到不同的分桶bucketid中,就可以开始了。
