1.背景介绍
Caffe 是一个高效的神经网络计算框架,可以充分利用系统的GPU资源进行并行计算,是一个强大的工具,在图像识别、语音识别、行为分类等不同领域都得到了广泛应用。有关Caffe的更多内容请参考项目主页:
http://caffe.berkeleyvision.org/
不过Caffe的常用部署方式是单机的,这就意味着它的水平扩展能力受到了限制。使用者可以通过在系统中添加多个GPU的方式提高并发度,不过其并发能力最终受到单系统可支撑的GPU数量的限制。同时,神经网络计算往往又是计算消耗很大的,所以人们在使用Caffe的时候都可能会希望有一种并行计算框架可以支持Caffe。
而我们知道Spark是基于内存的计算框架,基于Yarn, Mesos或者是Standalone模式,它可以充分利用多实例计算资源。因此,如果能够结合Caffe和Spark,Caffe的能力将得到更充分的发挥。 基于这些原因,Yahoo开源的CaffeOnSpark框架受到的极大的关注。
有关CaffeOnSpark的源代码和相关文档,请大家参考:
https://github.com/yahoo/CaffeOnSpark
从名字上看,CaffeOnSpark 结合了两种现有的科技:深度学习框架 Caffe 和大规模数据处理系统 Spark。Yahoo 所做的就是想办法在 Spark 层次上运行 Caffe。找到方法后,Caffe 不仅可以在 Spark 上运行,还可以两者一起在 Hadoop 上运行。Yahoo 的开发不仅会让人工智能开发者用更简单熟悉的工具、省去传送数据的麻烦过程,还能让深度学习更方便地同时处理数个服务器的内容。Andy Feng 还特意告诉我们,这一点 Google 的 TensorFlow 目前还做不到,Yahoo 领先了一步。
—————————————————禁止转载——————————————————
2.CaffeOnSpark介绍
CaffeOnSpark研发的背景,是雅虎内部具有大规模支持YARN的Hadoop和Spark集群用于大数据存储和处理,包括特征工程与传统机器学习(如雅虎自己开发的词嵌入、逻辑回归等算法),同时雅虎的很多团队也在使用Caffe支持大规模深度学习工作。目前的深度学习框架基本都只专注于深度学习,但深度学习需要大量的数据,所以雅虎希望深度学习框架能够和大数据平台结合在一起,以减少大数据/深度学习平台的系统和流程的复杂性,也减少多个集群之间不必要的数据传输带来的性能瓶颈和低效(如图1)。
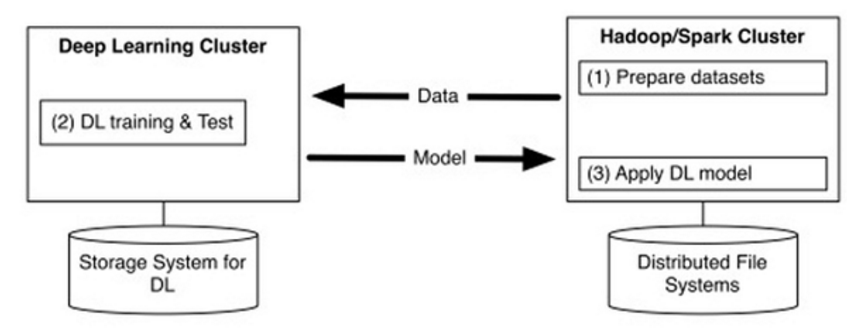
图1 深度学习集群与大数据集群分离的低效
CaffeOnSpark就是雅虎的尝试。对雅虎而言,Caffe与Spark的集成,让各种机器学习管道集中在同一个集群中,深度学习训练和测试能被嵌入到Spark应用程序,还可以通过YARN来优化深度学习资源的调度。
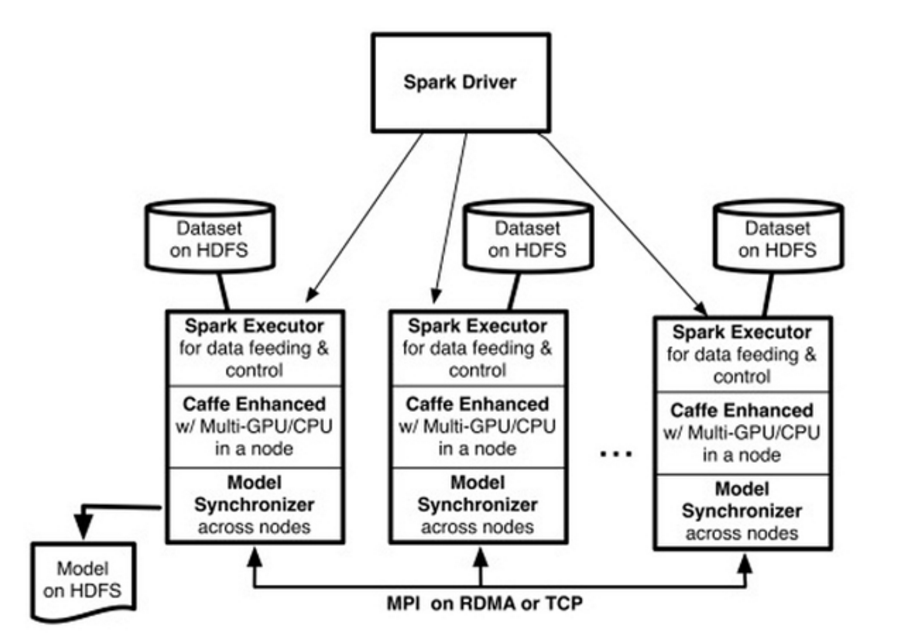
图2 CaffeOnSpark系统架构
CaffeOnSpark架构如图2所示,Spark on YARN加载了一些执行器(用户可以指定Spark执行器的个数(–num-executors <# of EXECUTORS>),以及为每个执行器分配的GPU的个数(-devices <# of GPUs PER EXECUTOR>))。每个执行器分配到一个基于HDFS的训练数据分区,然后开启多个基于Caffe的训练线程。每个训练线程由一个特定的GPU处理。使用反向传播算法处理完一批训练样本后,这些训练线程之间交换模型参数的梯度值,在多台服务器的GPU之间以MPI Allreduce形式进行交换,支持TCP/以太网或者RDMA/Infiniband。相比Caffe,经过增强的CaffeOnSpark可以支持在一台服务器上使用多个GPU,深度学习模型同步受益于RDMA。
考虑到大数据深度学习往往需要漫长的训练时间,CaffeOnSpark还支持定期快照训练状态,以便训练任务在系统出现故障后能够恢复到之前的状态,不必从头开始重新训练。从第一次发布系统架构到宣布开源,时间间隔大约为半年,主要就是为了解决一些企业级的需求。
—————————————————禁止转载——————————————————
3.挑战
性能
CaffeOnSpark是按照专业深度学习集群的性能标准而设计。
典型的Spark应用分配多个执行器(Executor)来完成独立的学习任务,并且用Spark驱动器(Driver)同步模型更新。二级缓存之间是相互独立的,没有通信。这样的结构需要模型数据在执行器的GPU和CPU之间来回传输,驱动器成了通讯的瓶颈。
为了实现性能标准,CaffeOnSpark在Spark执行器之间使用了peer-to-peer的通讯模式。最开始我们尝试了开源的OpenMPI,但OpenMPI的应用需要提前选好一些机器构建MPI集群,而CaffeOnSpark其实并不知道会用到哪些机器,所以我们研发了自己的MPI。
如果有无限的带宽连接,这些执行器就能够直接读取远端执行器的GPU内存。我们的MPI实现将计算和通讯的消耗分布到各个执行器上,因此消除了潜在的瓶颈。
大数据
Caffe最初的设计只考虑了单台服务器,也就是说输入数据只在本地文件系统上。对于CaffeOnSpark,我们的目的是处理存储在分布式集群上的大规模数据,并且支持用户使用已经存在的数据集(比如LMDB数据集)。CaffeOnSpark引入了Data Source的概念,提供了LMDB的植入实现、数据框架、LMDB和序列文件。CaffeOnSpark不仅提供了深度学习的高级API,也提供了非深度学习和普通数据分析/处理的接口。
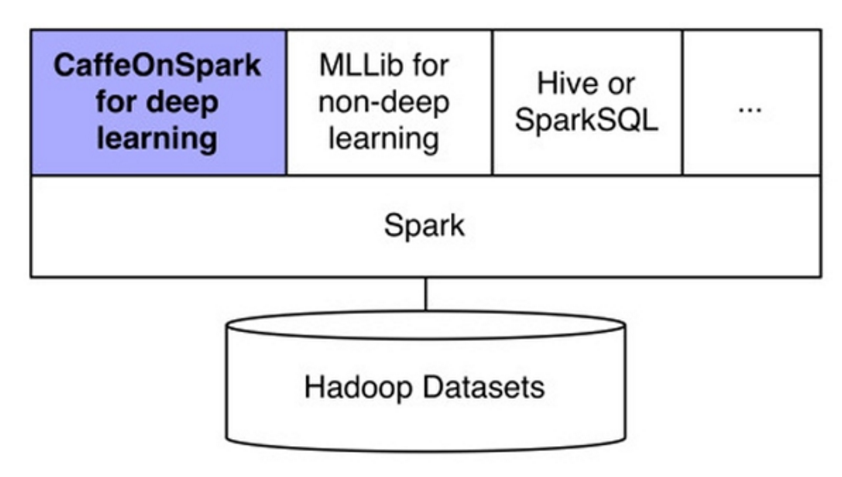
图3 雅虎希望CaffeOnSpark成为Spark上的深度学习包
另外应用场景上Caffe在深度学习的应用远不止图像。举个例子,Caffe可以为搜索引擎训练Page Ranking模型。在那种场景下,训练数据由用户的搜索会话组成,包括搜索词、网页的URL和内容。
编程语言
尽管Caffe是用C++实现的,但作为Spark的产品,CaffeOnSpark也支持Scala、Python和Java的可编程接口。内存管理对在JVM上长期运行的Caffe任务是一个挑战,因为Java的GC机制并没有考虑JNI层的内存分配问题。我们在内存管理上做了重大改变,通过一个自定义JNI实现。
—————————————————禁止转载——————————————————
4.应用
使用CaffeOnSpark和MLlib的Scala应用如下:
1: def main(args: Array[String]): Unit = {
2: val ctx = new SparkContext(new SparkConf())
3: val cos = new CaffeOnSpark(ctx)
4: val conf = new Config(ctx, args).init()
5: val dl_train_source = DataSource.getSource(conf, true)
6: cos.train(dl_train_source)
7: val lr_raw_source = DataSource.getSource(conf, false)
8: val extracted_df = cos.features(lr_raw_source)
9: val lr_input_df = extracted_df.withColumn(“Label”, cos.floatarray2doubleUDF(extracted_df(conf.label)))
10: .withColumn(“Feature”, cos.floatarray2doublevectorUDF(extracted_df(conf.features(0))))
11: val lr = new LogisticRegression().setLabelCol(“Label”).setFeaturesCol(“Feature”)
12: val lr_model = lr.fit(lr_input_df)
13: lr_model.write.overwrite().save(conf.outputPath)
14: }
这段代码演示了CaffeOnSpark和MLlib如何协同:
- L1-L4:初始化Spark上下文,并使用它来创建CaffeOnSpark和配置对象。
- L5-L6:使用CaffeOnSpark与HDFS上的一个训练数据集进行DNN训练。
- L7-L8:学习到的DL模型应用于从HDFS上的数据集提取特征。
- L9-L12:MLlib使用提取的特征进行非深度学习(用更具体的LR分类)。
- L13:可以保存分类模型到HDFS。
