先和大家一起回忆下17、18年的数据相关市场情况,然后一起聊下19年转行的我们应该要注意哪些内容。
一起回忆17年
记得17年时,听到最多的是AlphaGo大战李世石,当时即将毕业的自己也没有感觉到有什么大不了的。但是这个事情在风投和创业者眼里,就如一个深山老林的单身汉子看到一个水汪汪的小姑娘一般,谁都不想错过这样的偶遇。创业者开始各种准备PPT,风投也是开始各种寻找人工智能项目,就是在这样的情况之下,给那年转行的我们提供很多就业机会,基本上是会Python基础语法、SQL查询、logsitic算法,能够调包,就能找到工作,完成这些技能大概需要2、3个月即可,况且更多的同学是直接把别人的代码抄了一遍就去面试了。当时大家拿到的工资基本上比各种高费培训出来的java工程师还要高一些。就是在这样的大环境下,各种高校同学和其他工作的同学也开始纷纷投身于数据分析和数据挖掘上面来了(数据分析和数据挖掘的职责有时候是没有分那么清楚的)
聊聊18年的情况
自己当时是17年12月份转行,开始做机器学习平台的算法研究,在工作中就开始各种努力学习,准备把一些数学基础和各种算法的原理给好好熟悉下,不尽人意的是公司算法平台一直推不出去。当时陪领导一起去做售前,在反复的沟通中也是逐渐感受到明摆着人家甲方都没有想明白算法是怎么回事,当时看算法落地的需求并没有那么多。就是这样一阵热潮过后,基本功不扎实的公司和不扎实的自己就开始面临淘汰了。
其实18年的时候也出现了意外的惊喜,各种算法都是用来预测未来的情形,但是较难给业务上带来增长,这时大家开始纷纷重新关注历史数据的利用了,可视化报表又开始展露头角了,又开始成为大家找工作的方向,像星巴克、德克士这样的连锁零售都上了项目计划表,但是有一点的不友好的是传统行业能够做整个BI项目大都是用的固有的工具,比如微软系的SSRS、SSAS、SSIS,并且还老喜欢外包,所以相应的工资不是太高。所以我们转行还是先不要选这方面的行业,因为那些软件大都是付费的,哪天想到个互联网公司也不好进。那应该如何来做呢,接着往下看19年的注意事项把。
19年的注意事项
互联网中有一个现象,是一直会强调下业务线的快速迭代,可能就是好几条业务线在同时做,然后每条业务线上的数据不会像传统行业一样积累了好几年的数据,所以有的公司也不会针对每条业务线去做专门的数据仓库,可能所有的业务数据都会集中到一起。这样就出来了一个有意思的事情,所有的业务数据放到一起,那我们怎么来分析呢。这就要求我们的数据工程能力,比如做定时抽取数据到自己业务线的服务上,跨库跨表处理数据,制作可视化报表内部邮件发送、根据算法做商圈的聚集。这里先简单说下需求技能的变化
1.python代码的熟练仅仅面向过程的代码已经吃不消了,函数、对象之类的也要学起来了
2.使用python或者sql 做etl 的能力要上升
3.对于算法要能够用起来,现在公司也都在想办法通过算法做出有实际意义的事情
现在暂时聊到这里把,19年5月19日数据蛙深圳线下交流会上和大家沟通之后会再做修正,到时再提出真正切实的学习计划出来。
--------2019年6月10日,更新下19年转行数据分析必备技能-------------
说必备技能之前先来说下,说下数据工作者的工作流程。
为了方便叙说的明白,我们先把数据的使用,按照时间节点分为两个部分:研究历史数据、预测未来数据
研究历史数据:正规的数据流程是:
1.数据进入生产数据库,比如说商场中的交易订单流水表
2.试想一下,像星巴克在中国有3000多家门店,每天都会产生上百万的交易订单流水表,如果我们想要计算下近三年销售额,怎么来呢
3首先我们不能够直接在生产数据库上做计算,比如白天产生的订单数据一直在向数据库中做插入,然后我们还在里面做计算,这不就是想累死数据库了吗?
4.正确的做法是,凌晨两三点不产生交易的时候,我们把数据抽取到一个专门做计算的数据库中(hive 数据库、sqlserver数据库或者其他),然后做像求一年中每个月的销售,客单价之类的计算(多用sql 来计算,并且定时计算的,总不能半夜起来干活哈)
5.开始对计算好的数据进行可视化展示,这时候,我们会用到powerbi或者tableau等可视化工具。
6.想到powerbi或者tableau 只是展示少量的关键性指标,所以,针对不同的诉求,就需要自主分析了,二次处理原来计算好的数据、做可视化展示、做PPT汇报之类的,这一块其实才是我们常说的数据分析的内容了
这里面按照不同的工作范围,我们能够接触到的职位有ETL工程师(对应第4个)、BI工程师(对应第5个)、数据分析师(对应第6个)
预测未来数据:上个流程我们一起看了历史数据使用的流程,接着谈谈预测未来数据的流程。
1.这个照样也需要使用上面第四步计算好的数据,或者第四步的时候抽取对预测相关的数据。
2.然后使用上面的数据做机器学习,比如说用一个时间模型预测来年的销售额之类的
如果上面的职位都归属在数据组的话,想想看看也是个不小的团队了,并且除了大公司外很难有公司有完整的数据团队。所以现在,我们转行的同学来说,一开始工作可能会对研究历史数据流程中的4、5、6都会接触的,以及预测未来数据中的1、2
必须掌握内容:
1.sql 必须熟练,经典45道题目,不假思索的能够写出答案。一开始大家学习的时候,多半会看答案的,所以做一遍根本没有用的。需要达到效果是看到问题,直接反应出考察的知识点和结果
2.python 代码熟练
3.对于统计学和算法,我建议是直接来学习算法内容。对常用的算法要熟悉,有的公司给用不到算法,但是面试的时候一大半的公司要求会用算法
4.可视化能力,就是能够以图形作为显示
--------------------------------------更新于2019年6月18日----------------------
针对市场需求,开发了新的案例
由于针对市场上新的需求,我们在以往的课程中增加了3个和工作最为相关的案例
ETL和BI案例、python定制化邮件发送案例、数据挖掘流失预测案例
其中ETL和BI案例特点
1.是在linux 服务器上进行
2.使用的数据库是hive 数据库来进行,并且能够了解hadoop生态圈
3.使用sqoop进行数据的导入和导出,完善数据仓库
4.在linux 中使用crontab 做定时任务
5.POWREBI 部署线上展示
其中python定制化邮件发送案例
1.python 和hive数据库交互
2.python 处理数据
3.处理好的数据绘制成图形传递到html中
4.在linux服务器上实现定时任务
数据挖掘流失预测案例
1.包含描述统计、特征工程、选择模型、模型评估、参数选择等完成的机器学习步骤
2.实现了模型真正能的上线
强化班课程如下:
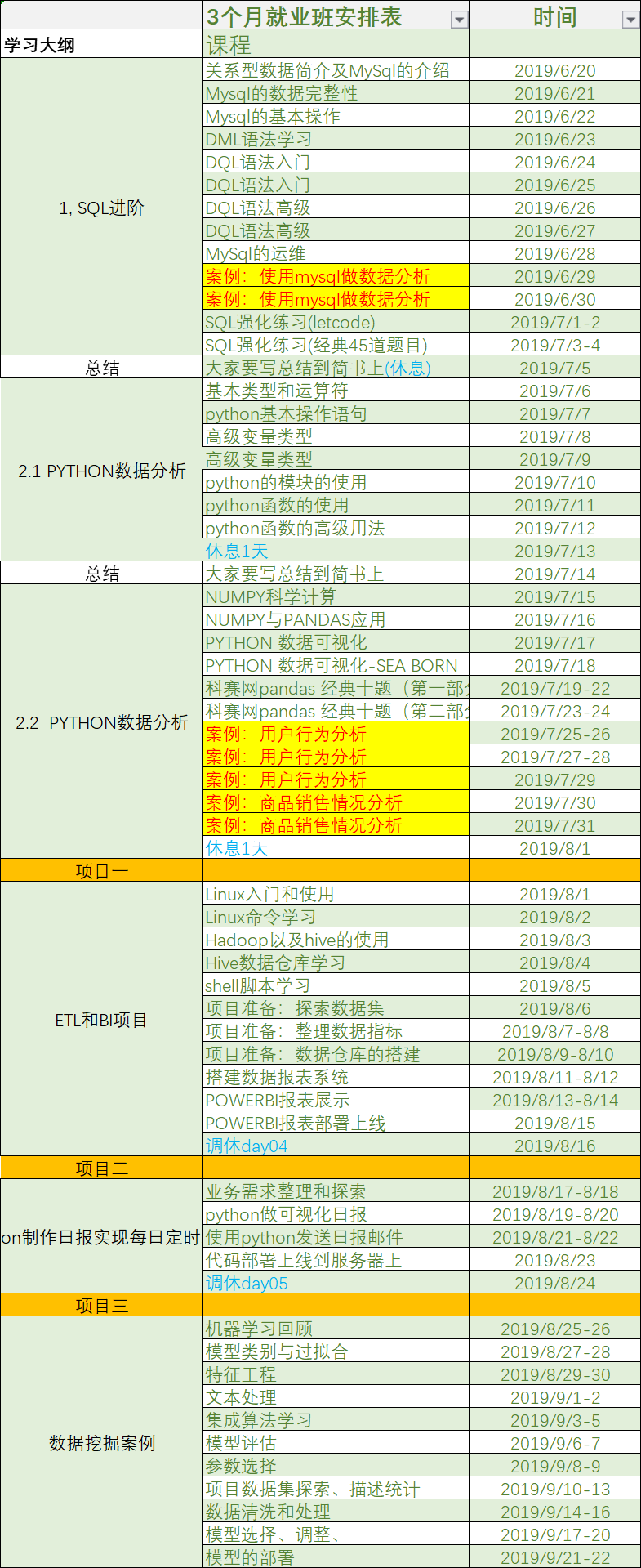
另外对于没有基础的同学,建议先从mysql开始来学习
基础班课程如下:
 image.png
image.png
另外不管是自己学习还是报课程来学习,都可以来社群探讨下现在数据工作者最需要的技能都是什么,以便让自己少走些弯路。
