
本文是《数据蛙三个月强化课》的第一篇总结教程,如果想要了解数据蛙社群,可以阅读给DataFrog社群同学的学习建议。温馨提示:如果您已经熟悉pandas,大可不必再看这篇文章,或是之挑选部分文章
数据分析的过程分组统计是一个最常见的场景了,下面我们一起来看下啊。
一:创建数据集
index = pd.Index(data=["Tom", "Bob", "Mary", "James", "Andy", "Alice"], name="name")
data = {
"age": [18, 30, 35, 18, 22, 30],
"city": ["Bei Jing ", "Shang Hai ", "Guang Zhou", "Shen Zhen", "Zhe Jiang", "Su Zhou"],
"sex": ["male", "male", "female", "male", "male", "female"],
"income": [3000, 8000, 8000, 4000, 6000, 7000]
}
user_info = pd.DataFrame(data=data, index=index)
user_info
我们来看下数据
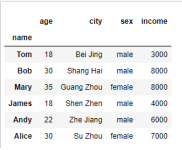 data
data
其中我们把 name作为了索引
二:进行分组
我们统计之前,先进行分组,比如对性别 sex 进行分组
 sex
sex
那如果我们对性别 sex 和年龄age 一起分组呢
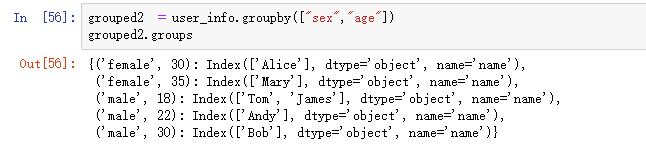 sex&age
sex&age
注意1:我们直接分组后得到的一个对象,来一起看下
 sex
sex
注意2:我们可以通过切片来获得分组后的某一列,但是此时也是返回的是一个对象
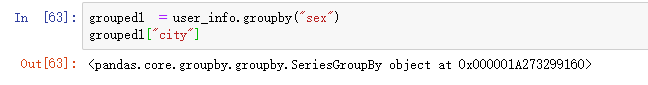 city
city
等下我们来看看具体怎么使用这个切片的
三:遍历分组
下面我们一起看下遍历分组,得到每组的一个情况
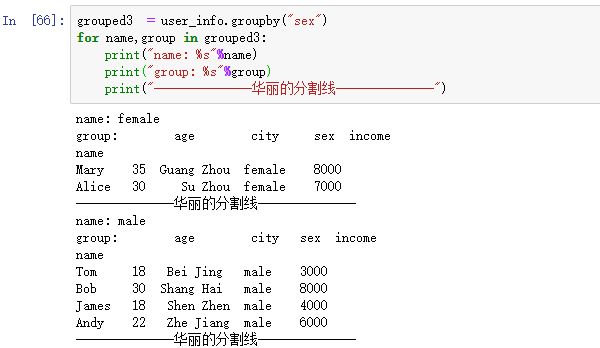
如果是根据多个字段来分组的,每个组的名称是一个元组。
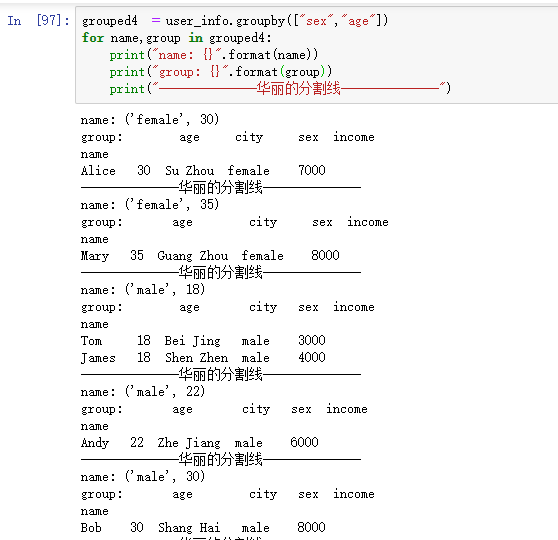
那如果我们只选择一个组应该怎么来做呢?
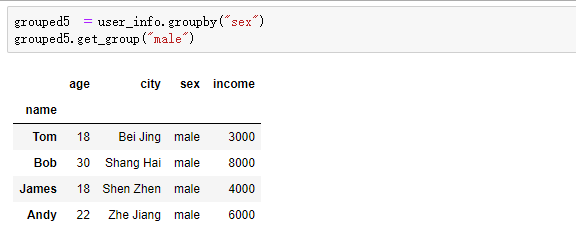
四:聚合操作
我们刚刚看完了分组了,现在来看看统计部分,如求 sum、max、avg等。这时,也需要显身手的agg 来现身了
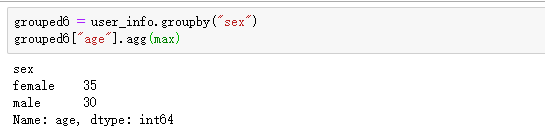
现在是不是想到我们在第二部分中的切片操作了。
另外,那如果根据多个键进行聚合呢,默认情况下会得到一个多层索引的结构
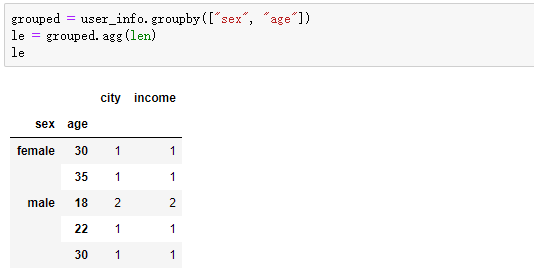
那如果我们不想要这样的索引结构,只需这样改变就好了
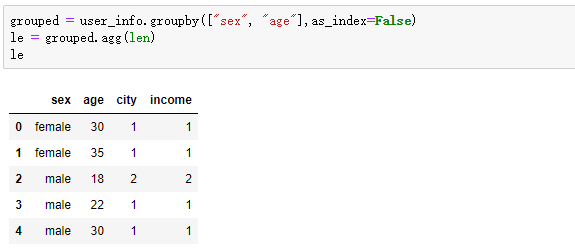
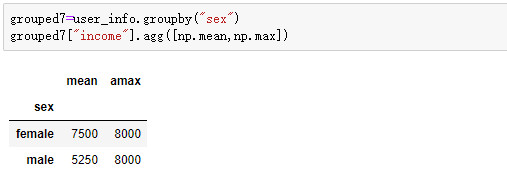
五:对DataFrame 一列应用不同的聚合操作
有时候对于一列,我们可能会有多个聚合操作
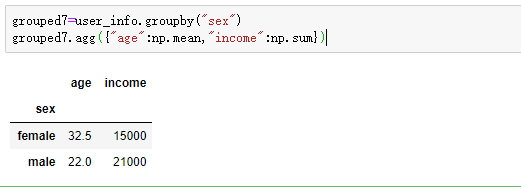
六:对DataFrame不同列应用不同的聚合操作
这里我们按照sex,但是对age,salary聚合的规则应该是不同的
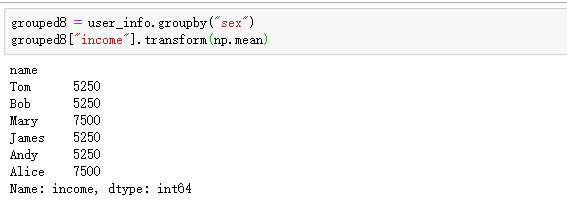
七:transform操作
transfrom 方法,会把函数的参数应用到所有的分组中,然后把结果放置到原数组的索引上来
八:apply 操作
apply 会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试用 pd.concat() 把结果组合起来

我们做数据分析的同学,肯定是少不了分组聚合这个操作的,大家要多多练习啊
