数据库简单来讲就是一堆互相关联的数据,最基础的数据组成了表(table),也是我们经常看到的一张Excel的sheet。
Mysql的安装
首先去MySQL的官网下载,版本5.6以上即可,安装的过程不打算进行细说,谷歌有很多的教程。这里给大家分享下我踩过的坑。
刚开始大家把下载好的程序,直接一路选择默认。但是填写Root用户密码时,一定要牢记密码
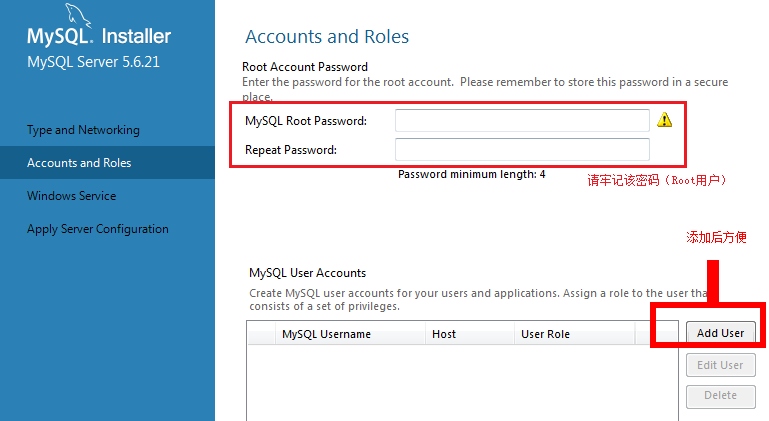
剩下的照样可以一路选择默认。
数据的导入
接下来所使用的数据是来秦路老师所提供,点击文末福利即可获得。
在数据的导入过程有几点需要留意下
尽量使系统的编码格式和文件的编码格式是相同的,比如说文件是utf-8格式,系统也要选择utf-8格式,否则数据中的中文将是乱码。
设置各字段的数据类型时,系统会帮我们自动选上,改不改都是可以的。int代表整数数值,varchar代表字符串(中文英文标点符号这类),括号里面的数字是允许存储字节,一般不需修改,但是对于某些数据字节较大的,相应的也要增大括号中的数字。
正式开始
对于数据的处理,从数据的筛选、数据分组聚合、时间类数据的处理,数据的清洗
SELECT * FROM data.analyst;

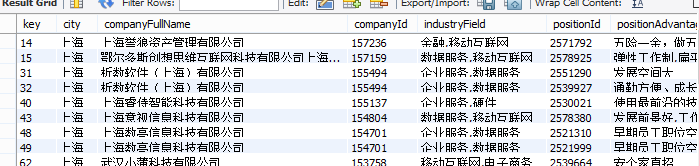
其实这是一份各个城市的数据分析相关职位数据
- 查询所有上海城市的职位数据
select * from data.analyst where city="上海";
- 查询城市为上海,职位为数据分析师的数据
select * from data.analyst where city="上海" and positionName="数据分析师"; #使用and进行多条件查询¨G2G¨K10K¨G3G¨K11K

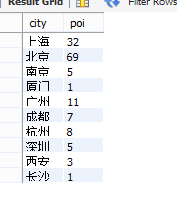
3.查看每个城市拥有的职位数
select city,count(distinct(positionId)) as pos from data.analyst group by city;
4.多维的形式的数据聚合
select city,workYear,count(distinct(positionId)) as poi from data.analyst group by city,workYear;
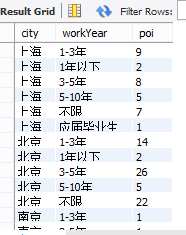
group by后添加多个字段,并通过聚合函数就会形成多维形式的数据聚合
其中聚合函数count,max,min,sum,avg等函数
5.if函数和group by 的结合使用
如果要是计算数据的占比,使用if函数比较方便;筛选出电子商务领域的分析师数据
select if (positionName like "%d电子商务%",1,0) from data.analyst;
筛选出不同城市的职位数量和不同城市的电子商务行业的职位数量
select city,count(distinct(positionAdvantage)),(if (positionName like "%d电子商务%",positionId,0))from data.analyst group by city

这里再添加一个条件,数据分析师岗位数量在500以上的城市有哪些
select city,count(distinct(positionId)),(if (positionName like "%d电子商务%",positionId,0))
from data.analyst group by city having count(distinct(positionId))>20
使用having语句,是对聚合后的数据结果进行过滤。
用order by语句,使结果能够呈现一定的顺序
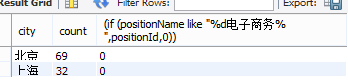
select city,count(distinct(positionId)) as count,(if (positionName like "%d电子商务%",positionId,0))
from data.analyst group by city having count(distinct(positionId))>20 order by count desc;

1.now()返回当前的日期和时间
select now()

2.date() 返回日期
select date(now());

3 .week函数获得当前第几周
select week(now());

其实表示时间的函数还有month,quarter,year,day,hour,minute大都是类似的。
将会使用到的函数有left,right,mid,locate(),substr(字符串,从哪里开始截,截取的长度),这些函数大都与Excel中的函数相似就不再多说了,下面说下清洗的思路以及代码
因为此表中的薪资大多为7k-9k之类的,如果这样我们没有对工资进行比较,所以我们把这类的薪资换算成平均薪资。
1.先获取工资的下线
select salary ,left(salary,locate('k',salary)-1) as bottomsalary from data.analyst;
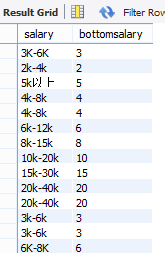
2.获取工资的上线
select salary ,substr(salary,locate('-',salary)+1,length(salary)-locate('-',salary)-1) as topsalary from data.analyst where salary not like "%以上%";

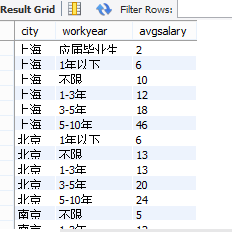
3.计算不同城市不同工作年限的平均薪资
select city,workyear,round(avg((topsalary+bottomsalary)/2))as avgsalary from (select substr(salary,locate('-',salary)+1,length(salary)-locate('-',salary)-1) as topsalary ,left(salary,locate('k',salary)-1) as bottomsalary,workyear ,city from data.analyst where salary not like "%以上%" )as t1 group by city,workyear order by city, avgsalary;
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的,在表中,每个主键的值都是唯一的,(其实主键没有太多的实际意义)。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。这也很像excel中的vlookup函数起到得而作用一样,但是join的使用会更加的高级,有下面几种形式的使用:
JOIN和Inner Join: 如果表中有至少一个匹配,则返回行
LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
FULL JOIN: 只要其中一个表中存在匹配,就返回行
关于这一部分大家应该多多操作,我想这部分在以后的工作中肯定会是经常用到的,因为时间原因这部分内容就不细说了,可以参考W3School上的案例。现在随着自己计划的一步步进行,竟然有些恐慌了,真的学的越多感觉欠缺的越多,为了找工作先最少得而必要知识。想想站在未来的角度来看,肯定是能够找到工作的,或许工作还不错,这样一想结果非常明确了,只是过程需要自己来经历,这样一想焦灼是完全没有必要的。
福利,文中使用的数据
