一、
# -*- coding: utf-8 -*-
"""
Created on Thu May 31 19:20:38 2018
@author: gxg
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import os
os.chdir(r'D:\work\card\HW4')
snd = pd.read_csv("auto_ins.csv",encoding = 'gbk')
snd.head()
#首先对loss重新编码为1/0,有数值为1,命名为loss_flag
snd["Loss_flag"] = snd.Loss.map(lambda x: 1 if x >0 else 0)
#对loss_flag分布情况进行描述分析
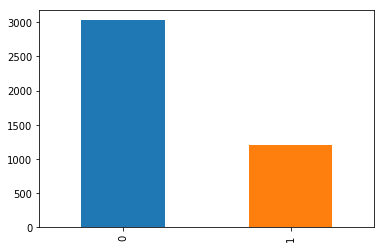
print(snd.Loss_flag.value_counts())
"""
0 3028
1 1205
Name: Loss_flag, dtype: int64
"""
snd.Loss_flag.value_counts().plot(kind="bar")
print(snd.Loss_flag.agg(['mean','median','sum','std','skew']))
"""
mean 0.284668
median 0.000000
sum 1205.000000
std 0.451310
skew 0.954705
Name: Loss_flag, dtype: float64
"""
#分析是否出险和年龄、驾龄、性别、婚姻状态等变量之间的关系(提示:使用分类盒须图,堆叠柱形图)
from stack2dim import *
#堆叠柱形图
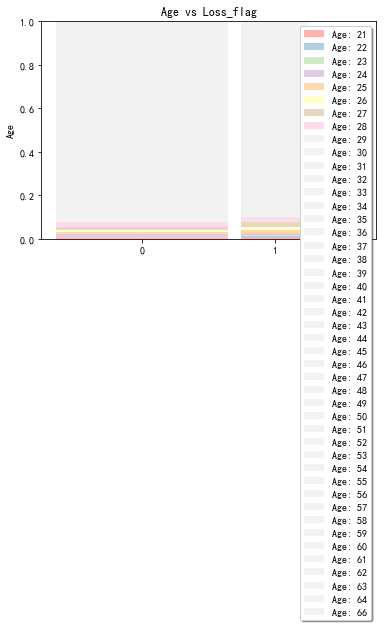
stack2dim(snd, i="Loss_flag", j="Age")
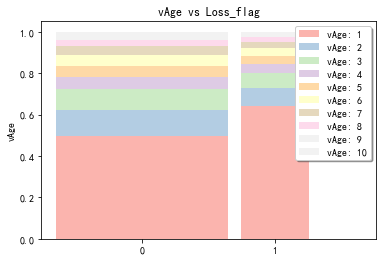
stack2dim(snd, i="Loss_flag", j="vAge")
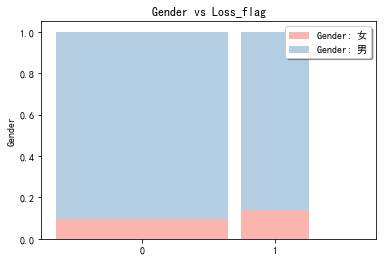
stack2dim(snd, i="Loss_flag", j="Gender")
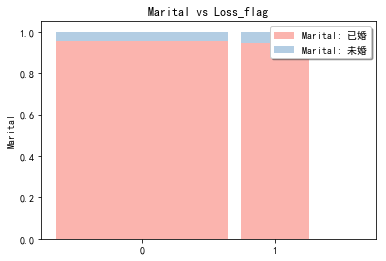
stack2dim(snd, i="Loss_flag", j="Marital")
#分类盒须图
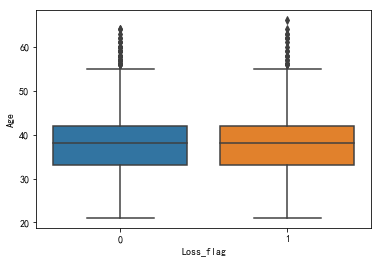
sns.boxplot(x = 'Loss_flag', y = 'Age', data = snd)
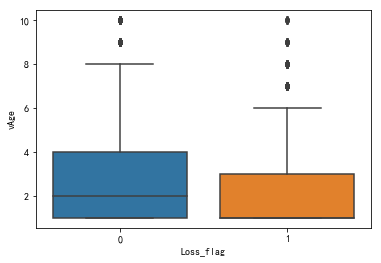
sns.boxplot(x = 'Loss_flag', y = 'vAge', data = snd)
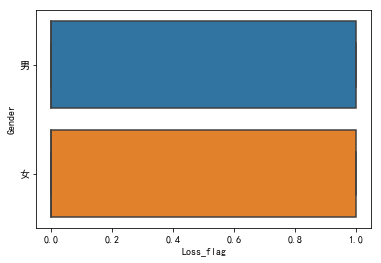
sns.boxplot(x = 'Loss_flag', y = 'Gender', data = snd)
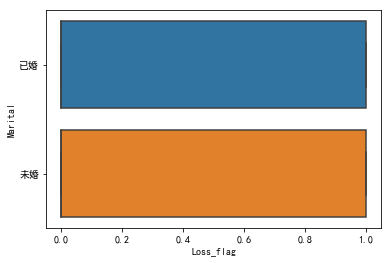
sns.boxplot(x = 'Loss_flag', y = 'Marital', data = snd)
 、
、
二、
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 1 19:22:49 2018
@author: gxg
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import os
import datetime as dt
##########################################################################################################################################################################################
# # 1 数据整理
# ## 1.1导入数据
# In[2]:
os.chdir("D:\work\card\HW5")
loanfile = os.listdir()
createVar = locals()
for i in loanfile:
if i.endswith("csv"):
createVar[i.split('.')[0]] = pd.read_csv(i, encoding = 'gbk')
print(i.split('.')[0])
data2 = pd.merge(loans, disp, on = 'account_id', how = 'left')
data2 = pd.merge(data2, clients, on = 'client_id', how = 'left')
data2=data2[data2.type=='所有者']
data2 = pd.merge(data2, card, on = 'disp_id', how = 'inner')
data2.head()
from stack2dim import *
#不同类型卡的持卡人的性别对比,
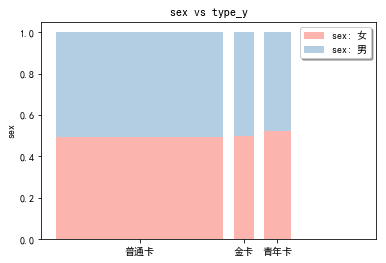
stack2dim(data2, i="type_y", j="sex")
#不同类型卡的持卡人在办卡时的平均年龄对比
data2["agetmp"]=pd.to_datetime(data2["birth_date"])
now_year=dt.datetime.now().year
data2["age"]=now_year-data2.agetmp.dt.year
data2.head()
#data_avgtmp = data2.groupby('account_id')['age'].agg([('avg_balance','mean')])
#data7 = pd.merge(data2, data_avgtmp, left_on='account_id', right_index= True, how = 'left')
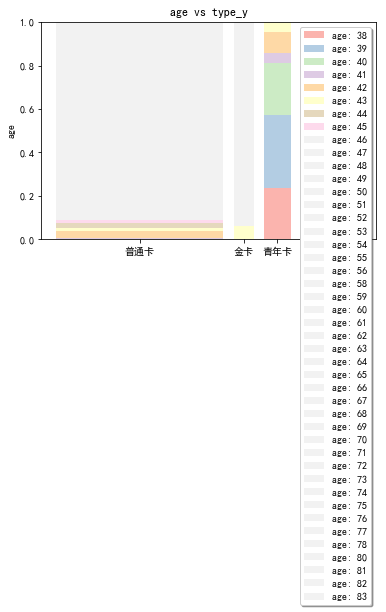
stack2dim(data2, i="type_y", j="age")
#不同类型卡的持卡人在办卡前一年内的平均帐户余额对比
data_4temp1 = pd.merge(loans[['account_id', 'date']],
trans[['account_id','type','amount','balance','date']],
on = 'account_id')
data_4temp1.columns = ['account_id', 'date', 'type', 'amount', 'balance', 't_date']
data_4temp1 = data_4temp1.sort_values(by = ['account_id','t_date'])
data_4temp1['date']=pd.to_datetime(data_4temp1['date'])
data_4temp1['t_date']=pd.to_datetime(data_4temp1['t_date'])
data_4temp1.tail()
data_4temp1['balance2'] = data_4temp1['balance'].map(
lambda x: int(''.join(x[1:].split(','))))
data_4temp1['amount2'] = data_4temp1['amount'].map(
lambda x: int(''.join(x[1:].split(','))))
data_4temp1.head()
import datetime
data_4temp2 = data_4temp1[data_4temp1.date>data_4temp1.t_date][
data_4temp1.date<data_4temp1.t_date+datetime.timedelta(days=365)]
data_4temp2.tail()
data_4temp3 = data_4temp2.groupby('account_id')['balance2'].agg([('avg_balance','mean'), ('stdev_balance','std')])
data_4temp3['cv_balance'] = data_4temp3[['avg_balance','stdev_balance']].apply(lambda x: x[1]/x[0],axis = 1)
data_4temp3.head()
data4 = pd.merge(data2, data_4temp3, left_on='account_id', right_index= True, how = 'left')
data4.head()
#stack2dim(data4, i="type_y", j="avg_balance")
#不同类型卡的持卡人在办卡前一年内的平均收入对比
type_dict = {'借':'out','贷':'income'}
data_4temp2['type1'] = data_4temp2.type.map(type_dict)
data_4temp4 = data_4temp2.groupby(['account_id','type1'])[['amount2']].sum()
data_4temp4.head()
data_4temp5 = pd.pivot_table(
data_4temp4, values = 'amount2',
index = 'account_id', columns = 'type1')
data_4temp5.fillna(0, inplace = True)
data_4temp5['r_out_in'] = data_4temp5[
['out','income']].apply(lambda x: x[0]/x[1], axis = 1)
data_4temp5.head()
data5 = pd.merge(data2, data_4temp5, left_on='account_id', right_index= True, how = 'left')
data5.head()
#stack2dim(data5, i="type_y", j="income")