读完上一篇的你,或许会觉得我说的内容太琐碎,太简单。那么进入第二步,许多和“数”相关的东西,就要在此展开了。
从审核数据源质量,到提升数据集质量,再到明确数据类型和单位,走完这三步,你就完成了数据清洗的过程。你是觉得被扒了层皮还是神清气爽?我的文字并不有趣,想必你一定相当疲累。那么实在不好意思,接下去来看些更疲惫的东西吧。若你在日常工作中不需要处理数据,你大可不必在意前面的部分,因为,接下去描述统计的内容,才是数据认知的核心技能。
对于描述统计,我很难给出一个定义,只知道它包括了平均数、方差、标准差、最大最小值、四分卫数、峰度、偏度等一系列的统计量。我不会机械地罗列这一个个统计量的计算方式和使用场景,我将以一个典型的案例来阐述描述统计量的使用,并将引申到“多维交叉”,一种我所认为的数据认知中最具艺术性的方法。这部分内容中,我会使用到Excel中一个强大的功能,那就是“数据透视表”。相信很多人都已经使用过这个功能了,但我真心觉得它太灵活了,因此要把它用好,肯定还有许多内容值得阐述。(自从使用了数据透视表,我少写了好多数据处理代码。)
“描述统计分析”的过程,就是让你快速地从一堆数据中抽象出信息的过程。举个不那么恰当的例子:假设你是一个女生,想知道一个帅哥到底有多帅,你并不需要把他扒光了然后仔仔细细地观察他身体的每一个细节,而你只需要几个关键的信息,比如瘦高、有肌肉、眼睛大、鼻子高、瓜子脸、短发;有了这几个信息,你脑子里就会浮现出吴彦祖、张震、彭于晏、胡歌等人的形象,这样你对这个帅哥就会有了具体的期待。
我们从使用频率最高的平均数开始说起。
平均数反映数据大小的一般水平
平均值或许是我们使用得最多却对其含义最为模糊的一个概念了。假设你是一个年级的教导主任,你想要知道这个年级当中哪个班级的学习成绩最好,你的第一反应一定是对比每个班级考试的平均数,哪个班级的平均数最高,说明它整体学生的成绩更出色。你肯定不会拿每个班的第一名学生的成绩来对比,你骨子里都会觉得这样做是错误的,虽然你说不出个为什么。
上面这个简单的例子其实透露出一个描述统计中的核心思想:
当需要描述某个群体的信息时,由群里内的多个个体所归纳而出的信息,其合理性要高于群体中单个个体的信息。
我们回过头来讨论平均数,其含义是一个群体在某项数据上的一般水平。需要指出的是,这里所指的“群体”,并不是狭隘的指一群诸如人、产品、猫、狗这样的观察对象,它也指时间维度上的一组观察数据,比如我过去30天每天的日常开销、我家的猫过去30天每天拉屎的次数等。
对于“一般水平”,值得我们展开来详细讨论。衡量一般水平,我们就需要使用平均数的算法了。大家都耳熟能详的算术平均数,即“N个数字相加后除以N”,就是平均数算法中最为普遍的一种。但这一种算法是不够的,在实际的业务场景中,算术平均数经常会遇到瓶颈,因此我们还需要掌握多种平均值的计算方式。
中位数
顾名思义,中位数就是指排在中间位置的那个数字。做中位数计算时,我们要先把需要计算平均数的所有数值排序,然后取出排序处在中间的那个数字,作为这个数据序列的平均数。若数据有偶数个,比如10个,我们找不到排序在中间的数字,那么就取排在中间两位的数字,比如第5和第6的两个数字,计算这两个数字的算术平均数,来形成中位数。在Excel中,我们使用MEDIAN()这个函数,就能计算中位数。
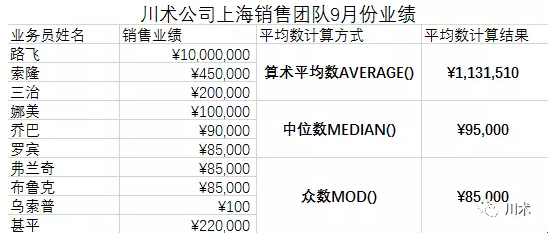
那么中位数的优势是什么呢?为什么要使用它呢?中位数能够避免数据的平均数受到异常值的影响。这一点在当下的数据工作中非常需要警惕。举个最简单的例子,有5个人,他们的月收入分别是(6K,6K,8K,10K,100K),100K这个人的数字其实是统计错了,多加了一个0。如果计算算术平均数,受统计错误的影响,那这5个人的月均收入高达26K,这5个人的群体可以定义为高级白领群。实际上,有4个人离这个数字非常远,他们都是屌丝。如果我们采用中位数计算,那么这个群体的月均收入是8K,就避免了100K这个特殊值带来的影响,使得数据更为准确。
当数据集没有经过认真仔细的清洗时,极有可能存在一些异常值,这些异常值会使得算术平均数失真。尤其是在互联网公司中,数据质量可以说是个老大难的问题,我强烈建议大家在做数据分析的时候,不仅计算算术平均数,也计算中位数,若两个数字差距很大,就用中位数来作为平均数。在我目前的工作当中,与绩效相关的核心指标,我在取数时都会使用中位数代替算术平均数,以减少脏数据带来的风险。
众数
众数,听着这个名字其实你也能想到含义了。它是指将序列中出现次数最多的数字,作为该序列的平均数。众数的应用频率不是很高,但并不代表它不重要。在许多情况下,当你觉得山穷水尽时,往往众数的计算方式能给你以帮助。
众数用在数值型的数据中时,对数字的精度会有一定的降低,毕竟你是要找出出现频率最高的数。如果序列中的数值精度都很高,那你未必找得到众数。从我的经验来说,众数用在人事绩效考核的场景中最多。
但众数真正的价值,我觉得并不是用在数值型的数据中,而是用在类别型的数据中,也可以说是文本型。举个例子,我们的系统每5分钟就会从第三方的天气数据库中读取一次实时的天气,当我要以小时的颗粒度来分析天气情况给我们的用户下单量造成的影响时,如何确定某个地区这一个小时的天气情况?我就取12个记录当中,出现次数最多的记录,作为这个小时天气的平均水平。通过这个例子,相信你在许多的业务场景中都能受到启发。
在Excel当中,我们使用MODE()这个函数来计算众数。如下图,大家觉得,在我YY的这个数据集中,哪一种计算方式更合适?算术平均数显然是太夸张了,而中位数和众数差不多,我觉得都可以采纳。
加权算术平均数为了让平均水平的计算方式能涵盖所有的业务场景,还有一种称为“加权算术平均数”的算法需要介绍。这种方法的应用场景其实可以非常广泛,只要满足这样一个假设:数据集中的每个数字对于计算平均水平的重要性是不同的。我们回到第二章中雷达图对应的例子,即川术公司销售员综合能力评分。如下图,我们认为,工作经验、当月业绩、线索转化率、回款周期和客户评价五项得分,其重要性是不同的。所以,我们在权重这一行中,给予了每个考核项不同的权重,业绩最高,获得了0.4的权重,而回款周期和客户评价最低,只有0.1的权重。从加权平均得分和算术平均得分的结果上看,两种算法得出的分值差距还是相当大的。比如素子,得分较高的项目正好就是权重高的项目,因此加权平均得分的数值比算术平均高得多;可一勇就比较悲剧了,表现好的项目权重低,导致加权平均得分比算术平均低得多。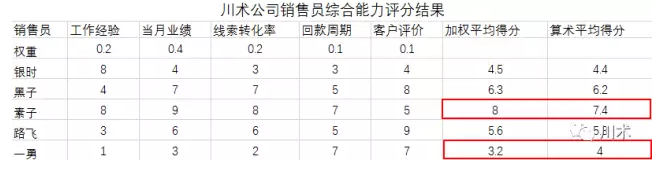
有些人对于此方法不以为然,觉得这只是数学游戏,其实不然。在业务分析场景中,许多事情是不能一刀切的,而需要区别对待。加权平均数算法就是“区别对待”这种思维的具象化。有做人事工作的读者请注意,这个方法在业绩考核中尤其适用,我也非常推荐在业绩考核的数据分析中使用。
介绍完了四种平均数,你是否觉得对平均数的理解加深了呢?坦诚地说,平均数的计算方式还有一些,比如调和平均数和几何平均数,但这两种算法我在日常工作中几乎没有应用,感兴趣的伙伴可以百度之。
探索数据的稳定性
我们来一个CEO的决策扮演。
每个月的月初,你都会坐在那舒适的办公椅上,看着公司上个月的各种业绩报表。9月5日这一天,你关注到公司8月份的平均日销售额和7月份几乎一致,这是从来没有出现过的情况,因为之前的销售业绩多少都有点在增长。你警觉起来,审查数据质量后,发现数据统计是正确的。那么问题来了,8月份的业绩和7月份真的如日均数据上所体现的,是一致的吗?我们的业绩没有变好也没有变坏?有了这个问题你应该怎么办?
有一个简单的答案,那就是分别计算7月份业绩的标准差和8月份业绩的标准差,然后比较大小。标准差数值的大小,衡量了数据序列的波动情况,即稳定性。使用STDEV.P()函数计算了7、8两个月的业绩的标准差后,你发现8月份的标准差显著大于7月份,说明业务风险正在不断增加。于是你警惕起来,为什么8月份的波动幅度会增大呢?
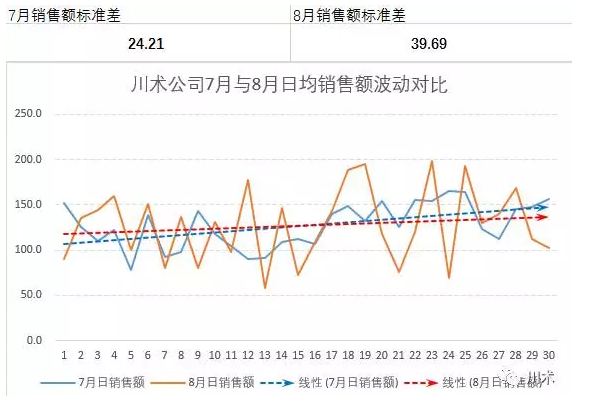
为了进一步认知7月份与8月份业绩波动的区别,你做出了如上的折线图,且添加了线性趋势线来观察变动趋势。直观上看,8月份的折线图,波动确实比7月份要剧烈许多,且从8月11日开始,波动幅度的差别开始加大。说明,8月11日前后的某些决策造成了这样的影响。线性趋势线增长的势头趋于平缓,也一定让你忧心忡忡。
除了波动情况的加大,还需要注意的一点是:8月份的日销售额的高峰值是多次超过7月份的,说明你的团队一定做对了某些事情;但低峰值也要显著低于7月份,说明你也做错了一些事情。你使用了我们在第二章中所介绍的“事件时间轴”的方法,将公司内部和外部发生的事件标注并进行分析后,你似乎找到了原因。
首先,竞争对手在8月初发布了一个不小的改版,产品功能更为强大,用户体验得到大幅提升,且在市场推广上砸下重金。竞对的动作使你的产品和销售的转化能力受到空前的考验。为了应对激烈的竞争,你的运营人员在8月份组织了多次的促销活动,因此在促销活动期间,业绩会大幅增长,而在促销活动停歇期间,业绩大幅下落,因此波动幅度加大。另外,你还在8月份成立了KA销售部,专门针对大客户进行销售。大客户的转化难度大,周期长,但是单价高,因此只要有大客户成功转化的那些天,业绩也会有显著的提升。
经过上面的一段分析,说明促销活动和大客户策略使你守住了市场份额。但当你翻开下一份财务报告,眼睛盯住利润数的变化时,你脑子“翁”的响了起来。眼看着8月份的利润只剩下了7月份的一半,你只能摇头叹息。你稳定了情绪,毕竟,促销活动和销售策略的变化都是短期的阻击战,真正能让你高枕无忧的,还是优秀新产品的问世。
建议你先从CEO的角色扮演游戏中抽出身来。一般来说,我们都会先观察数据的平均水平,在平均水平的信息提取完后,才会关注数据的稳定性。对于数据的稳定性,我建议大家一定要和“风险”两个词联系起来。以我肤浅的知识积累,我认为任何风险衡量的模型,其本质都离不开衡量波动性,即方差与标准差。一个数据的波动性越大,说明它所涵盖的信息量越大,信息量越大,不可知的因素就一定会更多,因此风险会更大。当我们在认知数据的过程中,发现某个数据的波动性有了质的变化时,我们就要留个心眼了,在后续的分析中要尤其关注这个变化,并去探究该变化出现的原因。
标准差就是方差的开根号,而方差就是数据序列中,对每个数字与序列均值的差求平方和,然后除以数据的个数。
有的人可能会继续追究,标准差只衡量了一个数据序列的波动情况,那如果两个甚至多个序列的波动情况怎么衡量呢?难道只是单单将他们各自的标准差加起来吗?如果他们之间有互相影响,这个数据集的波动情况怎么衡量?对于这个问题,我只能回答一部分。衡量两个数据序列间相互波动的情况是有方法的,我们称其为协方差。假设有A和B两组数据,数字个数相同,AB的协方差就是A中的数值与A均值的差乘以B中的数值与B的均值的差,再除以A组数据中数字的个数。在Excel中我们使用COVARANCE.P(A,B)来计算A与B之间的协方差。在后续章节中会着重讲到的相关系数,实质就是协方差比上两组数据各自的标准差的乘积,它衡量了数据之间的变动关系。
为了能在下一章中理解统计推断的过程,这这里有必要将方差、标准差和协方差的计算方式先交代清楚:
方差即序列中各个数值与算术平均数的差值的平方和的均值。假设有(2,3,4)这样一个序列,他们的算术平均数是3,那么方差就是[(2-3)^2+(3-3)^2+(4-3)^2]/3。方差一般用σ^2表示。
标准差即方差的开根号,一般用σ表示。
需要有两个序列才能计算协方差。假设有(2,3,4)和(5,7,9)两个序列,算术平均数是3和7,协方差的计算方法就是[(2-3)*(5-7)+(3-3)*(7-7)+(4-3)*(9-7)]/3。协方差用Cov表示。
快速认知数据的平均水平和波动情况就讲完了,下一节我们将阐述更深奥的“数据分布”。

