【apply】
帮助我们把一个函数或者自定义函数应用到所有的行或者列里面进行处理,可大大提高数据分析的效率。
需求示例:
薪资显示数值后面加上K,例如11.5K
方法1:

用 .str将浮点数据转成文本再进行拼接
方法2:
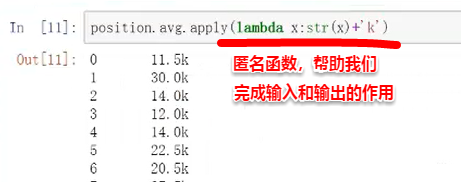
输入x,输出的是 . str和k进行拼接
输入从position.avg来
apply的优点是特别快
方法3:等价方法2(在里面可加进去简单的判断)
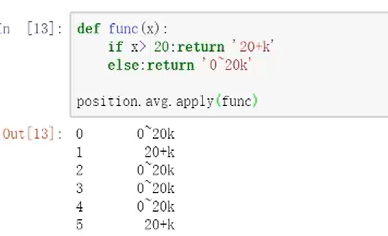
方法4:
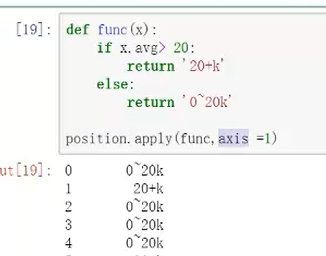
注意,直接position会直接报错,因为对象不能针对整个表,其中参数axis默认为0,是空值对应函数应用到列里面。需要把它设置为=1,说明函数设置应用到列,对这一列数组进行操作,指明是x.avvg则可成功。
1.apply聚合(分组)
需求:不同城市下面新增排名前5的职位。
分析需求:
①对不痛城市--分组
②前5---排序

方法1:记住输入和输出

数据拆开后再合并
方法2:

通过控制参数,变成升序

agg和apply的区别:agg聚合后针对固定的行和列,apply的灵活性比较高,可以对数据进行拆分再组合,不涉及行数的变化用agg是可以的。
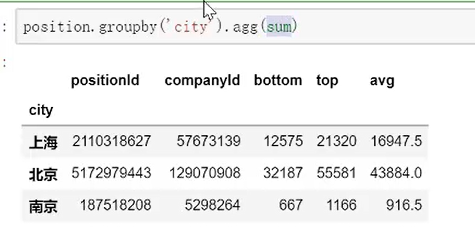
agg直接调用方法;

等价于:

比较高级的用法是,可以同时应用多个函数
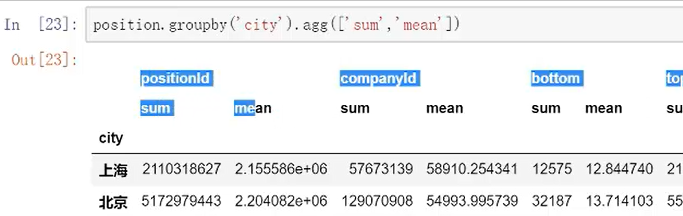
【数据透视表】可以处理超大的数据对比Excel透视
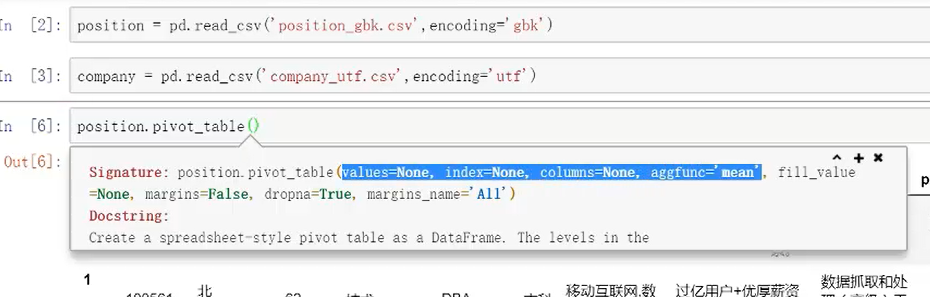
首选要考虑“我想要的数据透视表形式是什么样子的”
values:具体的哪个值进行计算
index:按照什么来进行聚合,例如“city”
columns:列是设什么样子的,例如“workyear”
aggfunc:具体形成什么样子的值,默认是“mean”
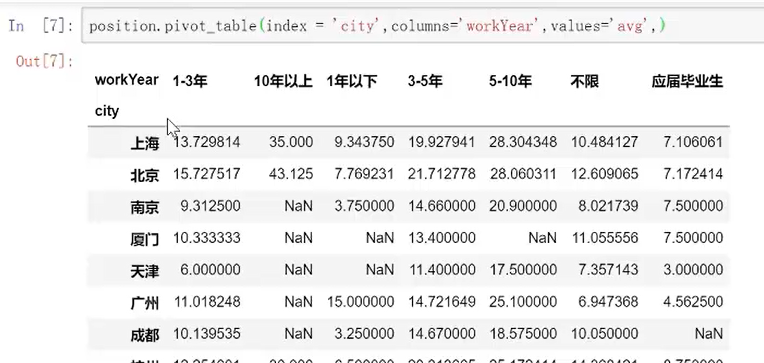
多重索引同样可以
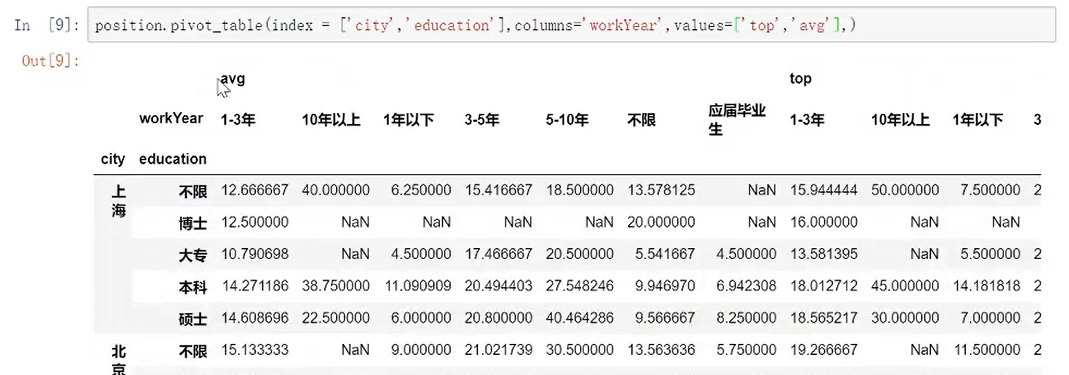
调用np,所以要用np.mean等计算方式,直接mean则会报错
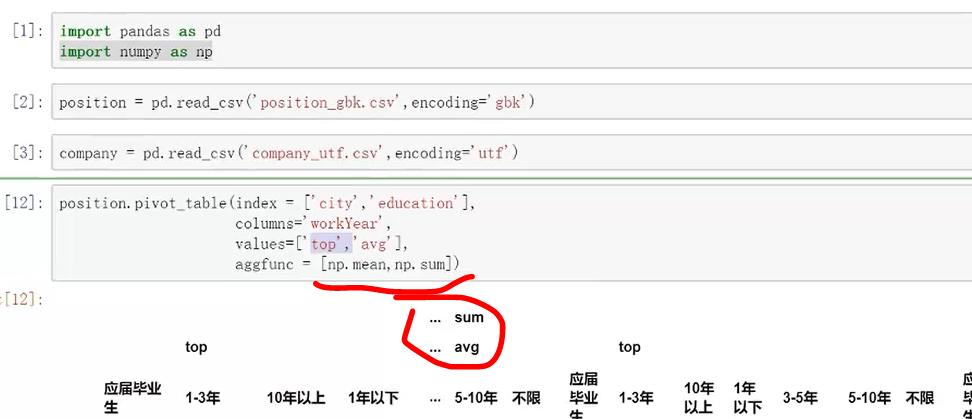
也可在此表格进行继续接片
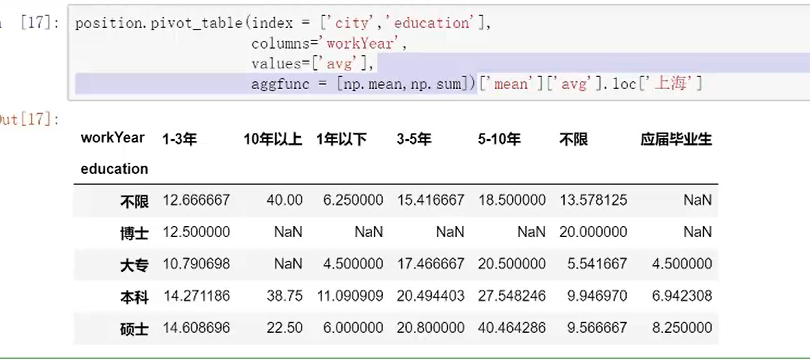
其中margins参数=Ture是在透视表下面添加汇总项目
dropna=Ture,就是把一些空值砍掉
透视表的一些高级用法:
需求:只想要对平均薪资进行平均,top进行求和,想要计算values的值是有针对性的。
方法:aggfuns里面把列表改成字典
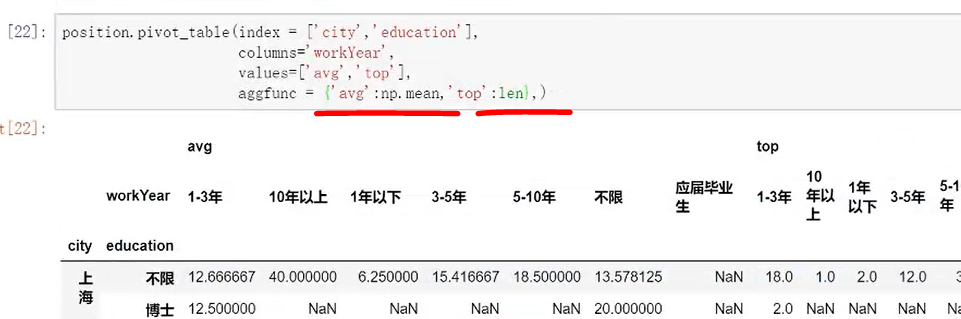
应用场景,对处理大数据量的统计提供很好的工具。
【链接数据库】
建议用pandas链接数据库,会比较方便
需要安装一依赖包
老师在讲的时候说新人在安装依赖包的时候回会遇到些问题,很幸运~我就遇到了~~~
安装包的时候出现“pip不是内部外部,或其他可执行的程序”的报错
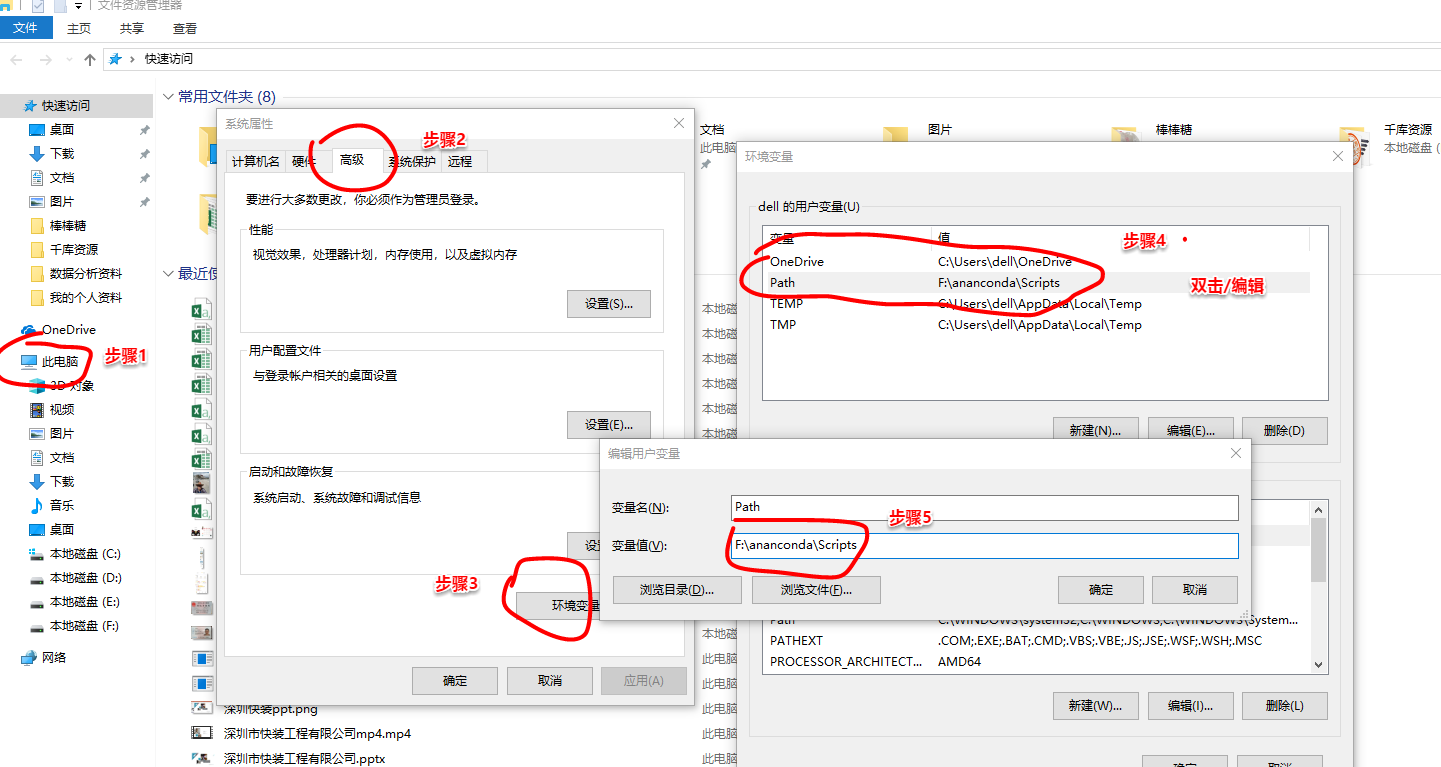
方法:需要把环境配置一下,
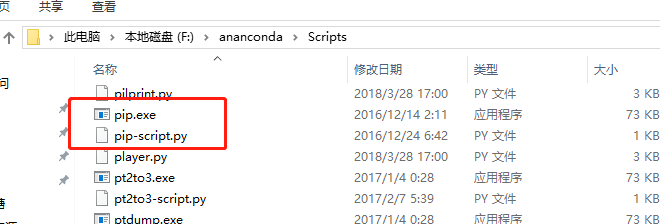
此电脑-->属性-->高级-->环境变量-->Path-->把ananconda里面含有pip程序的两个文件的位置路径放进去-->保存-->调用cmd(win+r,输入cmd)-->成功
1.链接数据库方式1
import pymysql #加载变量
conn=pymysql.connect(
host='localhost', #定义新的变量链接,可以直接输入localhost,也可以直接输入本地的地址127.0.0.11因为mysql一般都是本地所以这两种方法均可
user='root', #数据库用户名称
password='12346', #账号密码
db='data', #想要链接的数据库
port=3306, #输入端口,默认的,如果有变化自己更改即可
charset='utf8' #文本编码如果是gbk则改成gbk对应
)
创建后调用一个方法(直接记住)
conn.cursor()
之后可以用 .execute()来进行sql语句的输入

如果需要把所有的结果都执行出来
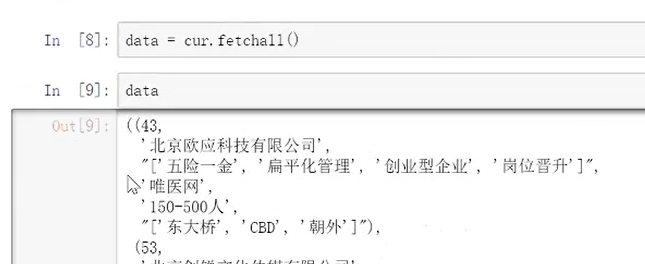
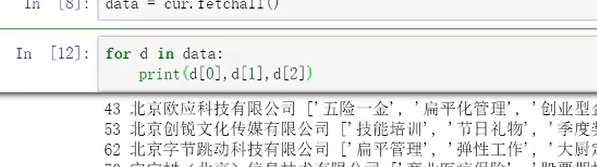
data=cur.fetchall()
不过会以元组的形式输出,需要简单处理一下
进行增删该查后的结果提交操作可用 .conn.commit()方可提交
打开游标之后,需要养成好的习惯进行关闭
cur.close()
同样,数据库连接进行关闭
conn.close()
2.连接数据库方式2
pandas在数据库的应用最关键的是sql和con
可直接先把sql语句写好
要注意的是链接是比较特殊的,新的链接方式 .orm帮助数据读写的sqlalchemy
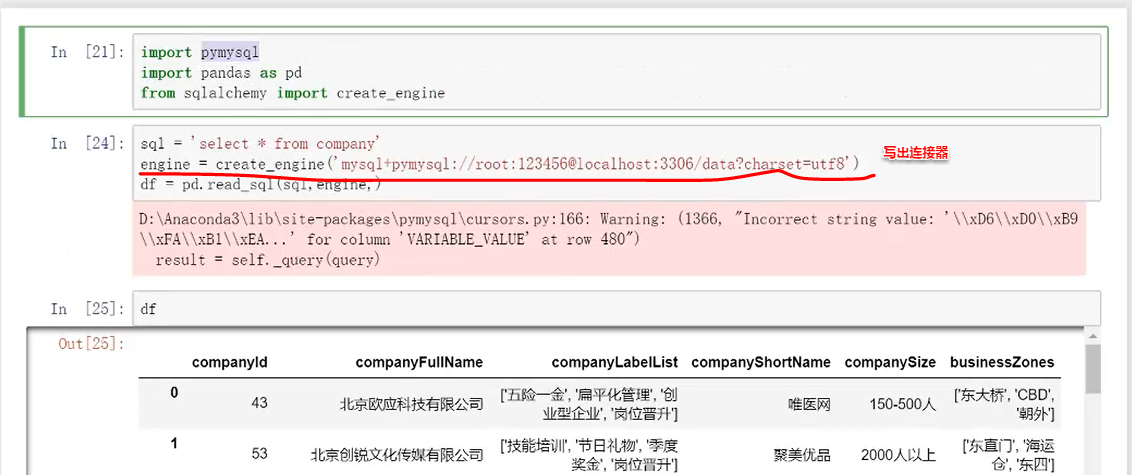
从读取到处理然后到写入数据库的过程:
①读取表:
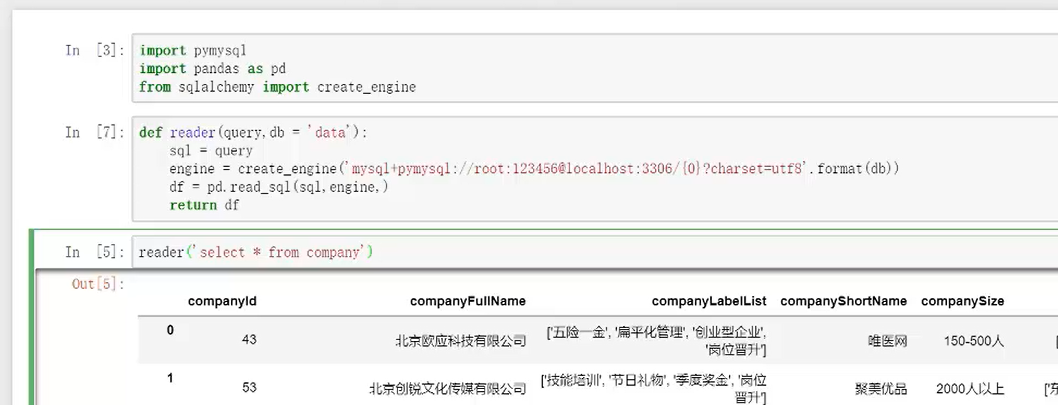
如果忘记数据库中有哪些表的具体名头可以用此函数进行查看
reader('show tables')
②处理合并多表格
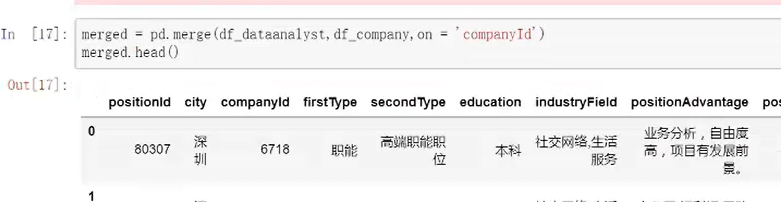
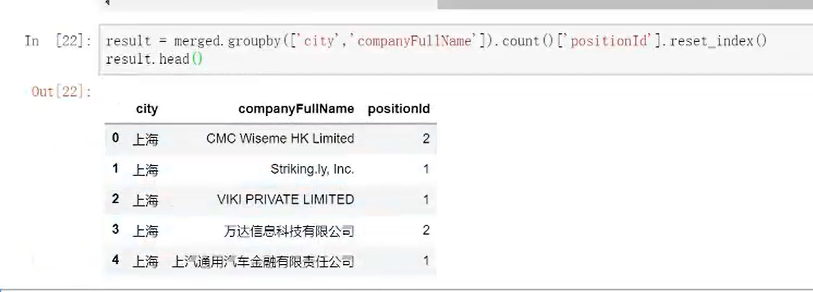
③按照需求条件,分组汇总,提取部分数值转换重置成数据框
④查看数据类型是否需要更改
result.info()
⑤写入数据库

参数if_exists指的是他是否存在了 ='fail' 是默认的,也就是说如果表存在的话,则写入是失败的。
把参数修改成 ='append' 是指插入数据,即表存在的话则是插入数据,表不存在的话则会是新建数据,
参数index,如果 =True 是代表写入的时候把数据框里面的索引变成一列进行存储;一般会更改为 =False 不写入。

返回mysql数据库查看
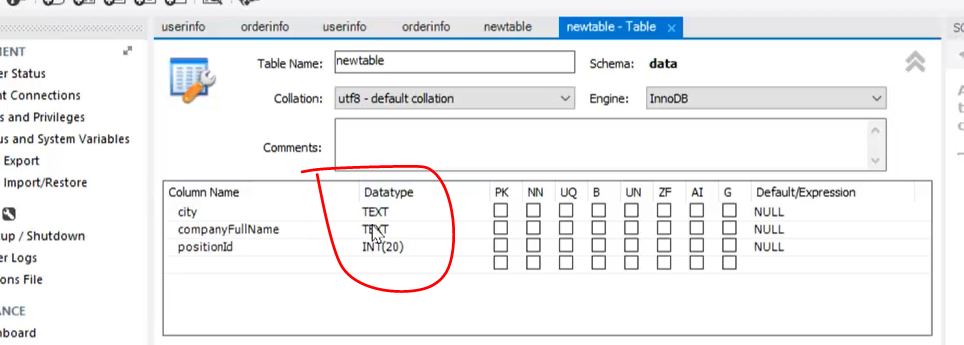
会发现新导入的表格的字段类型和之前的不太相符,不是预想的最优形式。
建议在开始做的时候,预先在数据库中建好,设置好新的表格表头及类型,然后再进行导入。
并且注意,在python导入运行步骤时候,如不小心执行了多次,则在数据库中也会相应的重复增加多次的数据,所以操作要小心谨慎。
当在数据库建表的时候字段小于导入字段的时候,python会报错。
当在数据库建表的时候字段大于导入字段的时候,python则可正常写入,在数据库中可自动匹配为空。
⑥写入 .csv
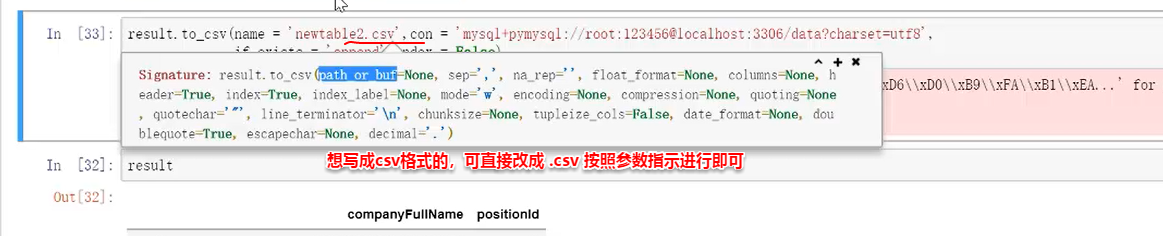
********* end********
******** 准备进入实战篇 *******
