
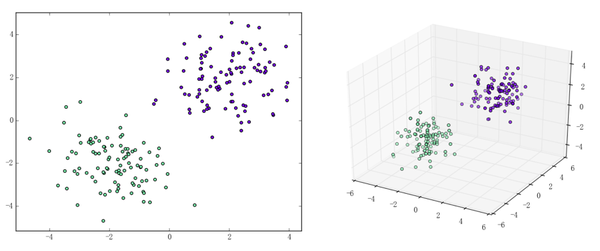
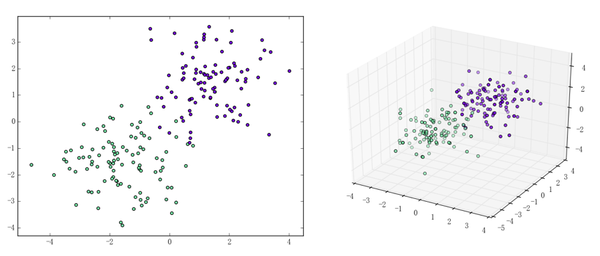
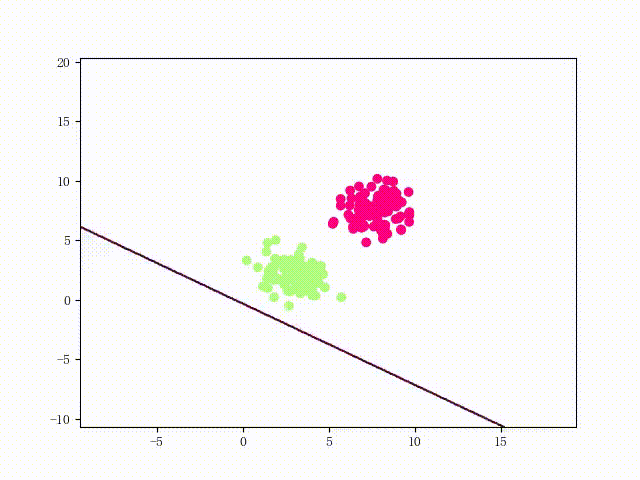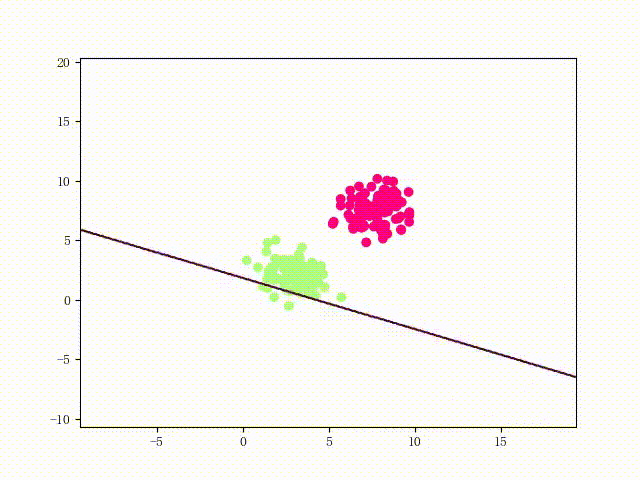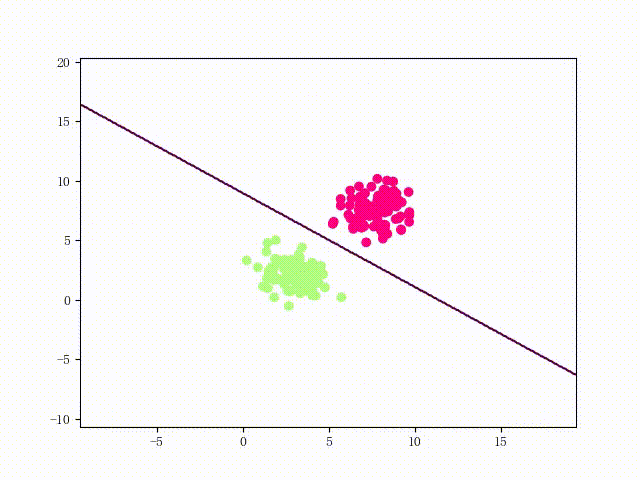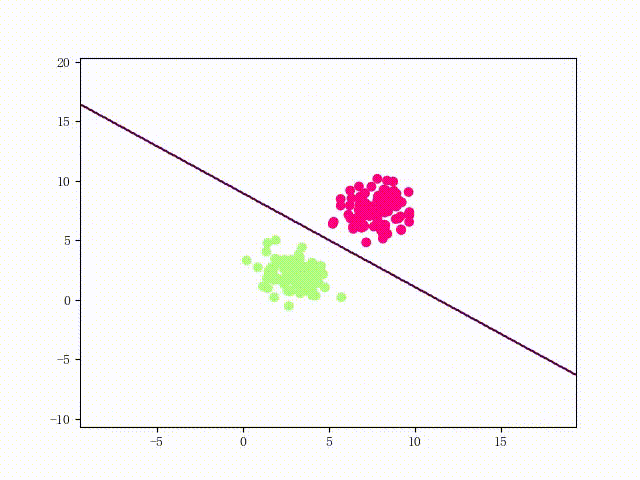
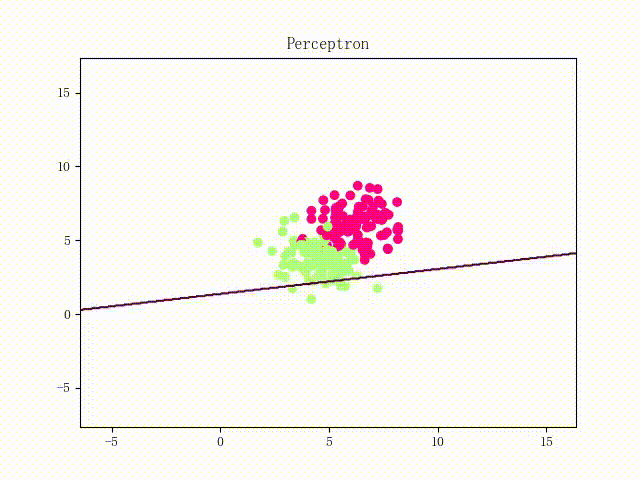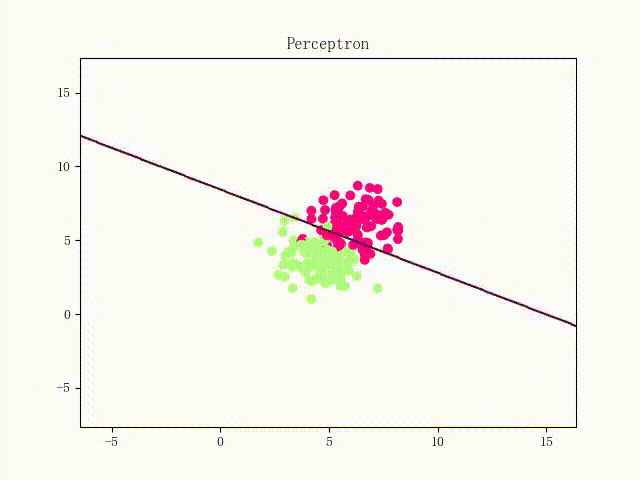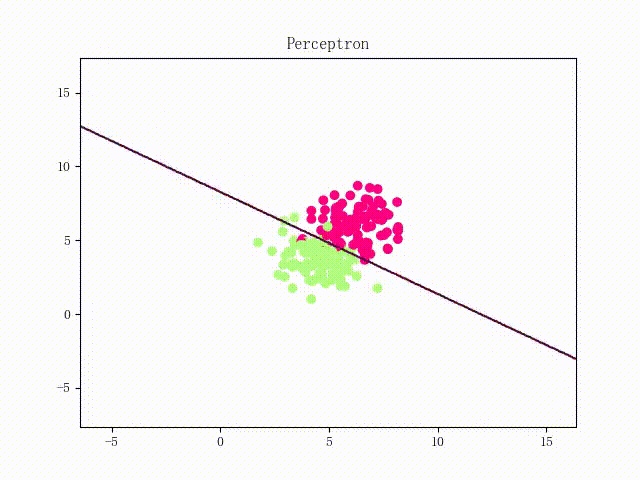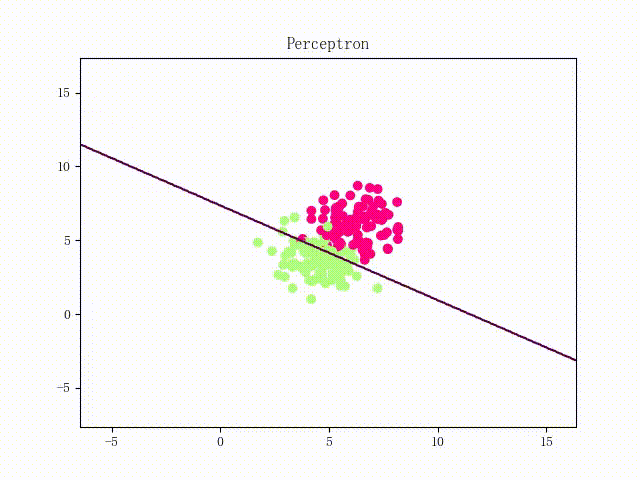
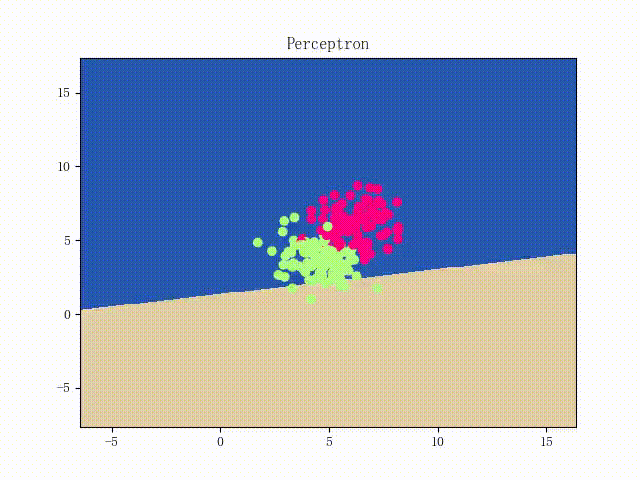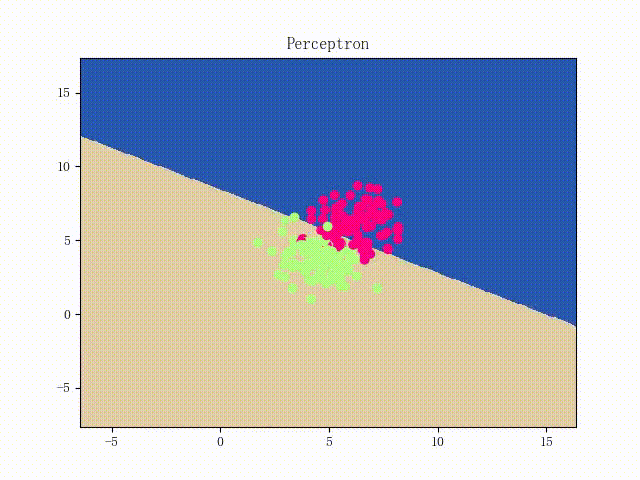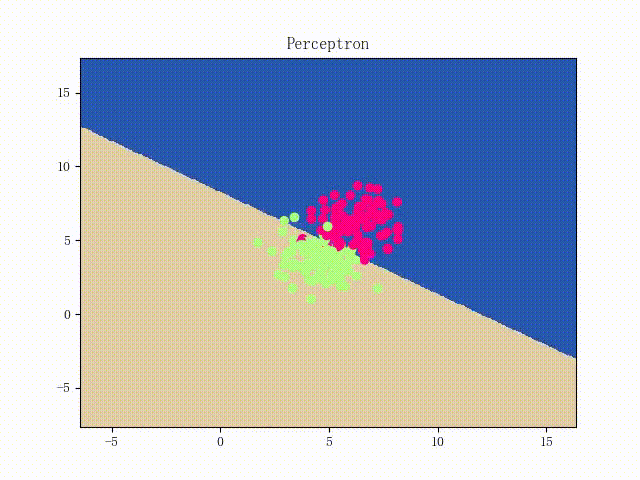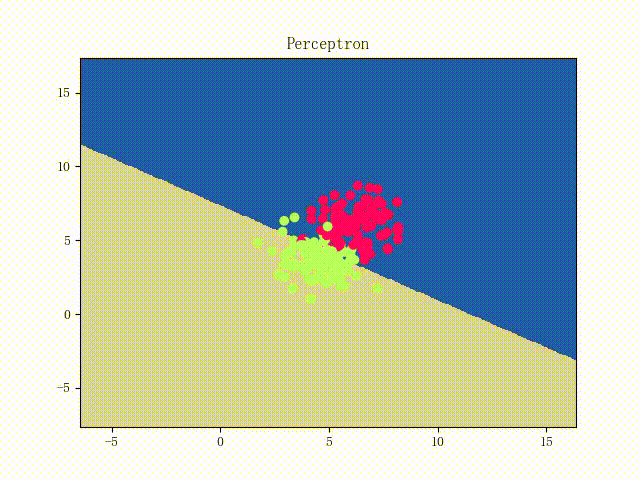
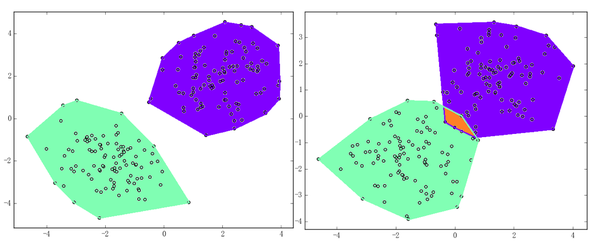

本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。
2 个评论
好高级的说
射命丸咲 回复 liaohaiyin
| ω・`)