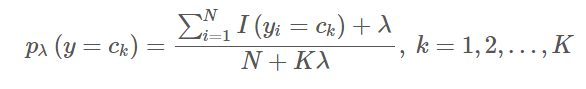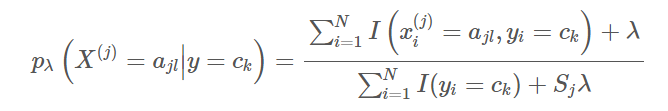首先要叙述朴素贝叶斯算法的基本假设:
- 独立性假设:假设单一样本
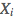 、的 n 个维度
、的 n 个维度 彼此之间在各种意义上相互独立
彼此之间在各种意义上相互独立
这当然是很强的假设,在现实任务中也大多无法满足该假设。由此会衍生出所谓的半朴素贝叶斯和贝叶斯网,这里先按下不表
然后就是算法。我们打算先只叙述它的基本思想和各个公式,相关的定义和证明会放在后面的文章中。不过其实仅对着接下来的公式敲代码的话、就已经可以实现一个朴素贝叶斯模型了:
- 基本思想:后验概率最大化、然后通过贝叶斯公式转换成先验概率乘条件概率最大化
- 各个公式(假设输入有 N 个、单个样本是 n 维的、一共有 K 类:
 )
)- 计算先验概率的极大似然估计:
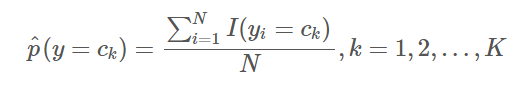
- 计算条件概率的极大似然估计:
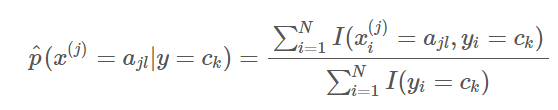
其中样本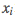 第 j 维
第 j 维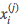 的取值集合为
的取值集合为
- 得到最终的分类器:
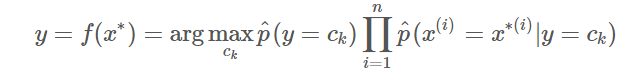
在朴素贝叶斯算法思想下、一般来说会衍生出以下三种不同的模型:
- 离散型朴素贝叶斯(MultinomialNB):所有维度的特征都是离散型随机变量
- 连续型朴素贝叶斯(GaussianNB):所有维度的特征都是连续型随机变量
- 混合型朴素贝叶斯(MergedNB):各个维度的特征有离散型也有连续型
接下来就简单(并不简单啊喂)讲讲朴素贝叶斯的数学背景。由浅入深,我们会用离散型朴素贝叶斯来说明一些普适性的概念,连续型和混合型的相关定义是类似的
朴素贝叶斯与贝叶斯决策论的联系
朴素贝叶斯的模型参数即是类别的选择空间: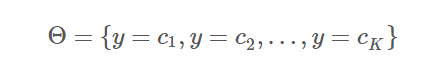
朴素贝叶斯总的参数空间 本应包括模型参数的先验概率
本应包括模型参数的先验概率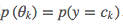 、样本空间在模型参数下的条件概率
、样本空间在模型参数下的条件概率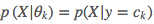 和样本空间本身的概率
和样本空间本身的概率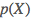 ;但由于我们采取样本空间的子集
;但由于我们采取样本空间的子集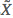 作为训练集,所以在给定的下、
作为训练集,所以在给定的下、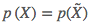 是常数,因此可以把它从参数空间中删去。换句话说,我们关心的东西只有模型参数的先验概率和样本空间在模型参数下的条件概率
是常数,因此可以把它从参数空间中删去。换句话说,我们关心的东西只有模型参数的先验概率和样本空间在模型参数下的条件概率
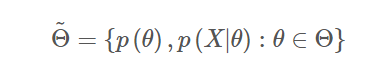
行动空间A就是朴素贝叶斯总的参数空间
决策就是后验概率最大化(在推导与推广里,我们会证明该决策为贝叶斯决策)
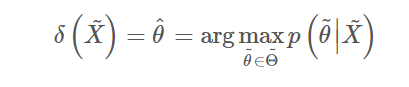
在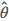 确定后,模型的决策就可以具体写成(这一步用到了独立性假设)
确定后,模型的决策就可以具体写成(这一步用到了独立性假设)
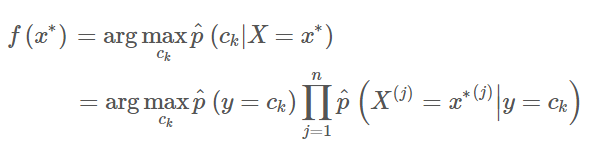
损失函数会随模型的不同而不同。在离散型朴素贝叶斯中,损失函数就是比较简单的 0-1 损失函数
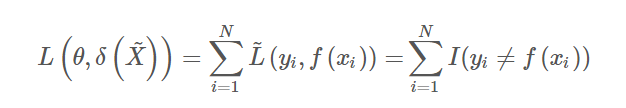
这里的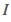 是示性函数,它满足:
是示性函数,它满足:

从上述定义出发、可以利用上一篇文章中讲解的两种参数估计方法导出离散型朴素贝叶斯的算法(详见推导与推广):
- 输入:训练数据集
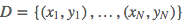
- 过程(利用 ML 估计导出模型的具体参数):
- 计算先验概率
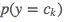 的极大似然估计:
的极大似然估计:
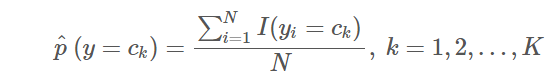
- 计算条件概率的极大似然估计(设每一个单独输入的 n 维向量的第 j 维特征
 可能的取值集合为
可能的取值集合为 ):
):
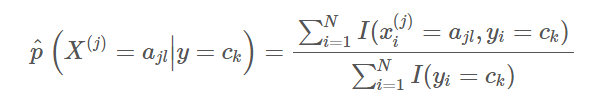
- 输出(利用 MAP 估计进行决策):朴素贝叶斯模型,能够估计数据
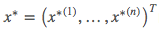 的类别:
的类别:
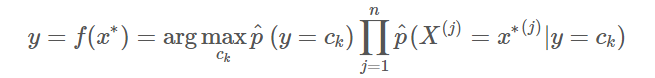
由上述算法可以清晰地梳理出朴素贝叶斯算法背后的数学思想:
- 使用极大似然估计导出模型的具体参数(先验概率、条件概率)
- 使用极大后验概率估计作为模型的决策(输出使得数据后验概率最大化的类别)
离散型朴素贝叶斯实例
接下来我们在一个简单、虚拟的数据集上应用离散型朴素贝叶斯算法以加深对算法的理解,该数据集(不妨称之为气球数据集 1.0)如下表所示(参考了 UCI 上相应的数据集):
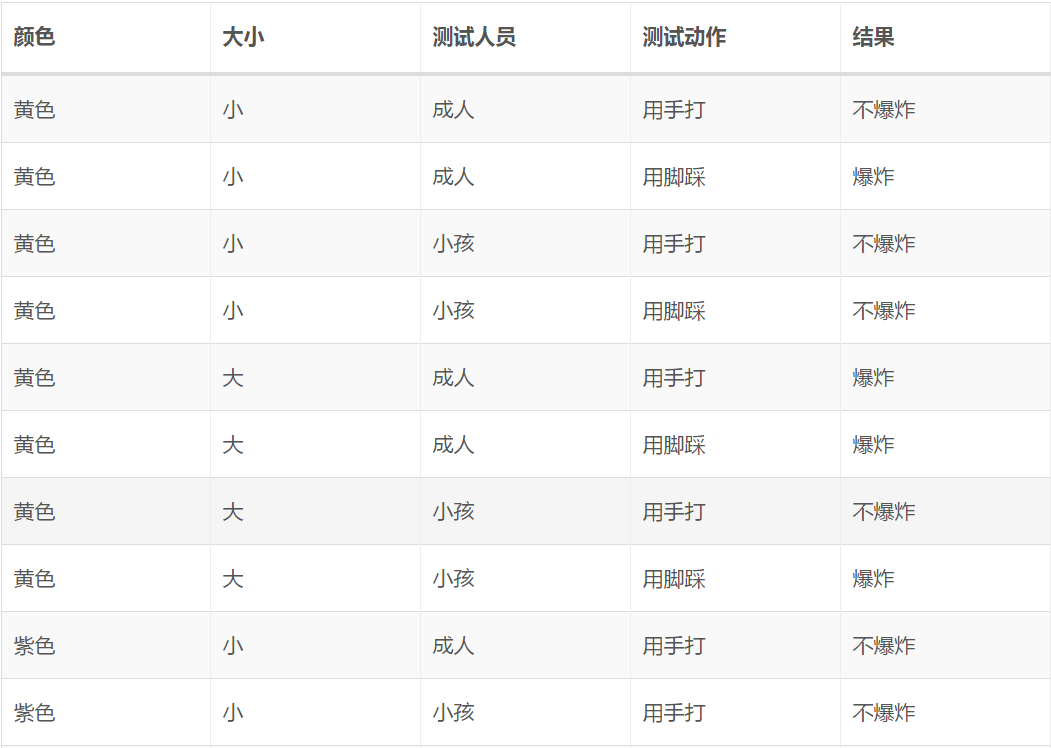
该数据集的电子版本可以参见这里。我们想预测的是样本:

所导致的结果。容易观察到的是、气球的颜色对结果不起丝毫影响,所以在算法中该项特征可以直接去掉。因此从直观上来说,该样本所导致的结果应该是“不爆炸”,我们用离散型朴素贝叶斯算法来看看是否确实如此。首先我们需要计算类别的先验概率,易得:
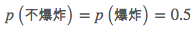
亦即类别的先验概率也对决策不起作用。继而我们需要依次求出第2、3、4个特征(大小、测试人员、测试动作)的条件概率,它们才是决定新样本所属类别的关键。易得:

那么在条件“紫色小气球、小孩用脚踩”下,知(注意我们可以忽略颜色和先验概率):

所以我们确实应该认为给定样本所导致的结果是“不爆炸”
不足与改进
需要指出的是,目前为止的算法存在一个问题:如果训练集中某个类别ckck的数据没有涵盖第 j 维特征的第 l 个取值的话、相应估计的条件概率p^(X(j)=ajl∣∣y=ck)就是 0、从而导致模型可能会在测试集上的分类产生误差。解决这个问题的办法是在各个估计中加入平滑项(也有这种做法就叫贝叶斯估计的说法):
可见当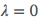 时就是极大似然估计,而当
时就是极大似然估计,而当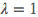 时、一般可以称之为拉普拉斯平滑(Laplace Smoothing)。拉普拉斯平滑是常见的做法、我们的实现中也会默认使用它。可以将气球数据集 1.0 稍作变动以彰显加入平滑项的重要性(新数据集如下表所示,不妨称之为气球数据集 1.5):
时、一般可以称之为拉普拉斯平滑(Laplace Smoothing)。拉普拉斯平滑是常见的做法、我们的实现中也会默认使用它。可以将气球数据集 1.0 稍作变动以彰显加入平滑项的重要性(新数据集如下表所示,不妨称之为气球数据集 1.5):
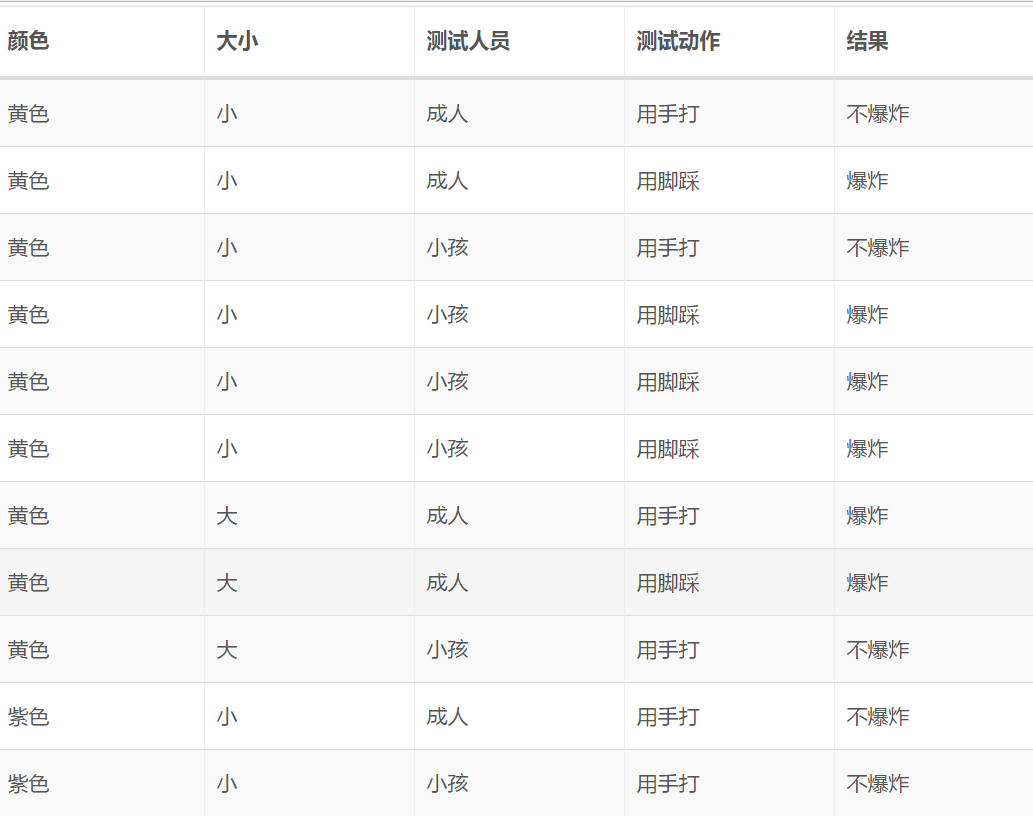
该数据集的电子版本可以参见这里。可以看到这个数据集是“不太均衡”的:它对样本“黄色小气球,小孩用脚踩”重复进行了三次实验、而对所有紫色气球样本实验的结果都是“不爆炸”。如果我们此时想预测“紫色小气球,小孩用脚踩”的结果,虽然从直观上来说应该是“爆炸”,但我们会发现、此时由于
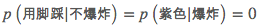
所以会直接导致

从而我们只能随机进行决策,这不是一个令人满意的结果。此时加入平滑项就显得比较重要了,我们以拉普拉斯平滑为例、知(注意类别的先验概率仍然不造成影响):

从而可算得:
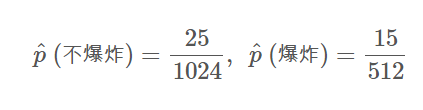
因此我们确实应该认为给定样本所导致的结果是“爆炸”
(猛戳我进入下一章!( σ'ω')σ)