作者:蒋守壮
作者介绍:蒋守壮,现就职于金拱门(中国)有限公司,担任大数据卓越中心高级工程和平台经理,负责大数据平台的架构和产品研发。
背景:
对于很多使用Apache Kylin的朋友来说,在生产环境搭建完成之后,如何在业务使用之前通过压测掌握Kylin的性能是一个必要问题,这样有助于提前发现问题、优化系统参数、提高性能,包括Kylin本身的Job和Query调优、并发构建Cube、HBase写入和查询性能、以及MapReduce或Spark调优等等。
SSB介绍:
Kyligence官方提供了开源的SSB(Star Schema Benchmark)压测工具(https://github.com/Kyligence/ssb-kylin),这是基于TPC-H benchmark(http://www.tpc.org/tpch)修改,并专门针对星型模型OLAP场景下的测试工具。
测试的过程会生成5张表,测试的数据量可以根据参数调整。SSB的表结构如下图所示:
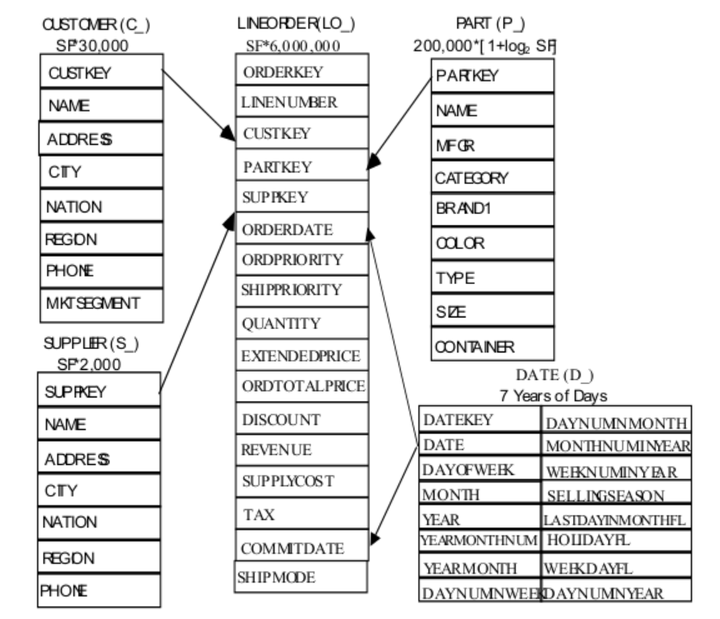
其中lineorder为事实表,其他四张为维度表,每张维度表通过primary key与事实表关联,标准的星型结构。
本次压测的环境是CDH 5.13.3,开启了Kerberos和OpenLDAP的认证和授权,使用Sentry提供细粒度、基于角色的授权以及多租户管理模式。但是官方提供的ssb-kylin没有涉及到权限和认证的处理,因此我稍加修改了一下,具体代码见https://github.com/jiangshouzhuang/ssb-kylin。
先决条件:
这里先把Kylin部署的情况说明一下:
- Kylin部署集成OpenLDAP用户统一认证管理
- OpenLDAP中增加Kylin部署的用户kylin_manager_user(用户组为kylin_manager_group)
- Kylin版本为apache-kylin-2.4.0
- Kylin集群情况(VM):
Kylin Job 1个节点:16GB,8Cores
Kylin Query 2个节点:32GB,8Cores
SSB压测之前处理几点:
- Hive数据库中创建ssb数据库
# 使用超级管理员登录hive数据库
create database SSB;
CREATE ROLE ssb_write_role;
GRANT ALL ON DATABASE ssb TO ROLE ssb_write_role;
GRANT ROLE ssb_write_role TO GROUP ssb_write_group;
# 然后在OpenLDAP中把kylin_manager_user添加到kylin_manager_group中,这样kylin_manager_user就有权限访问ssb数据库
2.把HDFS的目录/user/kylin_manager_user读写权限赋予kylin_manager_user用户
3.在kylin_manager_user用户家目录下面配置HADOOP_STREAMING_JAR环境变量
export HADOOP_STREAMING_JAR=/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar
下载SSB工具和编译
在linux终端中输入以下命令,即可迅速下载和编译完成ssb测试工具。
git clone https://github.com/jiangshouzhuang/ssb-kylin.git
cd ssb-kylin
cd ssb-benchmark
make clean
make
调整SSB参数
在ssb-kylin项目中,bin目录下面有一个ssb.conf文件,里面定义了事实表和维度表的base数据量。当我们生成测试数据量时,可以指定scale大小,这样实际的数据为base*scale。
ssb.conf文件的部分内容为:
# customer base, default value is 30,000
customer_base = 30000
# part base, default value is 200,000
part_base = 200000
# supply base, default value is 2,000
supply_base = 2000
# date base (days), default value is 2,556
date_base = 2556
# lineorder base (purchase record), default value is 6,000,000
lineorder_base = 6000000
当然上面的base参数都是可以根据自己的实际需求调整,我采用默认参数就可以了。
在ssb.conf文件中,还有如下的一些参数。
# manufacturer max. The value range is (1 .. manu_max)
manu_max = 5
# category max. The value range is (1 .. cat_max)
cat_max = 5
# brand max. The value range is (1 .. brand_max)
brand_max = 40
解释如下:
manu_max、cat_max和brand_max用来定义层级scale。比如,manu_max=10、cat_max=10和brand_max=10是指总共10个manufactures,每个manufactures最多有10个category parts,而且每个category最多有10个brands。因此manufacture的基数(cardinality)为10,category基数为100,brand基数为1000。
# customer: num of cities per country, default value is 100
cust_city_max = 9
# supplier: num of cities per country, default value is 100
supp_city_max = 9
解释如下:
cust_city_max 和supp_city_max用来定义在customer和supplier表中每个country的city数量。如果country总数为30,并且cust_city_max=100、supp_city_max=10,那么customer表将会有3000个不同的city,supplier表将会有300个不同的city。
提示:
本次压测中是使用Yarn分配的资源来生成测试数据,如果生成数据过程中遇到内存方面的问题,请提高Yarn分配container的内存大小。
生成测试数据
在运行ssb-kylin/bin/run.sh脚本之前,对run.sh解释几点:
- 配置HDFS_BASE_DIR为表数据的路径,因为我赋予kylin_manager_user对/user/kylin_manager_user目录读写权限,所以这里配置:
HDFS_BASE_DIR=/user/kylin_manager_user/ssb
下面运行run.sh时会在此目录下面生成临时和实际数据。
2.配置部署Kylin的LDAP用户和密码,以及操作HDFS等的keytab文件
KYLIN_INSTALL_USER=kylin_manager_user
KYLIN_INSTALL_USER_PASSWD=xxxxxxxx
KYLIN_INSTALL_USER_KEYTAB=/home/${KYLIN_INSTALL_USER}/keytab/${KYLIN_INSTALL_USER}.keytab
3.配置beeline访问hive数据库的方式
BEELINE_URL=jdbc:hive2://hiveserve2_ip:10000
HIVE_BEELINE_COMMAND="beeline -u ${BEELINE_URL} -n ${KYLIN_INSTALL_USER} -p ${KYLIN_INSTALL_USER_PASSWD} -d org.apache.hive.jdbc.HiveDriver"
如果你的CDH或其他大数据平台不是使用beeline,而是hive cli,请自行修改。
一切准备妥当之后,我们开始运行程序,生成测试数据:
cd ssb-kylin
bin/run.sh --scale 20
我们设置scale为20,程序会运行一段时间,最大的lineorder表数据有1亿多条。程序执行完成后,我们查看hive数据库里面的表以及数据量:
use ssb;
show tables;
select count(1) from lineorder;
select count(1) from p_lineorder;
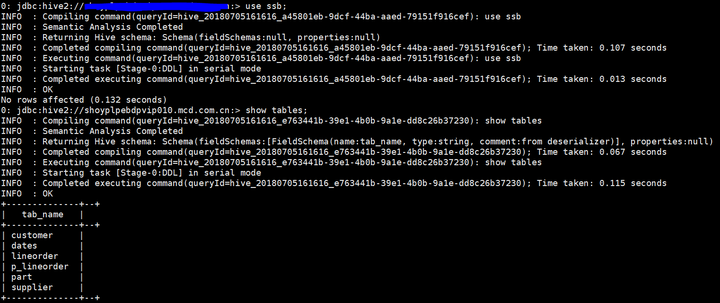
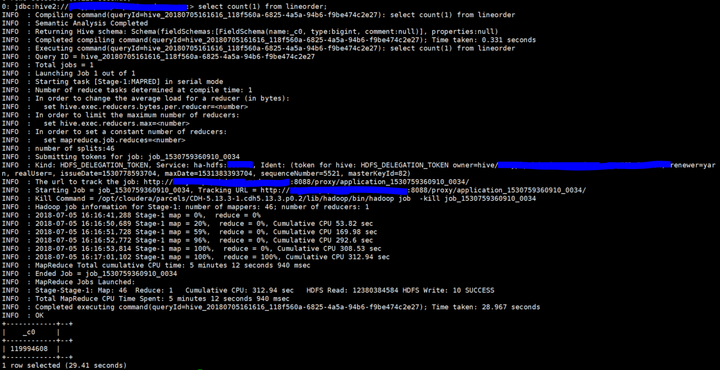
可以看到,一共创建了5张表和一张视图。
加载Cube的元数据以及构建Cube
ssb-kylin项目中已经帮我们提前建好了project、model以及cube,只需要像learn_kylin示例一样,直接导入Kylin即可。Cube Metadata的目录为cubemeta,因为我们的kylin集成OpenLDAP,没有ADMIN用户,所以将cubemeta/cube/ssb.json中的owner参数设为null。
执行如下命令导入cubemeta:
cd ssb-kylin
$KYLIN_HOME/bin/metastore.sh restore cubemeta
然后登录Kylin,执行Reload Metadata。这样就在Kylin中创建新的project、model和cube。再构建cube之前,先Disable,然后再Purge,删除旧的临时文件。
使用MapReduce构建结果如下:
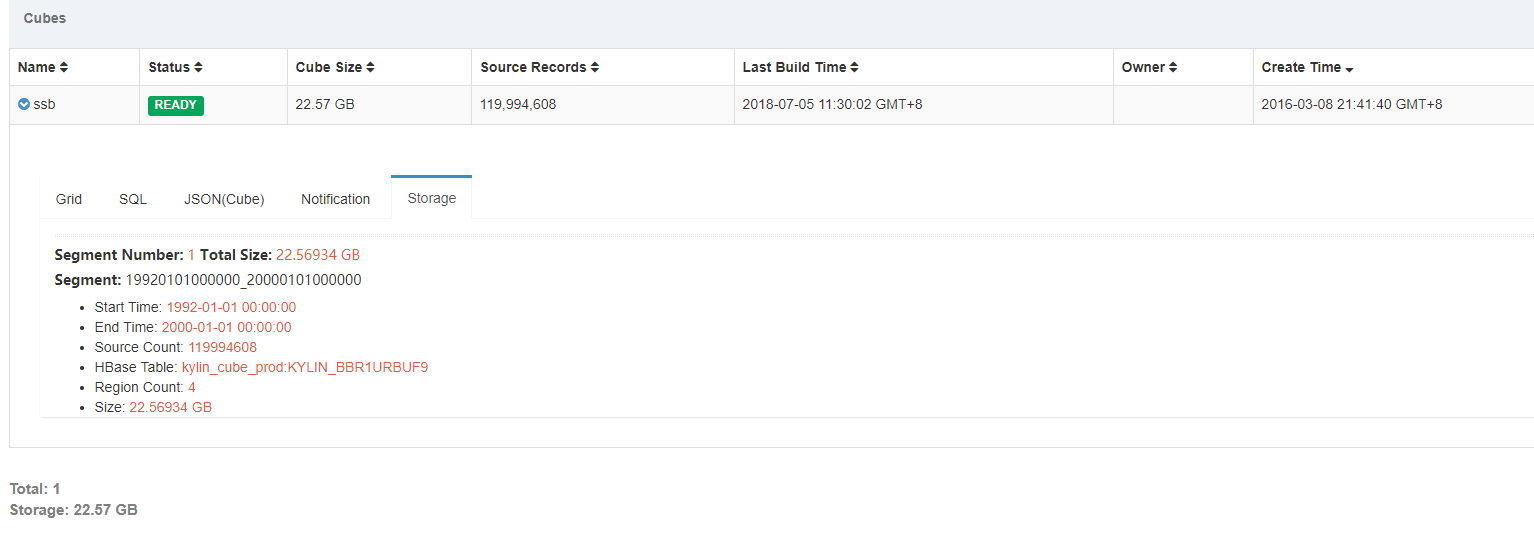
这里我再测试Spark构建Cube性能,将之前创建的Cube Disable,然后再Purge。由于Cube被Purge后,无用的HBase表以及HDFS文件需要删除,这里再手动清理一下垃圾文件,首先执行如下命令:
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false
然后查看列出的HBase表以及HDFS文件是否无用,确定无误后,执行删除操作:
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true
使用Spark构建Cube时,耗用内存还是比较多的,毕竟使用内存资源提升Cube构建速度。这里我将kylin.properties配置文件中对Spark的部分参数列一下:
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.yarn.queue=root.kylin_manager_group
# config Dynamic resource allocation
kylin.engine.spark-conf.spark.dynamicAllocation.enabled=true
kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=10
kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1024
kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.shuffle.service.port=7337
kylin.engine.spark-conf.spark.driver.memory=4G
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.executor.cores=1
kylin.engine.spark-conf.spark.network.timeout=600
kylin.engine.spark-conf.spark.executor.instances=1
上面的参数可以满足绝大部分需求,这样用户在设计Cube时就基本上不用再配置了,当然如果情况比较特殊,依然可以在Cube层面设置Spark相关的调优参数。
在执行Spark构建Cube之前,需要在Advanced Setting中设置Cube Engine值为Spark,然后执行Build。构建完成后结果如下:

对比一下MapReduce和Spark 构建 Cube的时间如下(Scale=20):
可以看到构建速度基本快1倍,其实Spark还有很多其他方面的调优(性能可以提升1-4倍及以上),这里暂不涉及,感兴趣的朋友再交流。
查询
ssb-kylin提供了13个SSB查询SQL列表,查询条件可能随着scale因子不同而不一样,大家根据实际情况修改,下面的例子在scale为10和20情况下的测试结果:
Scale=10的查询结果如下:
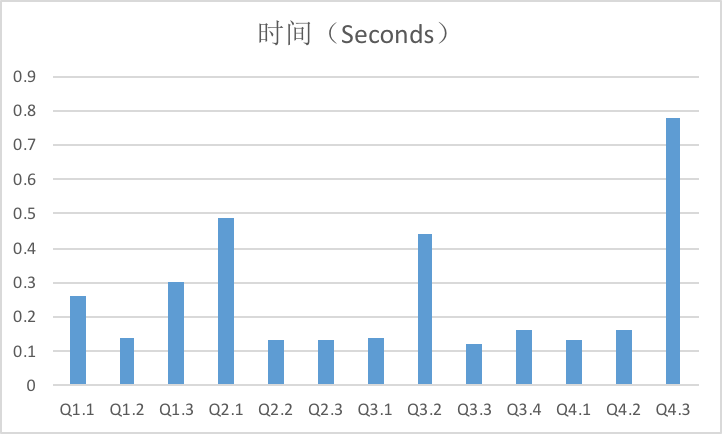
Scale=20的查询结果如下:

从结果中可以看出,所有的查询都在1s以内完成,有力证明了Apache Kylin的亚秒级查询能力。此外,查询平均性能随着数据量的翻倍增加并未显著下降,这也是Cube预计算的理论所决定的。
注:每个查询语句的详细内容请查看ssb-kylin项目中的README.md说明。
到这里,本次Kylin的SSB压测就完成后,但是对于正在看文章的你,一切才刚刚开始。
