所谓“自然语言”,是指人们日常交流使用的语言,如英语、印地语随着不断演化,很难用明确的规则来刻画。
从广义上,“自然语言处理”(Natural Language Processing简称NLP)包含所有计算机对自然语言进行的操作,从最简单的通过计数词出现的频率来比较不同的写作风格到最复杂的完全“理解”人所说的话。
基于NLP的技术应用日益广泛,如手机和手持电脑支持输入法联想提示(predictive text)和手写识别、网络搜索引擎能搜到非结构化文本中的信息、机器翻译能把中文文本翻译成西班牙文等。
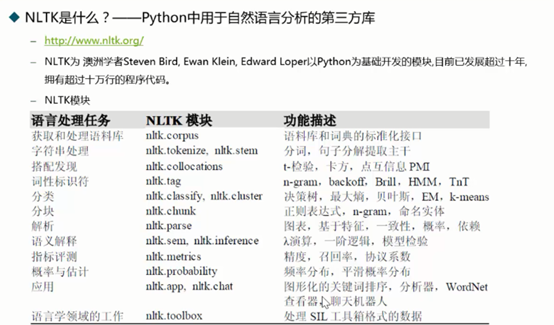
通过使用Python程序设计语言和自然语言工具包(NLTK,Natural Language Toolkit)的开源函数库来讲解自然语言处理的各个技术要点。
本书为什么使用Python呢?
Python是一种简单功能强大的变成语言,非常适合处理语言数据。
作为解释语言,Python便于交互式变成;作为面向对象语言,Python允许数据和方法被方面的封装和重用。作为动态语言,Python允许属性等程序运行时才被添加到对象,允许变量自动类型转换,提高开发效率。Python自带强大的标准库,包括图像编程、数值处理和网络连接等组件。
1.0.2 开发环境搭建
我们选择Anaconda的优势如下:
1).不需要配置PYTHON环境变量;
2).集成很多packages,省去一一下载的麻烦;
3).packages的安装很简单,conda一键解决;
4).可以配置python版本的环境,方便切换,互不干扰,兼容性强!
详细的安装步骤如下:
1.下载Anaconda
https://www.continuum.io/downloads
2.然后一路安装就可以了,自己可以选择安装盘。
安装完之后有这几个程序,看下图
py35是我配置的python3.5的环境
3.打开Anaconda Prompt
依次点击:开始--所有程序--Anaconda这个窗口和doc窗口一样的,输入命令就可以控制和配置python,最常用的是conda命令,这个pip的用法一样,此软件都集成了,你可以直接用,点开的话如下图:

我是Anaconda Prompt
4.然后你可以使用conda命令进行一些包的安装和更新,不要担心,so easy!
conda list
列出所有的已安装的packages
conda install name
name是需要安装packages的名字,比如,我安装numpy包,输入上面的命令就是:
conda install numpy
单词之间空一格,然后回车,输入y就可以了
5.下面就是conda的用法,我不在啰嗦了。
多看几遍你就都会了,英文都是简单的单词----conda的用法
6.python3.5环境配置的介绍
需要用到conda命令行,下面介绍一下命令行,输入之后,耐心等待安装就可以!
首先在Anaconda Prompt直接输入下面命令既可以:
conda create --name py35 python=3
其中py35是环境名字,python=3是我们需要的版本,然后耐心等待整个程序的安装!
然后激活这个环境:
activate py35
下面的第二行Activating environment “c:\Anaconda2”是默认的变量,python2.7版本的!
下面的第五行Activating environment“c:\Anaconda2\envs\py35”是python3.5版本的!
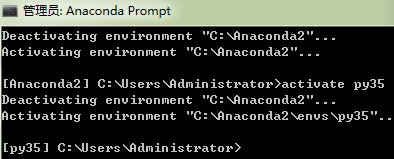
这是我的环境切换
最后同样使用conda命令安装各种packages就可以了。
7.打开AnacondaNavigator,然后点击Environment,root就是我们安装的环境,py35是我后来安装的环境。如下:
右边是已经安装的packages
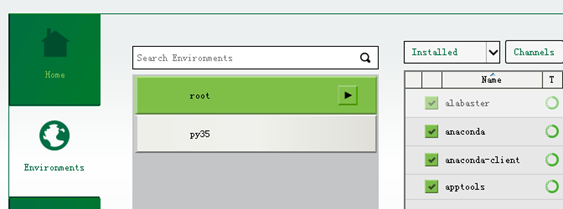
安装完毕之后启动,Anaconda然后输入
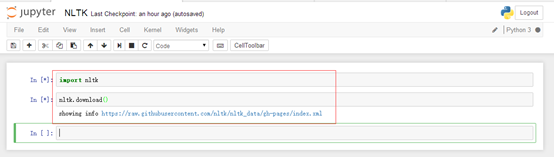
import nltk
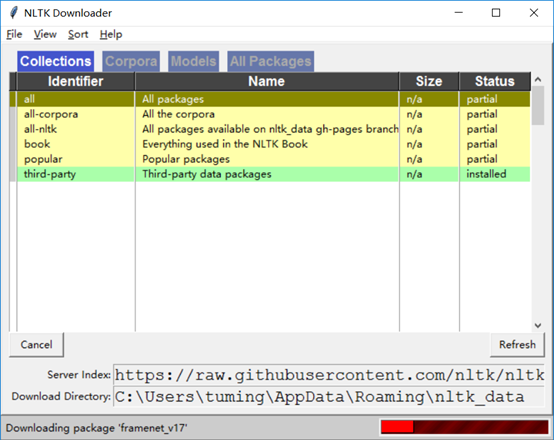
nltk.download()
点击download开始下载语料库
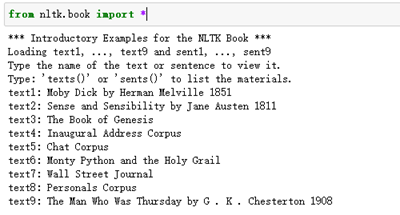
一旦数据被下载到你的机器,你就可以使用Python 解释器加载其中一些。第一步是在
Python 提示符后输入一个特殊的命令,告诉解释器去加载一些我们要用的文本:from nlt
k.book import * 。这条语句是说“从NLTK 的book模块加载所有的东西”。这个boo
k 模块包含你阅读本章所需的所有数据。在输出欢迎信息之后,将会加载几本书的文本(这将需要几秒钟)。下面连同你将看到的输出一起再次列出这条命令,注意拼写和标点符号的正确性,记住不要输入。
下载完成后,可以在Anaconda验证一下下载成功与否:
2.0 NLTK语法解析
基本语法
搜索文本concordance
除了阅读文本之外,还有很多方法可以用来研究文本内容。词语索引视图显示一个指
定单词的每一次出现,连同一些上下文一起显示。下面我们输入text1 后面跟一个点,再
输入函数名concordance,然后将monstrous 放在括号里,来查一下《白鲸记》中的词
monstrous:
>>>text1.concordance("monstrous")
搜索哪些词出现在相似的上下文中
词语索引使我们看到词的上下文。例如:我们看到monstrous 出现的上下文,如the
___ pictures 和the ___ size。还有哪些词出现在相似的上下文中?我们可以通过在被查询的
文本名后添加函数名similar,然后在括号中插入相关的词来查找到。
text1.similar("monstrous")
研究共有2个或者2个以上的词汇的上下文
>>>text2.common_contexts(['monstrous','very'])
a_lucky be_glad am_glad a_prettyis_pretty
计数
首先,让我们以文本中出现的词和标点符号为单位算出文本从头到尾的长度。我们使用
函数len 获取长度,请看在《创世纪》中使用的例子:
>>> len(text3)
44764
《创世纪》有44764 个词和标点符号或者叫“标识符”。一个标识符是表示一个我们想
要放在一组对待的字符序列——如:hairy、his 或者:)——的术语。当我们计数文本中标
识符的个数时,如to be or not to be 这句话,我们计数这些序列出现的次数。因此,我们
的例句中出现了to 和be各两次,or 和not 各一次。然而在例句中只有4 个不同的词。《创世纪》中有多少不同的词?要用Python 来回答这个问题,我们处理问题的方法将稍有改变。
一个文本词汇表只是它用到的标识符的集合,因为在集合中所有重复的元素都只算一个。P
ython 中我们可以使用命令:set(text3)获得text3 的词汇表。当你这样做时,屏幕上的很
多词就会被掠过。现在尝试以下操作:
>>> sorted(set(text3))



